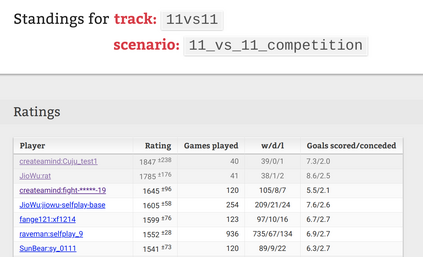
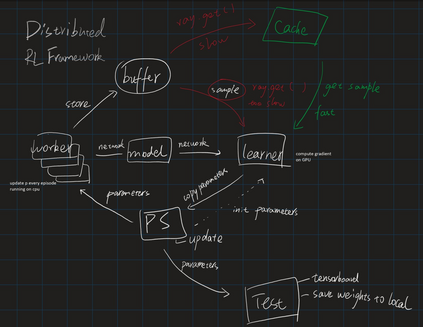
Deep Q Network (DQN) is a very successful algorithm, yet the inherent problem of reinforcement learning, i.e. the exploit-explore balance, remains. In this work, we introduce entropy regularization into DQN and propose SQN. We find that the backup equation of soft Q learning can enjoy the corrective feedback if we view the soft backup as policy improvement in the form of Q, instead of policy evaluation. We show that Soft Q Learning with Corrective Feedback (SQL-CF) underlies the on-plicy nature of SQL and the equivalence of SQL and Soft Policy Gradient (SPG). With these insights, we propose an on-policy version of deep Q learning algorithm, i.e. Q On-Policy (QOP). We experiment with QOP on a self-play environment called Google Research Football (GRF). The QOP algorithm exhibits great stability and efficiency in training GRF agents.
翻译:深Q网络(DQN)是一个非常成功的算法,然而,强化学习的固有问题,即开发-爆炸平衡,仍然存在。在这项工作中,我们将加密正规化引入DQN并提议SQN。我们发现软Q学习的备份方程式可以享有纠正反馈,如果我们把软备份视为Q形式的政策改进,而不是政策评价。我们显示,软备份与纠正反馈(SQL-CF)的软学习是SQL(SQL-CF)的简单性质和SQL和软政策进步(SPG)的等同性的基础。根据这些见解,我们提出了深Q学习算法的政策版本,即QOP(Q-POL-Policy(QOP) 。我们与QOP(QOP)实验一个叫作谷歌研究足球(GRF)的自玩环境。QOP算法在培训GRF代理方面表现出极大的稳定性和效率。