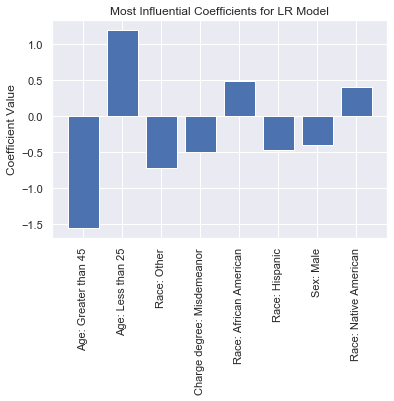
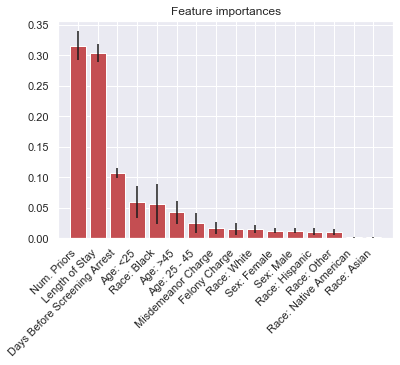
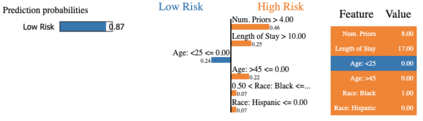
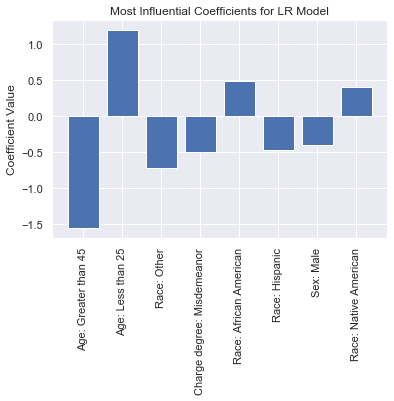
Many ML models are opaque to humans, producing decisions too complex for humans to easily understand. In response, explainable artificial intelligence (XAI) tools that analyze the inner workings of a model have been created. Despite these tools' strength in translating model behavior, critiques have raised concerns about the impact of XAI tools as a tool for `fairwashing` by misleading users into trusting biased or incorrect models. In this paper, we created a framework for evaluating explainable AI tools with respect to their capabilities for detecting and addressing issues of bias and fairness as well as their capacity to communicate these results to their users clearly. We found that despite their capabilities in simplifying and explaining model behavior, many prominent XAI tools lack features that could be critical in detecting bias. Developers can use our framework to suggest modifications needed in their toolkits to reduce issues likes fairwashing.
翻译:许多ML模型对人类而言不透明,产生对人类而言过于复杂的决定,使人难以理解。作为回应,已经创建了可解释的人工智能(XAI)工具来分析模型的内部功能。尽管这些工具在翻译模型行为方面的实力,但批评引起了人们对XAI工具的影响的关切,这种工具是误导用户的“公平洗刷”工具,使其相信有偏见或不正确的模型。在这份文件中,我们建立了一个框架,用于评价可解释的AI工具,这些工具能够发现和解决偏见和公平问题,以及它们向用户明确传达这些结果的能力。我们发现,尽管它们有能力简化和解释模型行为,但许多突出的XAI工具缺乏在发现偏见方面至关重要的特点。开发者可以利用我们的框架,建议对其工具进行所需的修改,以减少像公平洗钱这样的问题。