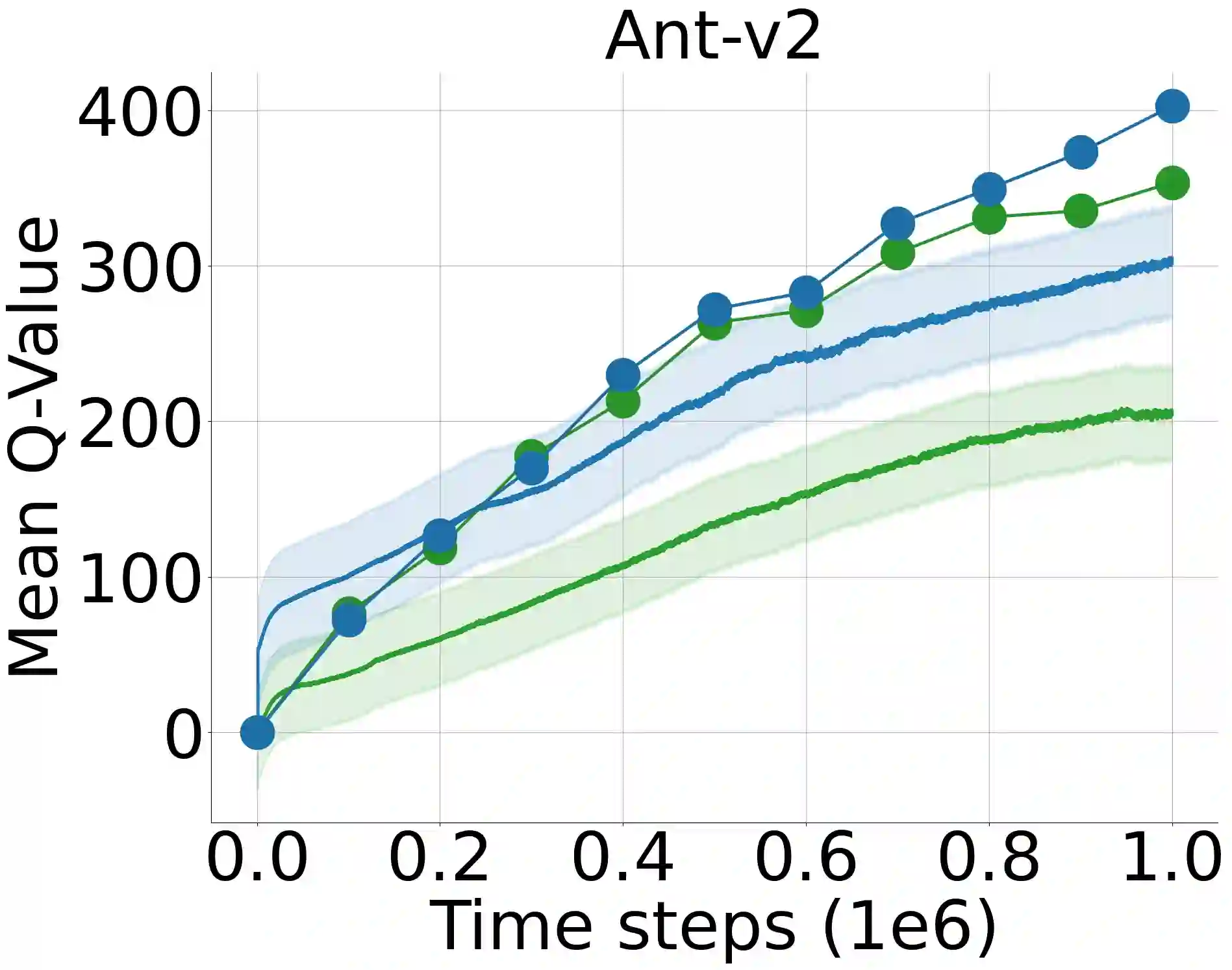
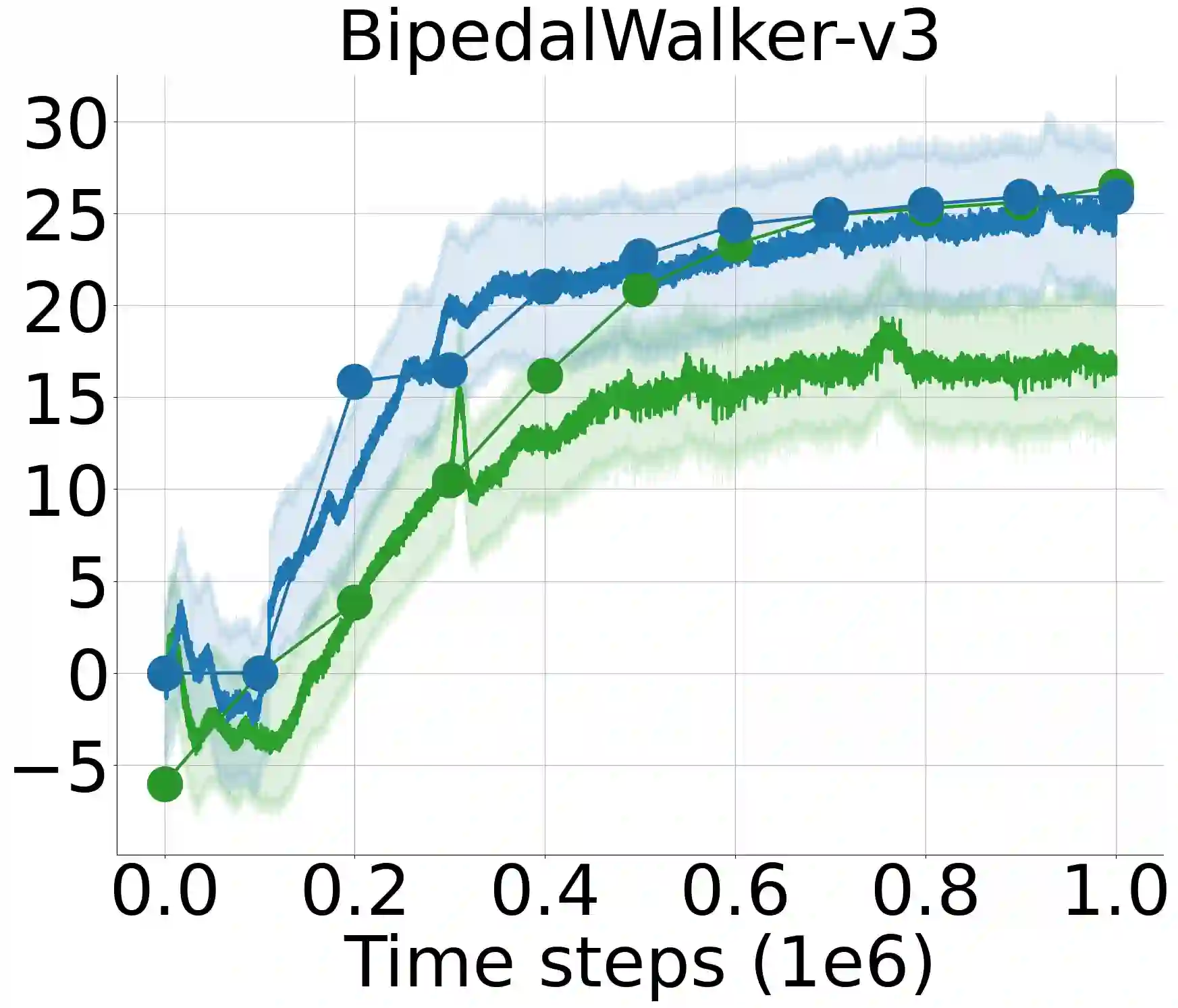
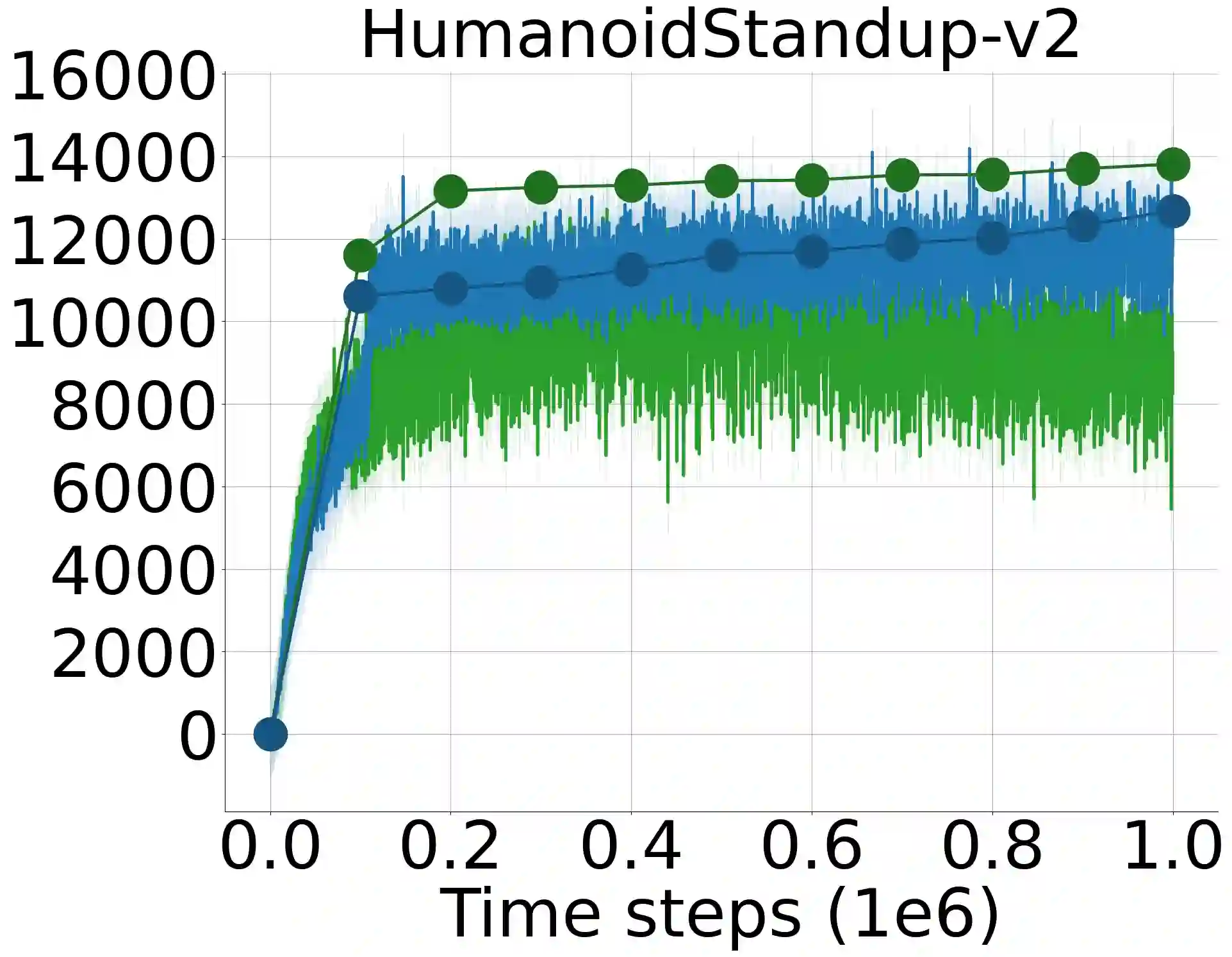
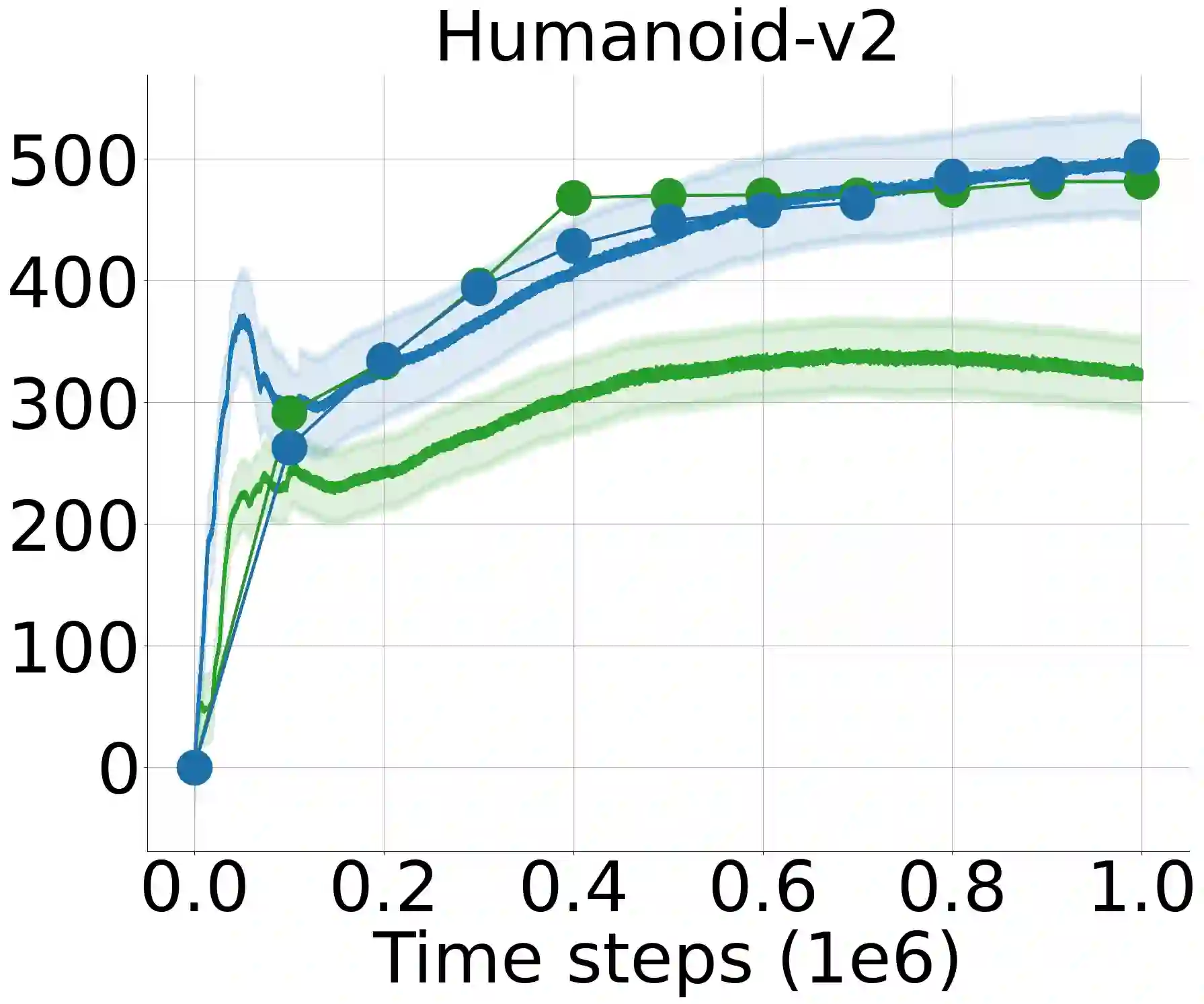
Approximation of the value functions in value-based deep reinforcement learning induces overestimation bias, resulting in suboptimal policies. We show that when the reinforcement signals received by the agents have a high variance, deep