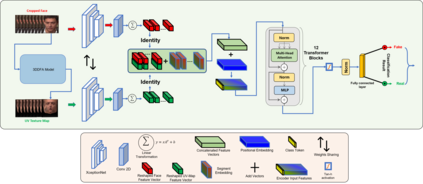
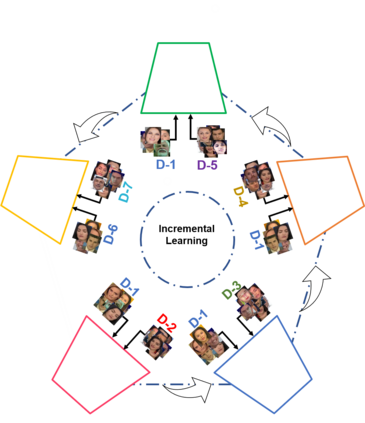
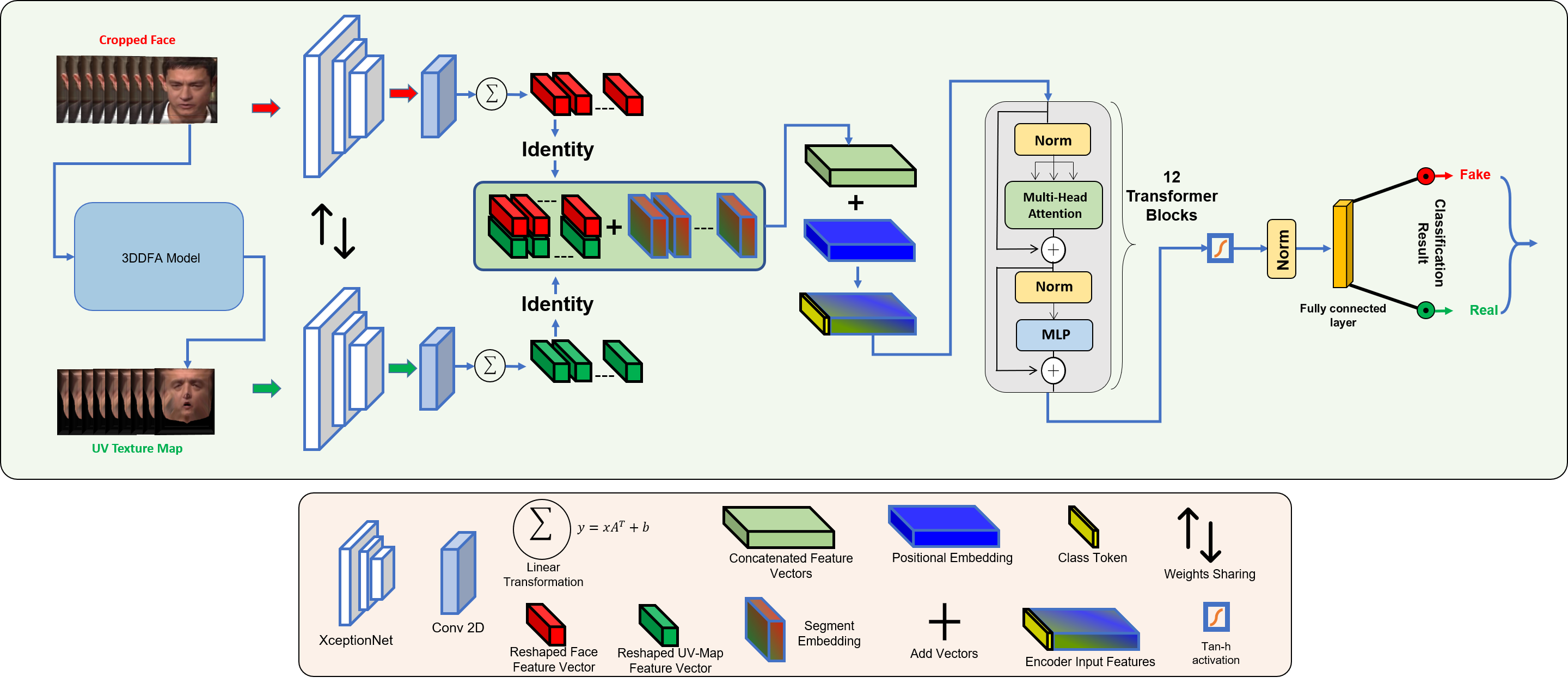
Face forgery by deepfake is widely spread over the internet and this raises severe societal concerns. In this paper, we propose a novel video transformer with incremental learning for detecting deepfake videos. To better align the input face images, we use a 3D face reconstruction method to generate UV texture from a single input face image. The aligned face image can also provide pose, eyes blink and mouth movement information that cannot be perceived in the UV texture image, so we use both face images and their UV texture maps to extract the image features. We present an incremental learning strategy to fine-tune the proposed model on a smaller amount of data and achieve better deepfake detection performance. The comprehensive experiments on various public deepfake datasets demonstrate that the proposed video transformer model with incremental learning achieves state-of-the-art performance in the deepfake video detection task with enhanced feature learning from the sequenced data.
翻译:由深假伪造的脸部在互联网上广为传播,这引起了严重的社会关注。 在本文中, 我们提出一个新的视频变压器, 以渐进学习方式探测深假视频。 为了更好地对输入面图像进行匹配, 我们使用三维面部重建方法从一个输入面部图像中生成紫外线纹理。 匹配面部图像还可以提供在紫外线纹理图像中无法看到的面部、 眼睛眨眼和口部移动信息, 因此我们使用面部图像及其紫外线纹理图来提取图像特征。 我们提出了一个递增学习策略, 以微调拟议模型的少量数据, 并取得更好的深假探测性能。 对各种公共深假数据集的全面实验表明, 包含渐进学习的视频变压器模型在深假视频探测任务中取得了最新表现, 并且从序列数据中强化了特征学习。