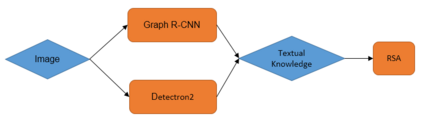
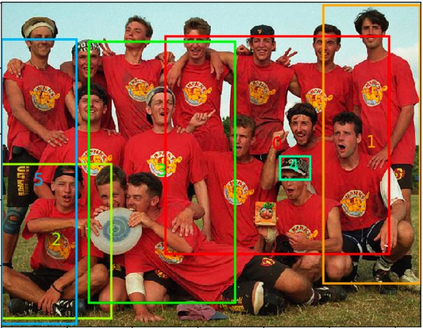
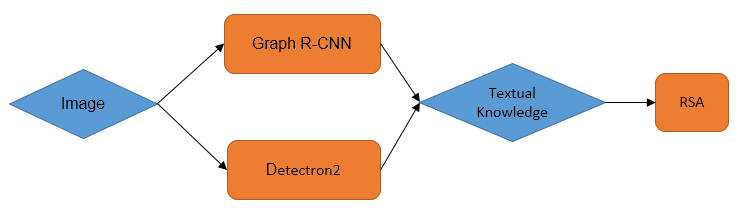
This paper focuses on a referring expression generation (REG) task in which the aim is to pick out an object in a complex visual scene. One common theoretical approach to this problem is to model the task as a two-agent cooperative scheme in which a `speaker' agent would generate the expression that best describes a targeted area and a `listener' agent would identify the target. Several recent REG systems have used deep learning approaches to represent the speaker/listener agents. The Rational Speech Act framework (RSA), a Bayesian approach to pragmatics that can predict human linguistic behavior quite accurately, has been shown to generate high quality and explainable expressions on toy datasets involving simple visual scenes. Its application to large scale problems, however, remains largely unexplored. This paper applies a combination of the probabilistic RSA framework and deep learning approaches to larger datasets involving complex visual scenes in a multi-step process with the aim of generating better-explained expressions. We carry out experiments on the RefCOCO and RefCOCO+ datasets and compare our approach with other end-to-end deep learning approaches as well as a variation of RSA to highlight our key contribution. Experimental results show that while achieving lower accuracy than SOTA deep learning methods, our approach outperforms similar RSA approach in human comprehension and has an advantage over end-to-end deep learning under limited data scenario. Lastly, we provide a detailed analysis on the expression generation process with concrete examples, thus providing a systematic view on error types and deficiencies in the generation process and identifying possible areas for future improvements.
翻译:本文侧重于一个参考表达生成(REG)任务, 目的是在复杂的视觉场景中选择一个对象。 对这一问题的一种共同的理论方法是将任务建模成一个双试剂合作计划,让一个“扩音器”代理器产生最能描述目标区域的表达式,而一个“扩音器”代理器则能够确定目标对象。 几个最近的REG系统使用深层学习方法来代表演讲者/听筒代理器。 理性演讲法框架(RSA)是针对实际操作的实用方法,可以非常准确地预测人类语言行为。 一个共同的理论方法是,在使用简单视觉场景的玩具数据集中产生高质量和可解释的表达式。 然而,在大规模问题中应用该“扩音器”代理器将产生最能描述目标区域的表达式,而“听者”代理器则使用更深层的学习方法来代表演讲者/听者。 我们对RefCOCO和RefCO+数据设置进行了实验, 将我们的方法与其他有深度和可解释性的易变的方法进行比较。 在最终分析方法中,我们用更深层的系统化的 RSA 方法中, 显示我们为学习过程的学习方法的精确的方法, 展示中,在最后的学习方法中提供比学习方法的更低的学习方法,, 展示, 展示中,在最后的进度中,以学习方法,在学习方法中,在学习后演进式中提供比。