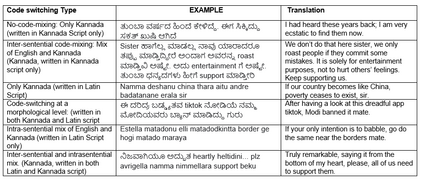
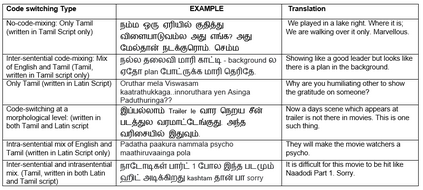
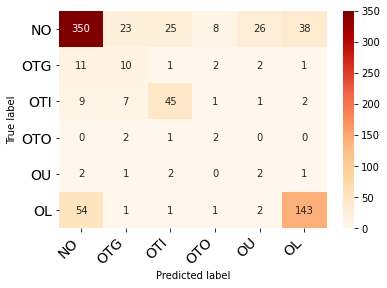
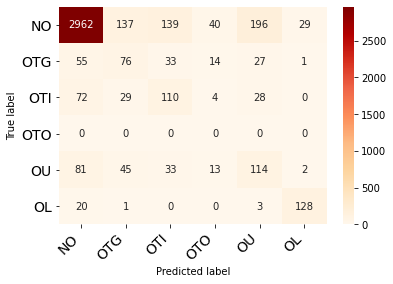
Social media has effectively become the prime hub of communication and digital marketing. As these platforms enable the free manifestation of thoughts and facts in text, images and video, there is an extensive need to screen them to protect individuals and groups from offensive content targeted at them. Our work intends to classify codemixed social media comments/posts in the Dravidian languages of Tamil, Kannada, and Malayalam. We intend to improve offensive language identification by generating pseudo-labels on the dataset. A custom dataset is constructed by transliterating all the code-mixed texts into the respective Dravidian language, either Kannada, Malayalam, or Tamil and then generating pseudo-labels for the transliterated dataset. The two datasets are combined using the generated pseudo-labels to create a custom dataset called CMTRA. As Dravidian languages are under-resourced, our approach increases the amount of training data for the language models. We fine-tune several recent pretrained language models on the newly constructed dataset. We extract the pretrained language embeddings and pass them onto recurrent neural networks. We observe that fine-tuning ULMFiT on the custom dataset yields the best results on the code-mixed test sets of all three languages. Our approach yields the best results among the benchmarked models on Tamil-English, achieving a weighted F1-Score of 0.7934 while scoring competitive weighted F1-Scores of 0.9624 and 0.7306 on the code-mixed test sets of Malayalam-English and Kannada-English, respectively.
翻译:社交媒体已有效地成为通信和数字营销的主要枢纽。这些平台使得思想和事实能够自由体现在文本、图像和视频中,因此广泛需要筛选这些平台,以保护个人和群体免受针对他们的冒犯内容。我们的工作打算对泰米尔语、卡纳达语和马拉亚拉姆语Dravidian语的代码化社会媒体评论/日志进行分类。我们打算通过在数据集上制作假标签来改进冒犯性语言识别。一个定制数据集是通过将所有代码混合文本转换成德拉维迪亚语(Kannada、Malayalam语或泰米尔语),然后为转写数据集制作假标签。两套数据集将使用生成的假标签来创建名为CMTRA的定制数据集。由于Dravidian语资源不足,我们的方法将增加语言模型的培训数据数量。在新构建的数据集上将62种最新的未经训练的语言模型转换为Kandaladal6, 然后将它们传送到经常的兰语言网络上。我们观察到,两个数据集将使用生成的假的假的伪标签,同时将测试我们所有正标定的Real-Ral-BR8S 的标标码 。