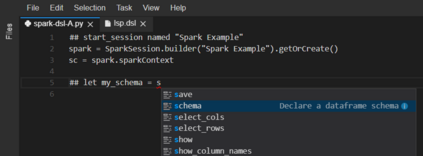
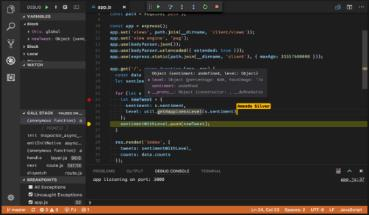
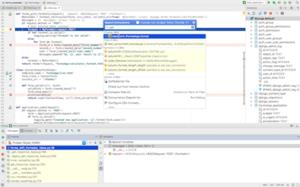
Data analysis is at the core of scientific studies, a prominent task that researchers and practitioners typically undertake by programming their own set of automated scripts. While there is no shortage of tools and languages available for designing data analysis pipelines, users spend substantial effort in learning the specifics of such languages/tools and often design solutions too project specific to be reused in future studies. Furthermore, users need to put further effort into making their code scalable, as parallel implementations are typically more complex. We address these problems by proposing an advanced code recommendation tool which facilitates developing data science scripts. Users formulate their intentions in a human-readable Domain Specific Language (DSL) for dataframe manipulation and analysis. The DSL statements can be converted into executable Python code during editing. To avoid the need to learn the DSL and increase user-friendliness, our tool supports code completion in mainstream IDEs and editors. Moreover, DSL statements can generate executable code for different data analysis frameworks (currently we support Pandas and PySpark). Overall, our approach attempts to accelerate programming of common data analysis tasks and to facilitate the conversion of the implementations between frameworks. In a preliminary assessment based on a popular data processing tutorial, our tool was able to fully cover 9 out of 14 processing steps for Pandas and 10 out of 16 for PySpark, while partially covering 4 processing steps for each of the frameworks.
翻译:科学研究的核心是数据分析,这是研究人员和从业人员通常通过编程自己的一套自动化脚本来完成的突出任务。虽然设计数据分析管道的工具和语言并不短缺,但用户花大量精力去学习这类语言/工具的具体细节,而且往往设计项目过于具体,无法在今后的研究中再利用的解决方案。此外,用户需要进一步努力使其代码可缩放,因为平行执行通常比较复杂。我们通过提出一个先进的代码建议工具来解决这些问题,便利数据科学脚本的开发。用户在用于数据框架操作和分析的人类可读域特定语言(DSL)中提出他们的意图。DSL的语句可以在编辑过程中转换成可执行的 Python 代码。为了避免需要学习 DSL,提高用户的友好性,我们的工具需要支持主流 IDEs 和编辑完成代码。此外,DSLS 的语句可以产生可执行的代码(目前我们支持 Pandas 和 PySpark ) 。总的来说,我们试图加快共同数据分析任务的编程,并便利PyS 10级框架的初步处理工具框架的每个阶段。