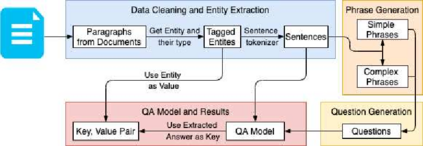
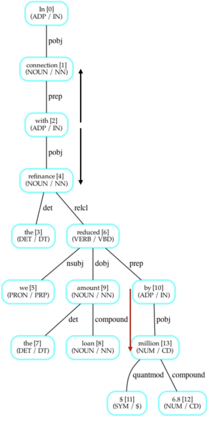
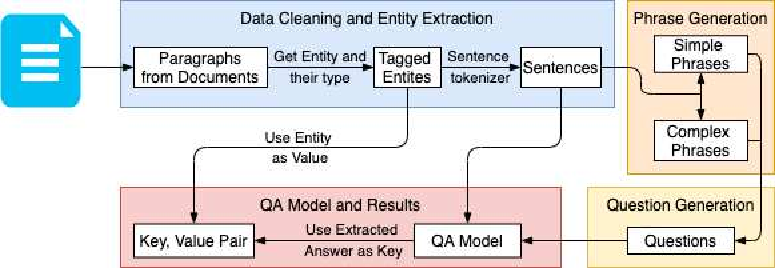
NLP research has been focused on NER extraction and how to efficiently extract them from a sentence. However, generating relevant context of entities from a sentence has remained under-explored. In this work we introduce the task Context-NER in which relevant context of an entity has to be generated. The extracted context may not be found exactly as a substring in the sentence. We also introduce the EDGAR10-Q dataset for the same, which is a corpus of 1,500 publicly traded companies. It is a manually created complex corpus and one of the largest in terms of number of sentences and entities (1 M and 2.8 M). We introduce a baseline approach that leverages phrase generation algorithms and uses the pre-trained BERT model to get 33% ROUGE-L score. We also do a one shot evaluation with GPT-3 and get 39% score, signifying the hardness and future scope of this task. We hope that addition of this dataset and our study will pave the way for further research in this domain.
翻译:NLP的研究侧重于净化提取和如何有效地从一个判决中提取它们。然而,从一个判决中产生实体的相关背景一直没有得到充分探讨。在这项工作中,我们引入了必须生成一个实体相关背景的任务背景-净化。提取的上下文可能不完全作为该句中的子字符。我们还为此引入了EDGAR10-Q数据集,该数据集由1,500家公开交易的公司组成。这是一个人工创建的复杂数据集,在判刑和实体数量(1M和2.8M)方面是最大的。我们引入了一种基准方法,利用生成算法的短语,并利用预先培训的BERT模型获得33%的ROUGE-L分数。我们还对GPT-3做了一次镜头评价,并获得了39%的分数,表明了这项任务的难度和未来范围。我们希望,增加这一数据集和我们的研究将为该领域的进一步研究铺平道路。