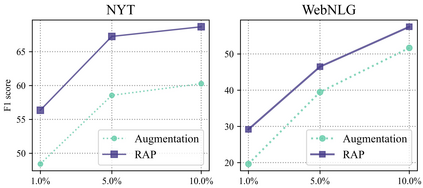
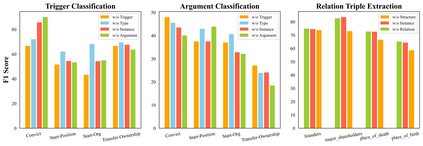
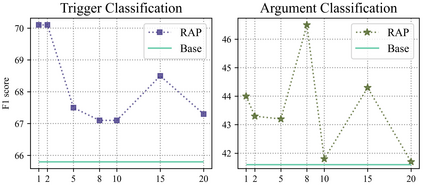
Information Extraction, which aims to extract structural relational triple or event from unstructured texts, often suffers from data scarcity issues. With the development of pre-trained language models, many prompt-based approaches to data-efficient information extraction have been proposed and achieved impressive performance. However, existing prompt learning methods for information extraction are still susceptible to several potential limitations: (i) semantic gap between natural language and output structure knowledge with pre-defined schema; (ii) representation learning with locally individual instances limits the performance given the insufficient features. In this paper, we propose a novel approach of schema-aware Reference As Prompt (RAP), which dynamically leverage schema and knowledge inherited from global (few-shot) training data for each sample. Specifically, we propose a schema-aware reference store, which unifies symbolic schema and relevant textual instances. Then, we employ a dynamic reference integration module to retrieve pertinent knowledge from the datastore as prompts during training and inference. Experimental results demonstrate that RAP can be plugged into various existing models and outperforms baselines in low-resource settings on five datasets of relational triple extraction and event extraction. In addition, we provide comprehensive empirical ablations and case analysis regarding different types and scales of knowledge in order to better understand the mechanisms of RAP. Code is available in https://github.com/zjunlp/RAP.
翻译:旨在从结构化文本中提取结构关系三重或事件外断层的信息提取系统往往缺乏数据。随着培训前语言模型的开发,已经提出并取得了令人印象深刻的绩效,许多基于及时的高效数据信息提取方法,但是,现有的快速信息提取学习方法仍然容易受到若干潜在限制:(一) 自然语言和产出结构知识之间的语义差距,以及预先界定的系统图;(二) 在当地个别实例中进行代表学习,限制了绩效。在本文中,我们建议一种新颖的系统化认知参考“快速查询”方法,该方法能动态地利用从全球(few-shot)样本中获取的系统化和知识。具体地说,我们建议建立一个基于系统化的参考库,将象征性的体系和相关文本实例统一起来。然后,我们使用一个动态的参考集成模块,从数据库中获取相关知识,在培训和推导断过程中,实验结果表明,在低资源环境中,可动态地利用各种模型和从全球(few-shot)培训中获取的知识。我们从五大系统/Rapal 级综合分析中获取的三级数据库。