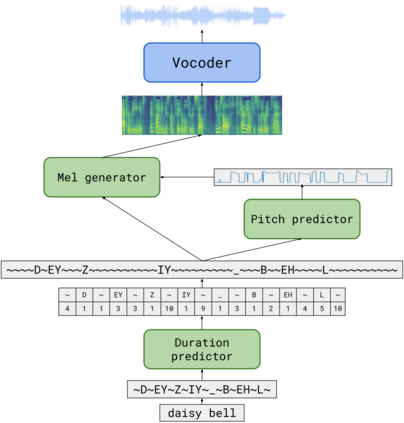
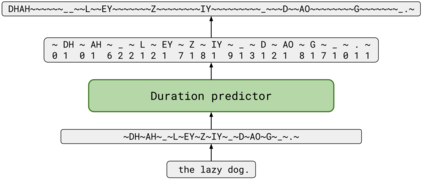
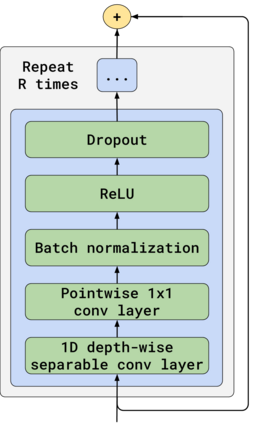
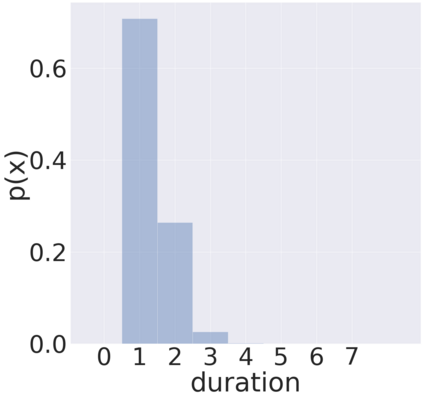
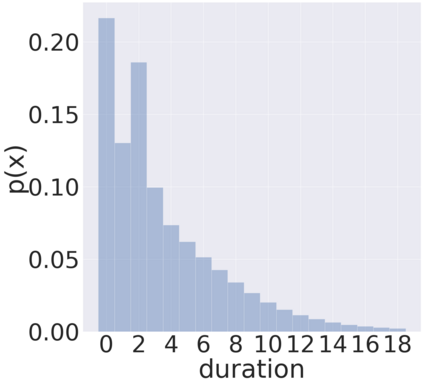
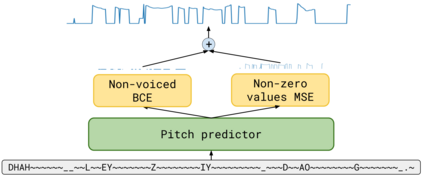
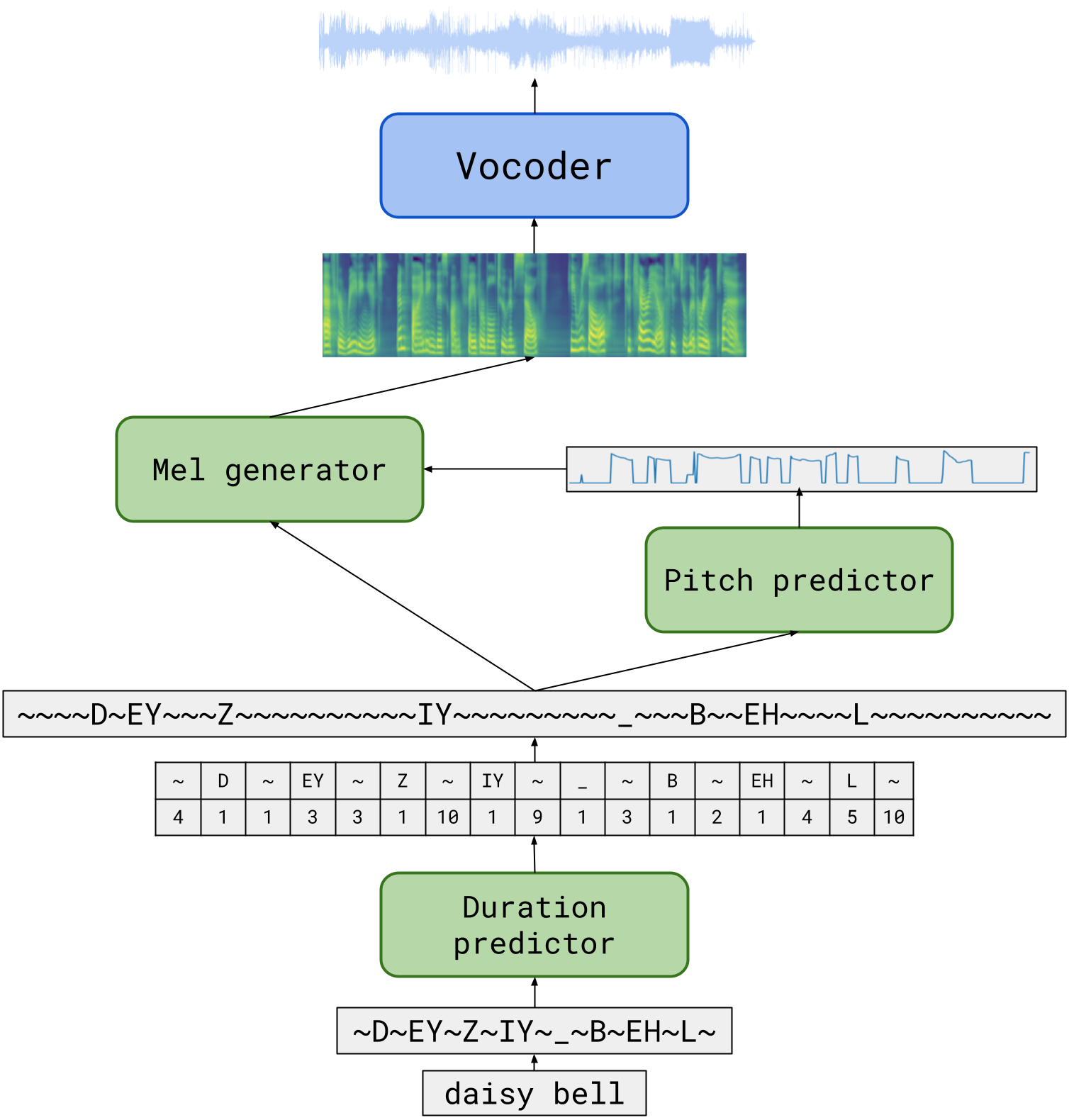
We propose TalkNet, a non-autoregressive convolutional neural model for speech synthesis with explicit pitch and duration prediction. The model consists of three feed-forward convolutional networks. The first network predicts grapheme durations. An input text is expanded by repeating each symbol according to the predicted duration. The second network predicts pitch value for every mel frame. The third network generates a mel-spectrogram from the expanded text conditioned on predicted pitch. All networks are based on 1D depth-wise separable convolutional architecture. The explicit duration prediction