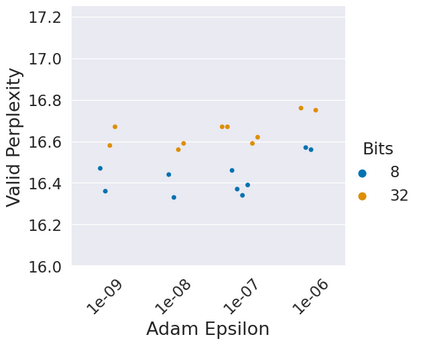
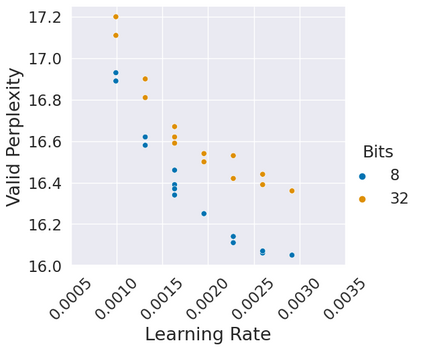
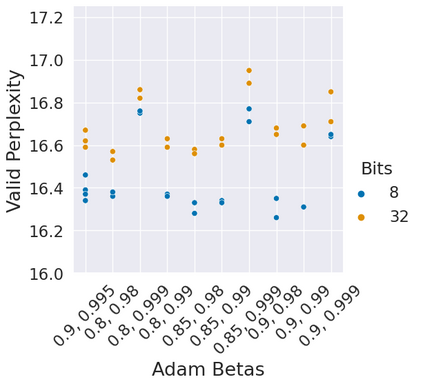
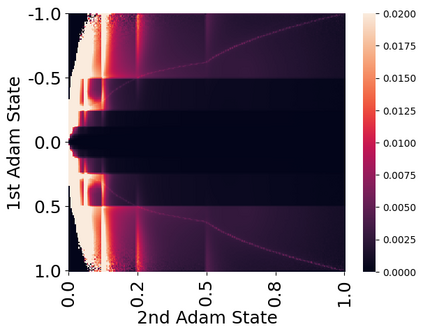
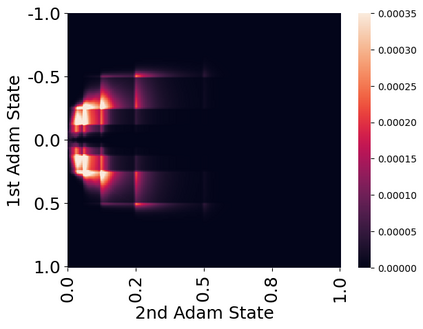
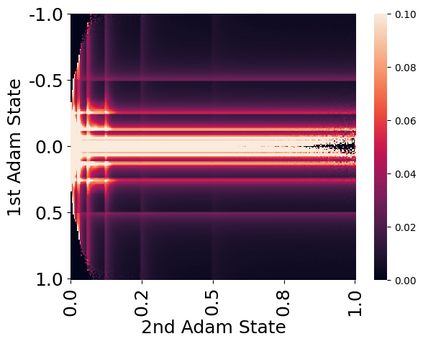
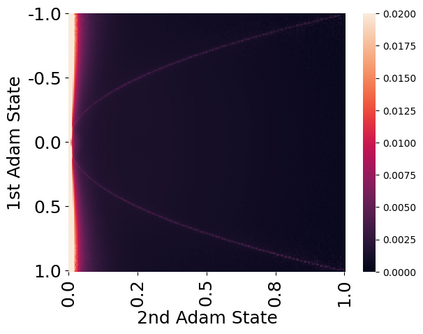
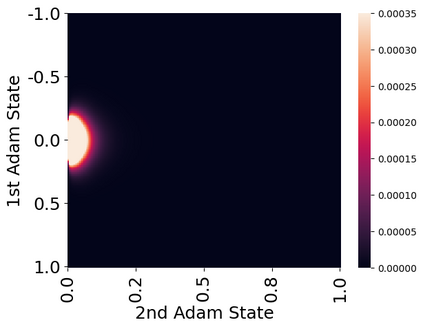
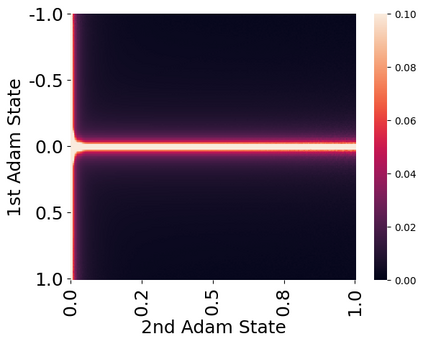
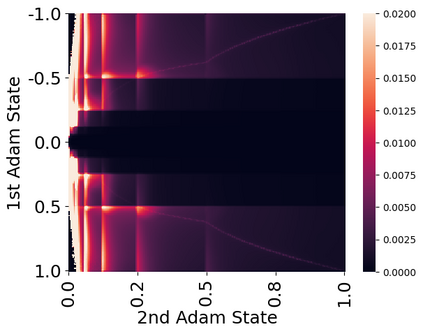
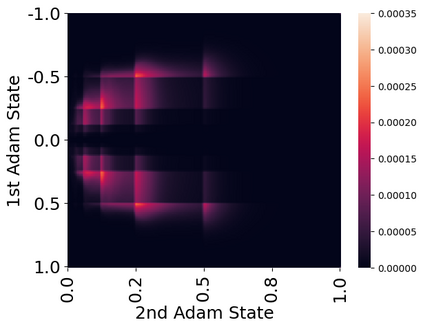
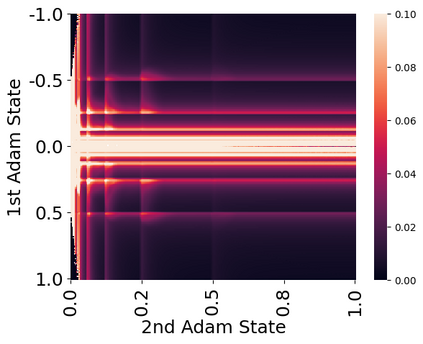
Stateful optimizers maintain gradient statistics over time, e.g., the exponentially smoothed sum (SGD with momentum) or squared sum (Adam) of past gradient values. This state can be used to accelerate optimization compared to plain stochastic gradient descent but uses memory that might otherwise be allocated to model parameters, thereby limiting the maximum size of models trained in practice. In this paper, we develop the first optimizers that use 8-bit statistics while maintaining the performance levels of using 32-bit optimizer states. To overcome the resulting computational, quantization, and stability challenges, we develop block-wise dynamic quantization. Block-wise quantization divides input tensors into smaller blocks that are independently quantized. Each block is processed in