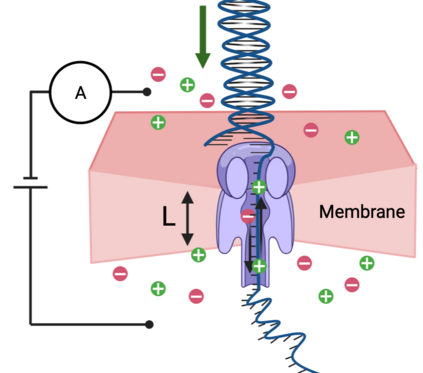
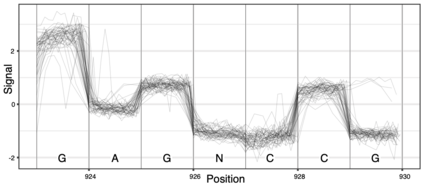
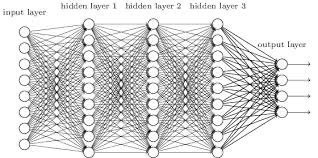
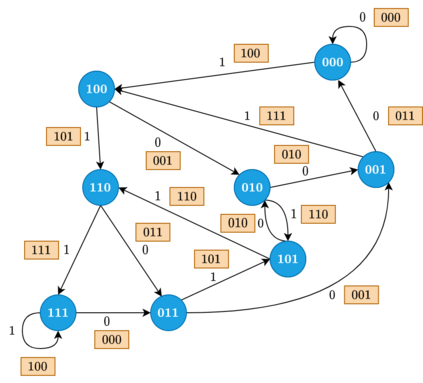
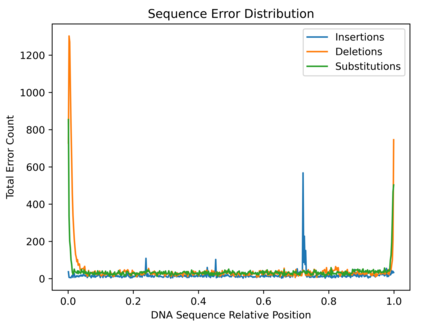
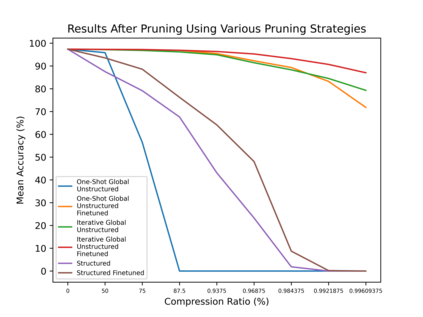
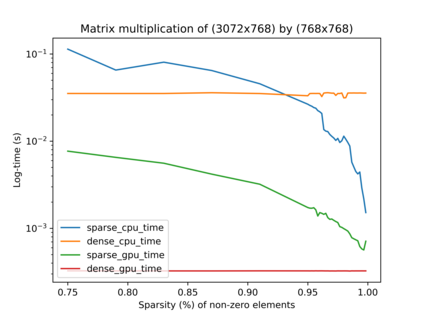
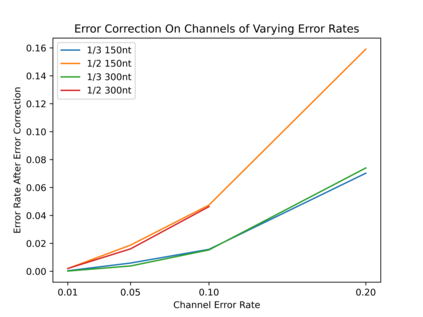
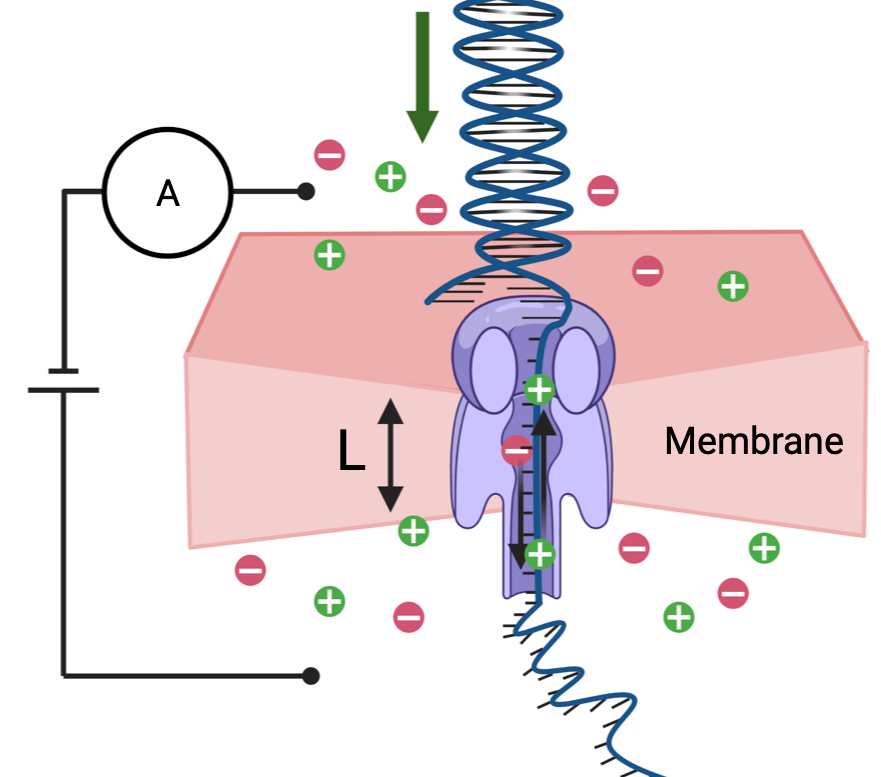
DNA is a leading candidate as the next archival storage media due to its density, durability and sustainability. To read (and write) data DNA storage exploits technology that has been developed over decades to sequence naturally occurring DNA in the life sciences. To achieve higher accuracy for previously unseen, biological DNA, sequencing relies on extending and training deep machine learning models known as basecallers. This growth in model complexity requires substantial resources, both computational and data sets. It also eliminates the possibility of a compact read head for DNA as a storage medium. We argue that we need to depart from blindly using sequencing models from the life sciences for DNA data storage. The difference is striking: for life science applications we have no control over the DNA, however, in the case of DNA data storage, we control how it is