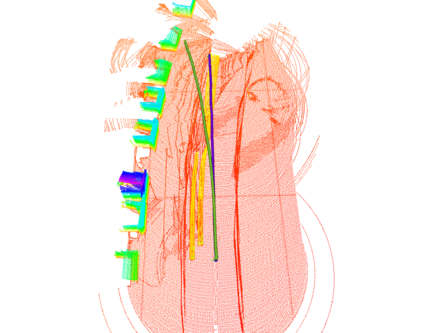
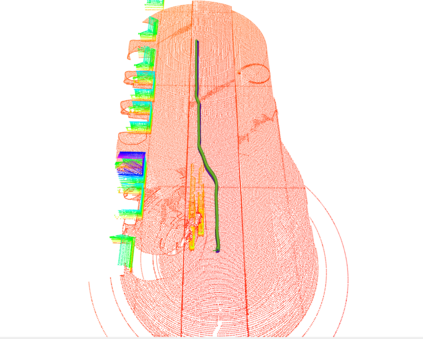
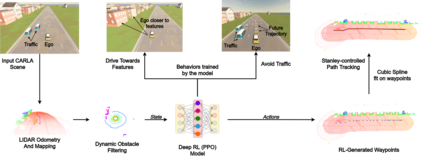
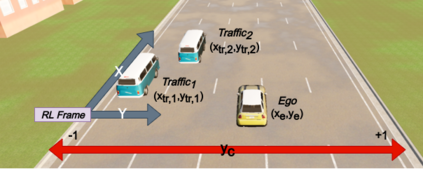
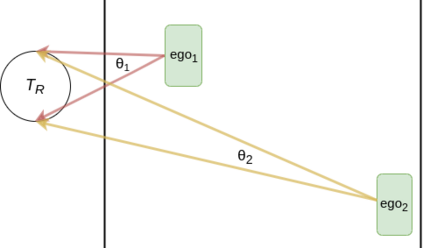
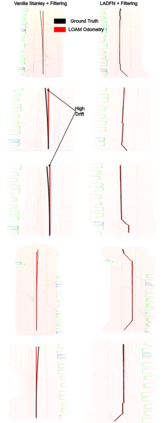
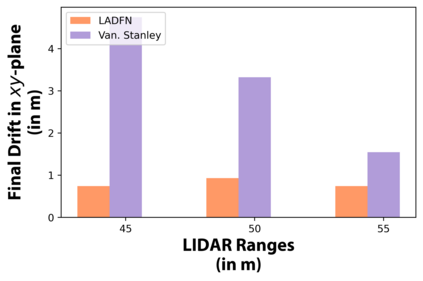
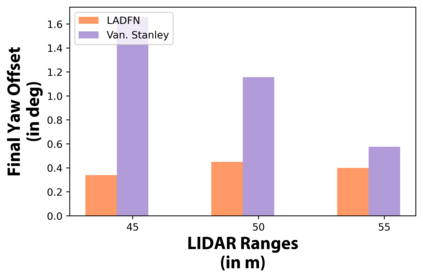
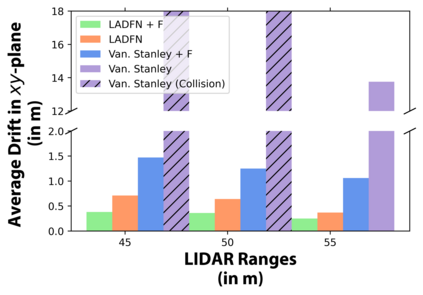
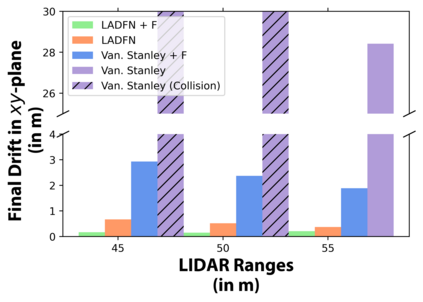
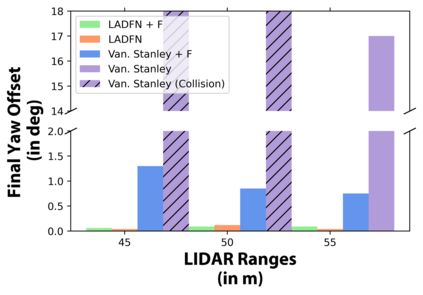
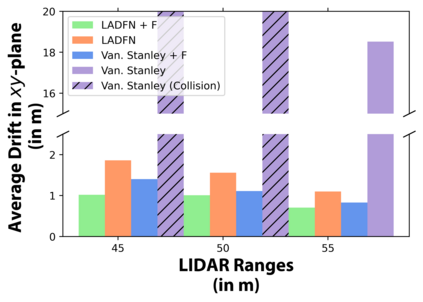
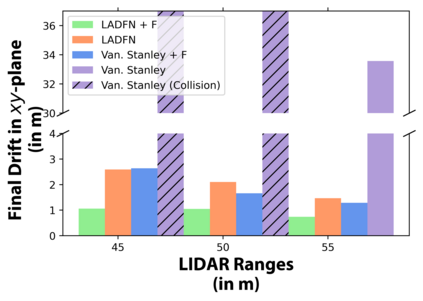
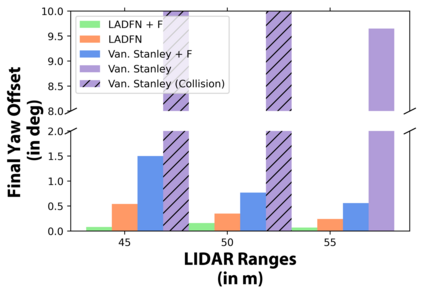
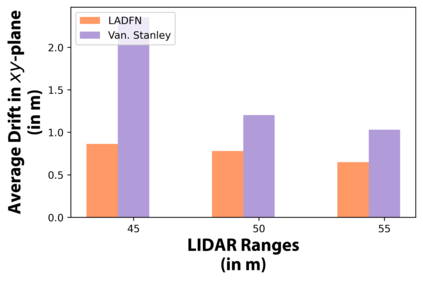
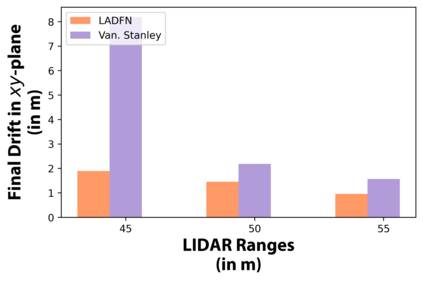
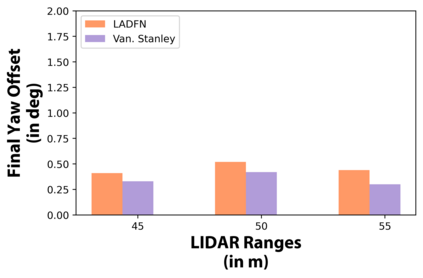
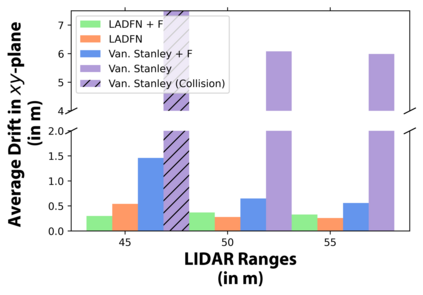
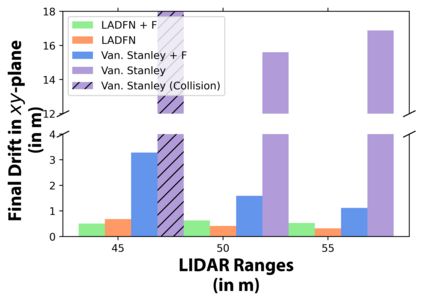
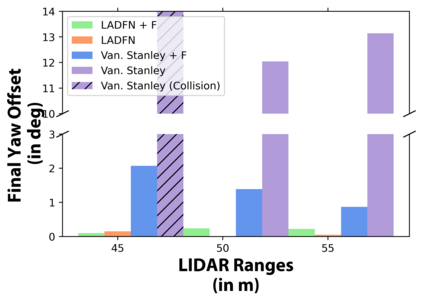
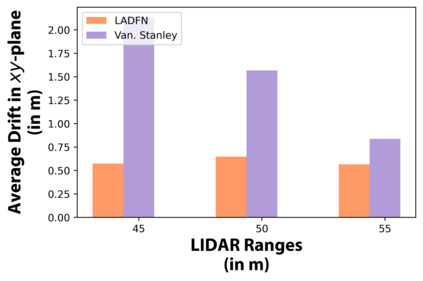
We embark on a hitherto unreported problem of an autonomous robot (self-driving car) navigating in dynamic scenes in a manner that reduces its localization error and eventual cumulative drift or Absolute Trajectory Error, which is pronounced in such dynamic scenes. With