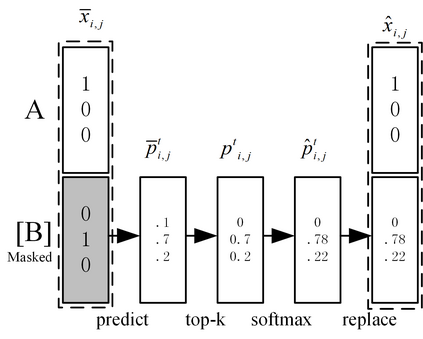
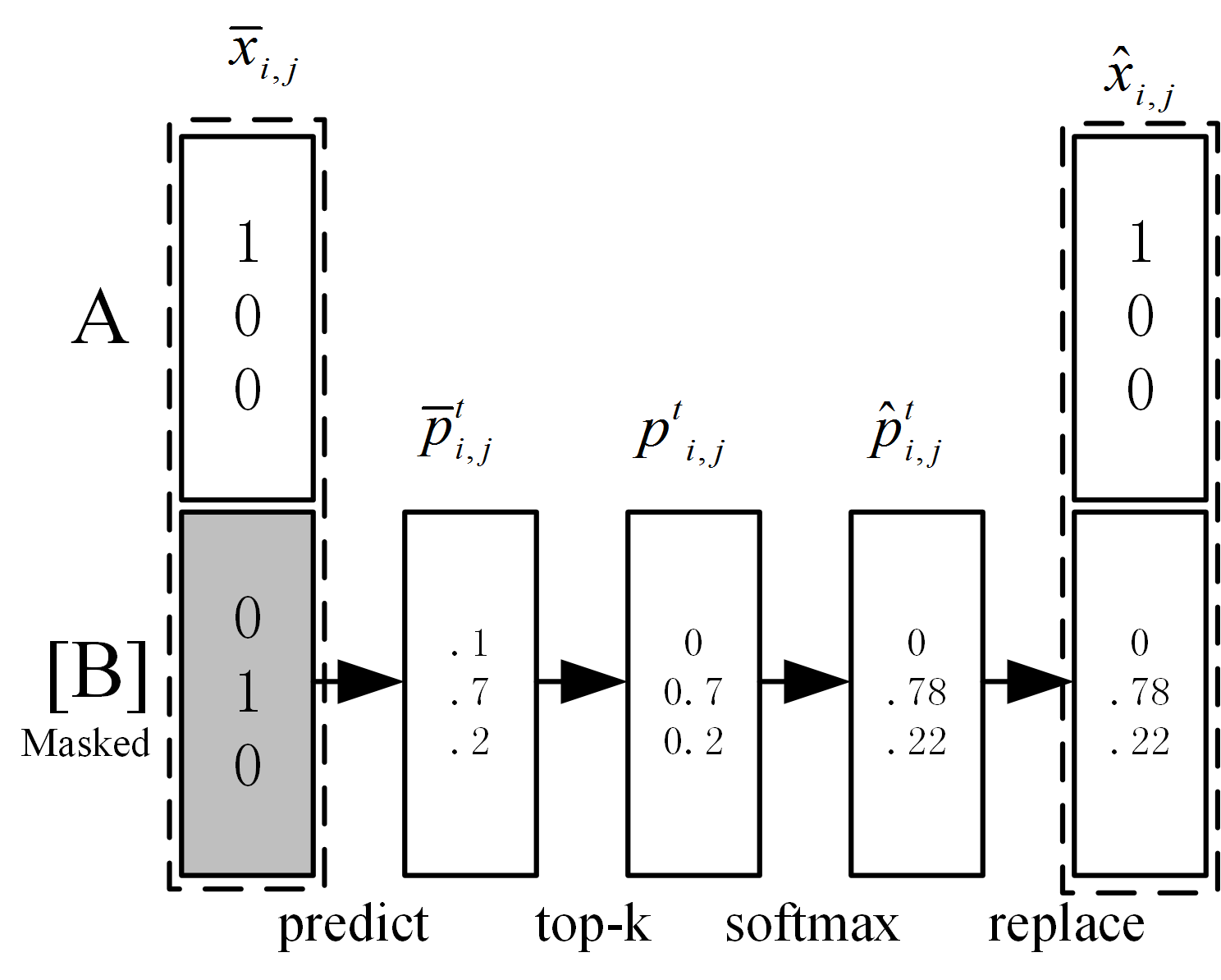
Data augmentation (DA) aims to generate constrained and diversified data to improve classifiers in Low-Resource Classification (LRC). Previous studies mostly use a fine-tuned Language Model (LM) to strengthen the constraints but ignore the fact that the potential of diversity could improve the effectiveness of generated data. In LRC, strong constraints but weak diversity in DA result in the poor generalization ability of classifiers. To address this dilemma, we propose a {D}iversity-{E}nhanced and {C}onstraints-\{R}elaxed {A}ugmentation (DECRA). Our DECRA has two essential components on top of a transformer-based backbone model. 1) A k-beta augmentation, an essential component of DECRA, is proposed to enhance the diversity in generating constrained data. It expands the changing scope and improves the degree of complexity of the generated data. 2) A masked language model loss, instead of fine-tuning, is used as a regularization. It relaxes constraints so that the classifier can be trained with more scattered generated data. The combination of these two components generates data that can reach or approach category boundaries and hence help the classifier generalize better. We evaluate our DECRA on three public benchmark datasets under low-resource settings. Extensive experiments demonstrate that our DECRA outperforms state-of-the-art approaches by 3.8% in the overall score.
翻译:数据增强(DA)的目的是产生限制和多样化的数据,以改进低源分类中的分类。以往的研究大多使用微调的语言模式(LM)来加强限制,但忽视多样性的潜力可以提高生成数据的有效性这一事实。在LRC, 强大的限制但DA多样性薄弱,导致分类者普遍化能力差。为了解决这一难题,我们建议使用一个{D}niversity-{E}加强和{C}限制 放松 {A} 增强。我们的DERA(DERC)在基于变压器的骨架模型(LM)之上有两个基本组成部分。 (1) 增强 k-beta,这是DECRA的一个基本组成部分,目的是加强生成受限制数据的多样性。它扩大了变化的范围,提高了生成数据的复杂性程度。 (2) 使用隐蔽的语言模式损失,而不是微调,作为正规化。它放松了限制,以便分类者能够用更分散的生成数据来培训。 这两种组成部分的组合,是DECR(DER)的一个基本组成部分,这是DERA)一个基本的分类方法,我们可以在三个类别下进行更精确的排序。