
A seminal work [Jacot et al., 2018] demonstrated that training a neural network under specific parameterization is equivalent to performing a particular kernel method as width goes to infinity. This equivalence opened a promising direction for applying the results of the rich literature on kernel methods to neural nets which were much harder to tackle. The present survey covers key results on kernel convergence as width goes to infinity, finite-width corrections, applications, and a discussion of the limitations of the corresponding method.
翻译:一项开创性工作[Jacot等人,2018年]表明,在特定参数化下培训神经网络相当于在宽度达到无限度时采用特定的内核方法,这一等值为将关于内核方法的丰富文献结果应用于神经网打开了一个大有希望的方向,而神经网很难解决。









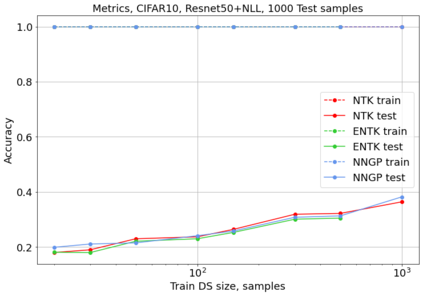
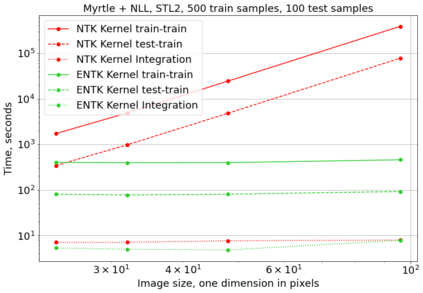
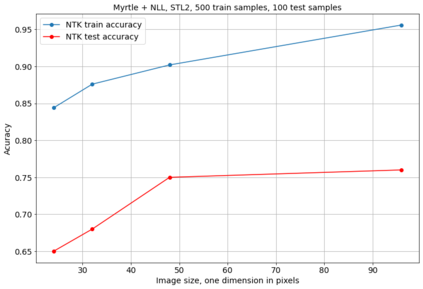

相关内容

专知会员服务
78+阅读 · 2022年3月15日
Arxiv
0+阅读 · 2022年10月13日
Arxiv
23+阅读 · 2021年9月29日

相关VIP内容
专知会员服务
78+阅读 · 2022年3月15日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年10月13日
Arxiv
23+阅读 · 2021年9月29日