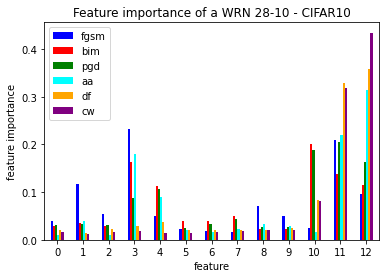
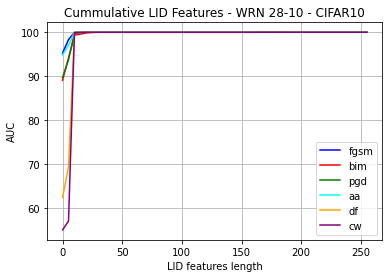
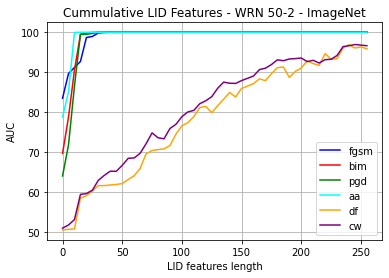
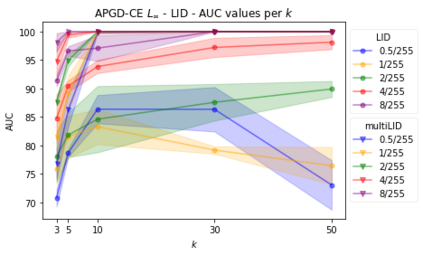
Convolutional neural networks (CNN) define the state-of-the-art solution on many perceptual tasks. However, current CNN approaches largely remain vulnerable against adversarial perturbations of the input that have been crafted specifically to fool the system while being quasi-imperceptible to the human eye. In recent years, various approaches have been proposed to defend CNNs against such attacks, for example by model hardening or by adding explicit defence mechanisms. Thereby, a small "detector" is included in the network and trained on the binary classification task of distinguishing genuine data from data containing adversarial perturbations. In this work, we propose a simple and light-weight detector, which leverages recent findings on the relation between networks' local intrinsic dimensionality (LID) and adversarial attacks. Based on a re-interpretation of the LID measure and several simple adaptations, we surpass the state-of-the-art on adversarial detection by a significant margin and reach almost perfect results in terms of F1-score for several networks and datasets. Sources available at: https://github.com/adverML/multiLID
翻译:然而,目前的CNN方法在很大程度上仍然容易受到对抗性干扰,因为专门为愚弄该系统而设计的、对人类来说几乎是不可理解的输入系统。近年来,提出了各种保护CNN不受这种攻击的方法,例如通过模型加硬或增加明确的防御机制来保护CNN。因此,网络中包括了一个小型的“检测器”,并对它进行了关于区分真实数据与含有对抗性扰动的数据之间的二元分类任务的培训。在这项工作中,我们提议了一个简单和轻量级的检测器,利用最近关于网络的本地内在维度和对抗性攻击之间的关系的调查结果。根据对LID措施的重新解释和若干简单的调整,我们超越了关于对抗性检测的先进技术,以显著的幅度,并在若干网络和数据集的F1-核心方面达到了几乎完美的结果。资料来源:https://github.com/adverMLMLML/mol/mol。可查到:https://github.com/groundLMLMLML。