written, as well as the particular write head. More specifically, data-carrying DNA can be modulated and embedded with alignment markers and error correcting codes to guarantee higher fidelity and to carry out some of the work that the machine learning models perform. In this paper, we study accuracy trade-offs between deep model size and error correcting codes. We show that, starting with a model size of 107MB, the reduced accuracy from model compression can be compensated by using simple error correcting codes in the DNA sequences. In our experiments, we show that a substantial reduction in the size of the model does not incur an undue penalty for the error correcting codes used, therefore paving the way for portable data-carrying DNA read head. Crucially, we show that through the joint use of model compression and error correcting codes, we achieve a higher read accuracy than without compression and error correction codes.
翻译:DNA 储存 读( 写) 数据 DNA 储存 利用几十年来开发的技术 来对生命科学中自然出现的DNA进行排序 。 要提高先前所见的、 生物DNA 的准确性, 测序依赖于扩展和培训深机学习模型, 更具体地说, 数据记录DNA可以与校准标记和错误校正代码进行调制和嵌入, 以保证更高准确性, 并完成机器学习模型的某些工作。 我们争辩说, 我们需要从盲目地使用生命科学的测序模型进行DNA数据存储。 差异是惊人的: 生命科学应用对DNA没有控制权, 然而, 在DNA数据存储方面, 我们控制它是如何写成的, 以及特定的写头。 更具体地说, 数据记录DNA的精密度可以通过校正和校正代码来调节。 我们用一个不精确的DNA的校正代码来进行校正。