parallel across cores, yielding faster optimization and high precision quantization. To maintain stability and performance, we combine block-wise quantization with two additional changes: (1) dynamic quantization, a form of non-linear optimization that is precise for both large and small magnitude values, and (2) a stable embedding layer to reduce gradient variance that comes from the highly non-uniform distribution of input tokens in language models. As a result, our 8-bit optimizers maintain 32-bit performance with a small fraction of the memory footprint on a range of tasks, including 1.5B parameter language modeling, GLUE finetuning, ImageNet classification, WMT'14 machine translation, MoCo v2 contrastive ImageNet pretraining+finetuning, and RoBERTa pretraining, without changes to the original optimizer hyperparameters. We open-source our 8-bit optimizers as a drop-in replacement that only requires a two-line code change.
翻译:州级优化保持了一段时间内的梯度统计, 例如, 指数平滑的和( 具有动力的SGD) 或过去梯度值的平方和( 亚达姆) 。 此状态可以用来比平坦的梯度梯度下降加速优化, 但使用记忆, 否则可能会分配到模型参数, 从而限制经过实践培训的模型的最大规模 。 在本文中, 我们开发了第一个使用 8位数统计的优化, 并同时保持使用 32 位数优化状态的性能水平 。 为了克服由此产生的计算、 量级化和稳定性挑战, 我们开发了轮式动态的动态动态平整数。 区间优化将输入的进量分分成小块分成独立四分块。 每个区段都平行地处理, 产生更快的优化和高度精确的模型。 为了保持稳定性和性能, 我们的动态四位数级化非线性调整形式, 一个稳定的嵌入层层, 一个来自高度不精确的模型, 一个比值前的图像值前数级值 。