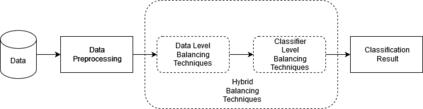
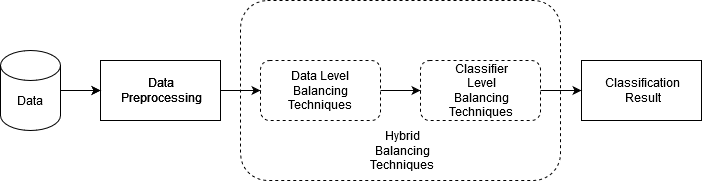
A high imbalance exists between technical debt and non-technical debt source code comments. Such imbalance affects Self-Admitted Technical Debt (SATD) detection performance, and existing literature lacks empirical evidence on the choice of balancing technique. In this work, we evaluate the impact of multiple balancing techniques, including Data level, Classifier level, and Hybrid, for SATD detection in Within-Project and Cross-Project setup. Our results show that the Data level balancing technique SMOTE or Classifier level Ensemble approaches Random Forest or XGBoost are reasonable choices depending on whether the goal is to maximize Precision, Recall, F1, or AUC-ROC. We compared our best-performing model with the previous SATD detection benchmark (cost-sensitive Convolution Neural Network). Interestingly the top-performing XGBoost with SMOTE sampling improved the Within-project F1 score by 10% but fell short in Cross-Project set up by 9%. This supports the higher generalization capability of deep learning in Cross-Project SATD detection, yet while working within individual projects, classical machine learning algorithms can deliver better performance. We also evaluate and quantify the impact of duplicate source code comments in SATD detection performance. Finally, we employ SHAP and discuss the interpreted SATD features. We have included the replication package and shared a web-based SATD prediction tool with the balancing techniques in this study.
翻译:技术债务和非技术债务源代码评论之间存在高度的不平衡。这种不平衡影响自我承认的技术债务(SATD)检测业绩,现有文献缺乏关于平衡技术选择的经验证据。在这项工作中,我们评估多种平衡技术的影响,包括数据水平、分类水平和混合技术,以便在项目内部和跨项目设置中检测SATD。我们的结果表明,数据水平平衡技术SMOTE或分类方法随机森林或XGBoost是合理的选择,取决于目标是最大限度地提高精度、召回、F1或AUC-ROC。我们比较了我们的最佳表现模式与先前的SATD检测基准(成本敏感的神经网络)相比较。有趣的是,我们通过SMOTE抽样评估了多种平衡技术的影响,将项目内部F1评分提高了10%,但在交叉项目设定的交叉项目中则短于9%。这支持了跨项目SMOTD探测深度学习的更高普遍化能力,同时在单个项目中工作,经典机器学习算法可以提供更好的业绩。我们还评估并量化了SAGOD的升级模型。我们最后在SARTD中利用了SAD的升级工具,我们利用了SARSAR的模型分析并解释了了SARVAFA的复制的预测。