actor-critic approaches that overcome the overestimation bias lead to a substantial underestimation bias. We first address the detrimental issues in the existing approaches that aim to overcome such underestimation error. Then, through extensive statistical analysis, we introduce a novel, parameter-free Deep Q-learning variant to reduce this underestimation bias in deterministic policy gradients. By sampling the weights of a linear combination of two approximate critics from a highly shrunk estimation bias interval, our Q-value update rule is not affected by the variance of the rewards received by the agents throughout learning. We test the performance of the introduced improvement on a set of MuJoCo and Box2D continuous control tasks and demonstrate that it considerably outperforms the existing approaches and improves the state-of-the-art by a significant margin.
翻译:在基于价值的深强化学习中,对价值值值值功能的接近性表示估计偏差,导致政策不够优化。我们表明,当代理人收到的加固信号差异很大时,克服高估偏差的深行为者-批评性办法导致严重低估偏差。我们首先处理旨在克服这种低估错误的现有办法中的有害问题。然后,通过广泛的统计分析,我们引入了一个新的、无参数的深Q学习变式,以减少确定性政策梯度中的这种低估性偏差。通过从高度缩水估计偏差的间隔区抽取两个近似批评者的线性组合的重量,我们的 " 价值更新规则 " 不受代理人在整个学习期间得到的奖励差异的影响。我们测试一套MuJoCo和Box2D连续控制任务中引入的改进的绩效,并表明它大大超越了现有办法,大大改进了艺术现状。