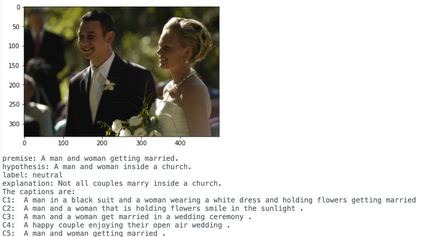
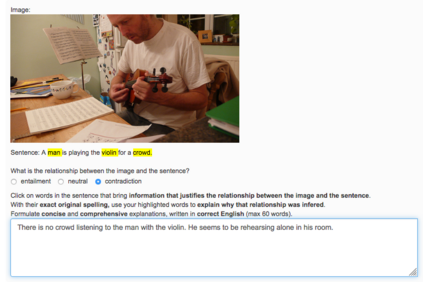
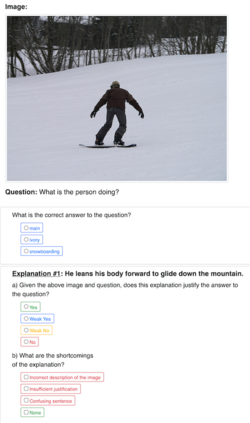
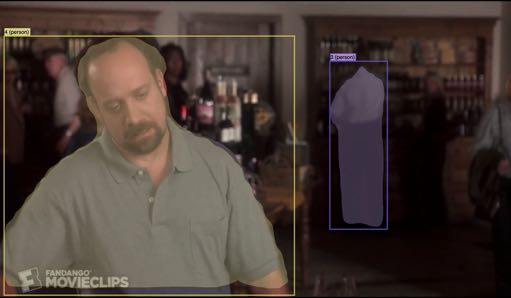
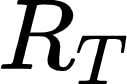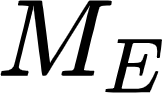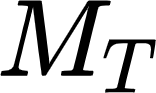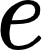Recently, there has been an increasing number of efforts to introduce models capable of generating natural language explanations (NLEs) for their predictions on vision-language (VL) tasks. Such models are appealing, because they can provide human-friendly and comprehensive explanations. However, there is a lack of comparison between existing methods, which is due to a lack of re-usable evaluation frameworks and a scarcity of datasets. In this work, we introduce e-ViL and e-SNLI-VE. e-ViL is a benchmark for explainable vision-language tasks that establishes a unified evaluation framework and provides the first comprehensive comparison of existing approaches that generate NLEs for VL tasks. It spans four models and three datasets and both automatic metrics and human evaluation are used to assess model-generated explanations. e-SNLI-VE is currently the largest existing VL dataset with NLEs (over 430k instances). We also propose a new model that combines UNITER, which learns joint embeddings of images and text, and GPT-2, a pre-trained language model that is well-suited for text generation. It surpasses the previous state of the art by a large margin across all datasets. Code and data are available here: https://github.com/maximek3/e-ViL.
翻译:最近,为引入能够产生自然语言解释的模型(NLEs)来预测视觉语言任务(VL),最近做出了越来越多的努力,以引入能够产生自然语言解释的模型(NLEs),这些模型具有吸引力,因为它们能够提供人类友好和全面的解释;然而,由于缺少可再使用的评价框架和数据集稀缺,现有方法之间缺乏可比性。在这项工作中,我们引入了e-Vil和e-SNLI-VE。e-VIL(e-VI)是可解释的愿景语言任务的基准,可以建立一个统一的评价框架,并对现有方法进行第一次综合比较,为VLL任务产生NLEs。这些模型跨越了四个模型和三个数据集,自动指标和人类评价用于评估模型的解释。e-SNLIL-VE(e-SNLI-VE)是目前与NLES(超过430k实例)最大的VL数据集。我们还提出了一个新的模型,将UNITER(即学习图像和文本联合嵌入)和GPT-2(GPT)结合起来,一个经过事先培训的语言模型,可用于文本生成的模型,可以很好地用于生成文本数据。它超越了M/VIRCmaxium/VI)所有版本的数据。