the hugely popular Velodyne-16 3D LIDAR as the main sensing modality, and the accurate LIDAR-based Localization and Mapping algorithm, LOAM, as the state estimation framework, we show that in the absence of a navigation policy, drift rapidly accumulates in the presence of moving objects. To overcome this, we learn actions that lead to drift-minimized navigation through a suitable set of reward and penalty functions. We use Proximal Policy Optimization, a class of Deep Reinforcement Learning methods, to learn the actions that result in drift-minimized trajectories. We show by extensive comparisons on a variety of synthetic, yet photo-realistic scenes made available through the CARLA Simulator the superior performance of the proposed framework vis-a-vis methods that do not adopt such policies.
翻译:我们着手处理一个迄今未报告的自主机器人(自驾驶车)在动态场景中航行的问题,以减少其定位错误和最终的累积性漂移或绝对轨迹错误,这在动态场景中已经显露出来。以极受欢迎的Velodyne-16 3D LIDAR作为主要感知模式,以及精确的LIDAR定位和绘图算法,作为国家估计框架,LOAM显示,在没有导航政策的情况下,在移动物体面前迅速漂移。要克服这一点,我们通过一套适当的奖赏和惩罚功能,学习导致漂移最小化的导航的行动。我们使用一种深强化学习方法,即Proximal政策优化,以学习导致漂移最小化轨迹的行动。我们通过对通过CARLA模拟器提供的合成的、但具有照片现实性的场景进行广泛比较,展示了拟议框架优于不采用这种政策的方法的优异性。