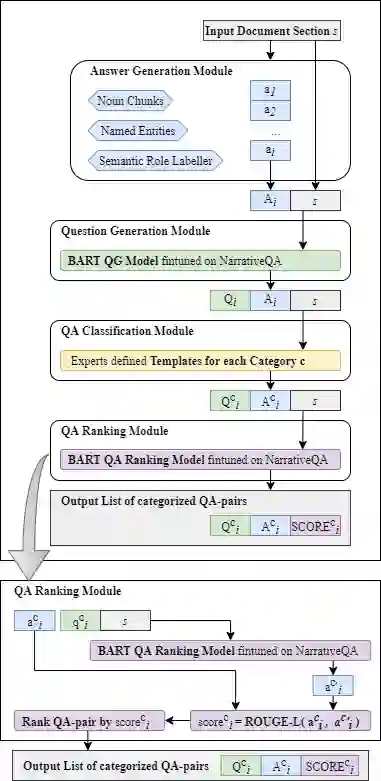
Existing question answering (QA) datasets are created mainly for the application of having AI to be able to answer questions asked by humans. But in educational applications, teachers and parents sometimes may not know what questions they should ask a child that can maximize their language learning results. With a newly released book QA dataset (FairytaleQA), which educational experts labeled on 46 fairytale storybooks for early childhood readers, we developed an automated QA generation model architecture for this novel application. Our model (1) extracts candidate answers from a given storybook passage through carefully designed heuristics based on a pedagogical framework; (2) generates appropriate questions corresponding to each extracted answer using a language model; and, (3) uses another QA model to rank top QA-pairs. Automatic and human evaluations show that our model outperforms baselines. We also demonstrate that our method can help with the scarcity issue of the children's book QA dataset via data augmentation on 200 unlabeled storybooks.
翻译:现有的回答问题数据集(QA)主要是为了应用AI来回答人类提出的问题。但在教育应用中,教师和家长有时可能不知道他们应该向儿童提出什么问题,以最大限度地提高语言学习结果。新发行的一本QA数据集(FairytaleQA)在46本童话童话故事书上贴上了儿童早期阅读者标签,我们为这个新应用开发了一个自动的QA生成模型结构。我们的模型(1)通过根据教学框架精心设计的故事书解答,从某个故事书解答中提取了候选答案;(2)用语言模型生成了与每个提取的答案相应的适当问题;(3)用另一种QA模型来排位最高QA-pairs。自动和人类评估显示,我们的模型超越了基线。我们还表明,我们的方法可以通过200本无标签故事书的数据扩增来帮助解决儿童书QA数据集的稀缺问题。