eliminates word skipping and repeating. The quality of the generated speech nearly matches the best auto-regressive models - TalkNet trained on the LJSpeech dataset got MOS4.08. The model has only 13.2M parameters, almost 2x less than the present state-of-the-art text-to-speech models. The non-autoregressive architecture allows for fast training and inference - 422x times faster than real-time. The small model size and fast inference make the TalkNet an attractive candidate for embedded speech synthesis.
翻译:我们提议TalkNet, 这是一种非潜移动神经变异模型, 用于语音合成, 并有清晰的投影和持续时间预测。 该模型由三个进化前变动网络组成。 第一个网络预测了图形化持续时间。 第一个网络预测了每个符号的重复时间长度。 一个输入文本根据预测的时间长度而扩大。 第二个网络预测了每个模数框架的投影值。 第三个网络从以预测的投影为条件的扩大文本中生成一个中位光谱。 所有网络都基于 1D 的深度、 分解共变结构。 明确的持续时间预测消除了单词跳过和重复。 生成的演讲的质量几乎与最佳的自动反向模型( LJSpeech 数据集培训的TaltNet) 几乎吻合 MOS4. 08 。 这个模型只有13.2M 参数, 几乎比目前最先进的文本到语音合成模型少2x。 非倾向结构允许快速培训和推断 - 422x 速度比实时快422x 。 小型模型和快速推导使语音网络成为一个有吸引力的候选人。