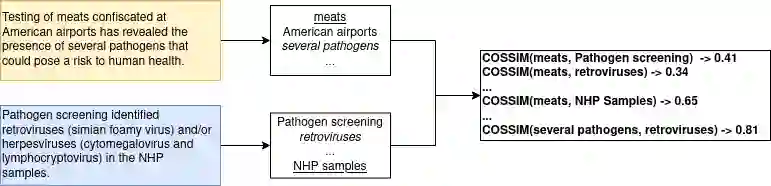
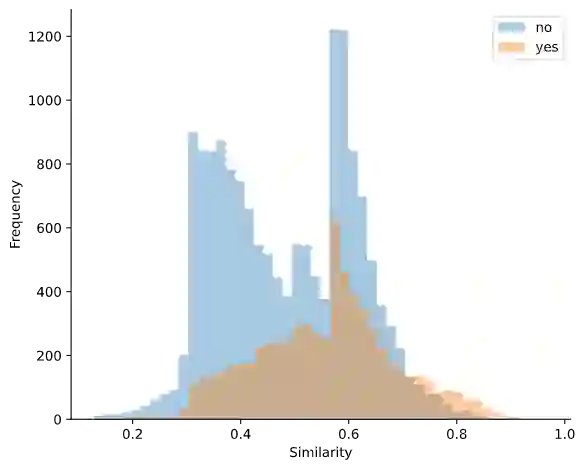
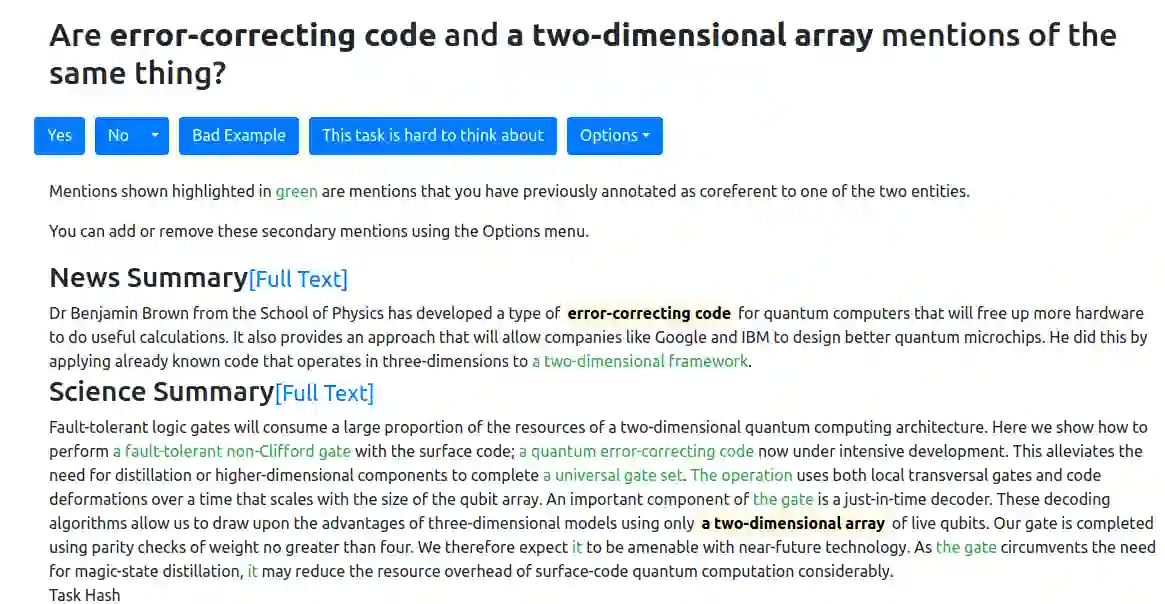
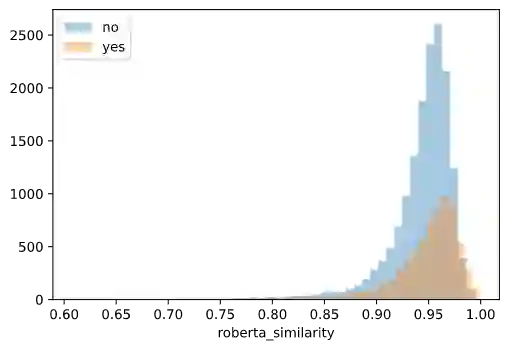
Cross-document co-reference resolution (CDCR) is the task of identifying and linking mentions to entities and concepts across many text documents. Current state-of-the-art models for this task assume that all documents are of the same type (e.g. news articles) or fall under the same theme. However, it is also desirable to perform CDCR across different domains (type or theme). A particular use case we focus on in this paper is the resolution of entities mentioned across scientific work and newspaper articles that discuss them. Identifying the same entities and corresponding concepts in both scientific articles and news can help scientists understand how their work is represented in mainstream media. We propose a new task and English language dataset for cross-document cross-domain co-reference resolution (CD$^2$CR). The task aims to identify links between entities across heterogeneous document types. We show that in this cross-domain, cross-document setting, existing CDCR models do not perform well and we provide a baseline model that outperforms current state-of-the-art CDCR models on CD$^2$CR. Our data set, annotation tool and guidelines as well as our model for cross-document cross-domain co-reference are all supplied as open access open source resources.
翻译:文件交叉参照决议(CDCR)是查明许多文本文件中的实体和概念并将其与这些实体和概念联系起来的任务。目前这一任务的最新模型假定所有文件都属于同一类型(例如,新闻文章)或同一主题之下。然而,在不同的领域(类型或主题)执行CDCR也是可取的。我们本文关注的一个特殊用途案例是跨科学工作和报纸文章提到的实体的决议,讨论它们。在科学文章和新闻中找出相同的实体和相应概念,有助于科学家了解主流媒体如何代表他们的工作。我们为交叉文档跨域共同参考决议提出了新的任务和英语数据集(CD$2$CR)。任务旨在查明不同文件类型实体之间的联系。我们指出,在这个交叉领域,交叉文件设置,现有的CDCR模型效果不佳,我们提供了一个基准模型,它比CDCR目前关于CD=2$CR的先进模型要好得多。我们的数据集、说明工具和指南作为我们开放的进入源交叉参考的模型,作为我们提供的所有开放源的公开参考资源。