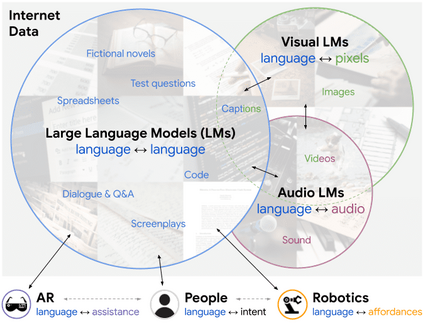
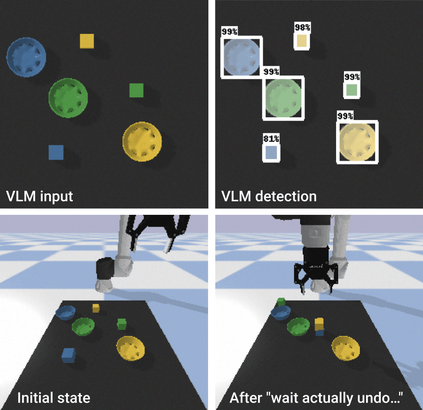
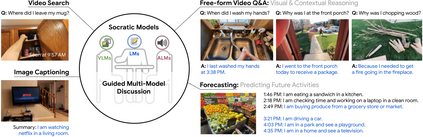
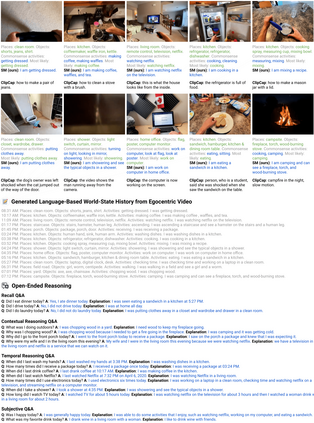
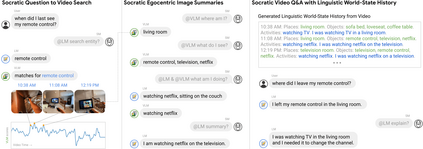
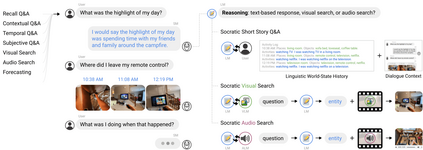
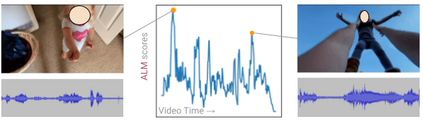
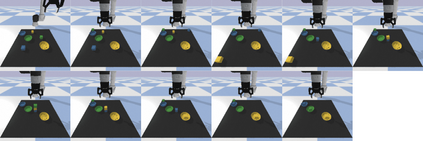
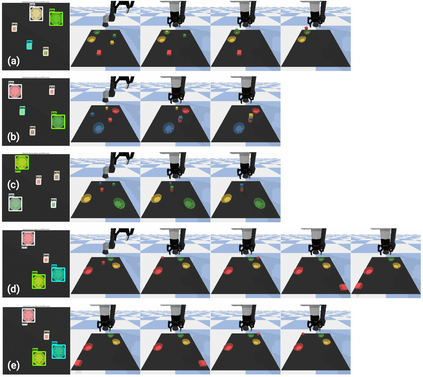
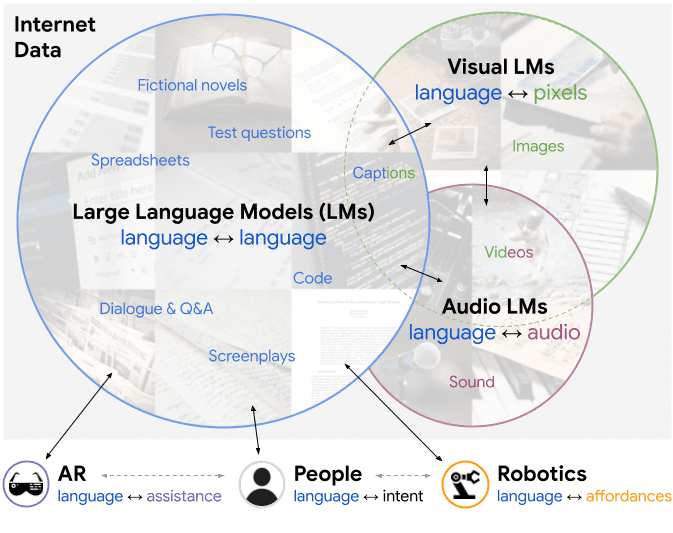
Large pretrained (e.g., "foundation") models exhibit distinct capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g., spreadsheets, SAT questions, code). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this diversity is symbiotic, and can be leveraged through Socratic Models (SMs): a modular framework in which multiple pretrained models may be composed zero-shot i.e., via multimodal-informed prompting, to exchange information with each other and capture new multimodal capabilities, without requiring finetuning. With minimal engineering, SMs are not only competitive with state-of-the-art zero-shot image captioning and video-to-text retrieval, but also enable new applications such as (i) answering free-form questions about egocentric video, (ii) engaging in multimodal assistive dialogue with people (e.g., for cooking recipes) by interfacing with external APIs and databases (e.g., web search), and (iii) robot perception and planning.
翻译:例如,视觉语言模型(VLMs)在互联网规模的图像说明上接受培训,但大型语言模型(LMs)在互联网规模的文本上经过进一步培训,没有图像(例如电子表格、SAT问题、代码)。因此,这些模型储存了不同领域的不同形式的普通知识。在这项工作中,我们显示这种多样性是共生的,可以通过Scrotic 模型加以利用:一个模块框架,在这个框架中,多种预先培训的模型可以组成零弹式的,例如,通过多式知情的提示,相互交流信息,并获取新的多式联运能力,而不需要微调。在工程上,SMMMS不仅与最先进的零光图像说明和视频到文字检索相竞争,而且还能够进行新的应用,例如(i)回答关于自我中心视频和视频模型的自由形式问题,(ii)与外部搜索(ii)与主机数据库、(c)与外部搜索、(idrod)对话,(i)与外部搜索(i),与A.(i)和Odrodal-deal 进行(i)。