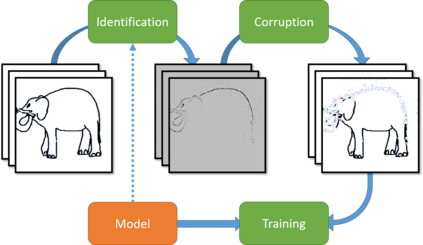
Machine learning models that can generalize to unseen domains are essential when applied in real-world scenarios involving strong domain shifts. We address the challenging domain generalization (DG) problem, where a model trained on a set of source domains is expected to generalize well in unseen domains without any exposure to their data. The main challenge of DG is that the features learned from the source domains are not necessarily present in the unseen target domains, leading to performance deterioration. We assume that learning a richer set of features is crucial to improve the transfer to a wider set of unknown domains. For this reason, we propose COLUMBUS, a method that enforces new feature discovery via a targeted corruption of the most relevant input and multi-level representations of the data. We conduct an extensive empirical evaluation to demonstrate the effectiveness of the proposed approach which achieves new state-of-the-art results by outperforming 18 DG algorithms on multiple DG benchmark datasets in the DomainBed framework.
翻译:当在涉及强度域变换的现实世界情景中应用可推广到隐蔽域的机器学习模型时,至关重要的是要将其推广到隐蔽域中。 我们解决了具有挑战性的域通用(DG)问题,在这个问题上,一组源域培训的模型可望在不接触其数据的情况下在隐蔽域中广泛推广。 DG的主要挑战在于,从源域中学习的特征不一定存在于无形目标域中,导致性能退化。 我们假设,学习一套较丰富的特征对于改进向更广大的未知域的转移至关重要。 为此,我们提议COLUMBUS, 这是一种通过对数据最相关的投入和多层次的表达方式进行有针对性的腐败来实施新特征发现的方法。 我们进行了广泛的实证评估,以展示拟议方法的有效性,该方法通过在DomaBed框架中多个DG基准数据集上比18个DG的算法效果要高,从而实现新的最新结果。