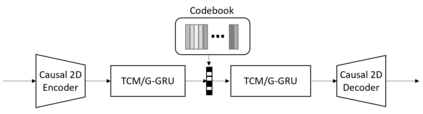
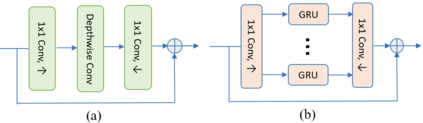
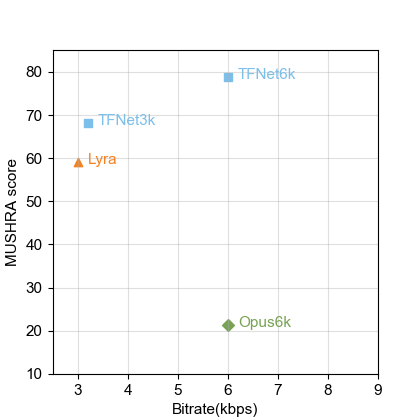
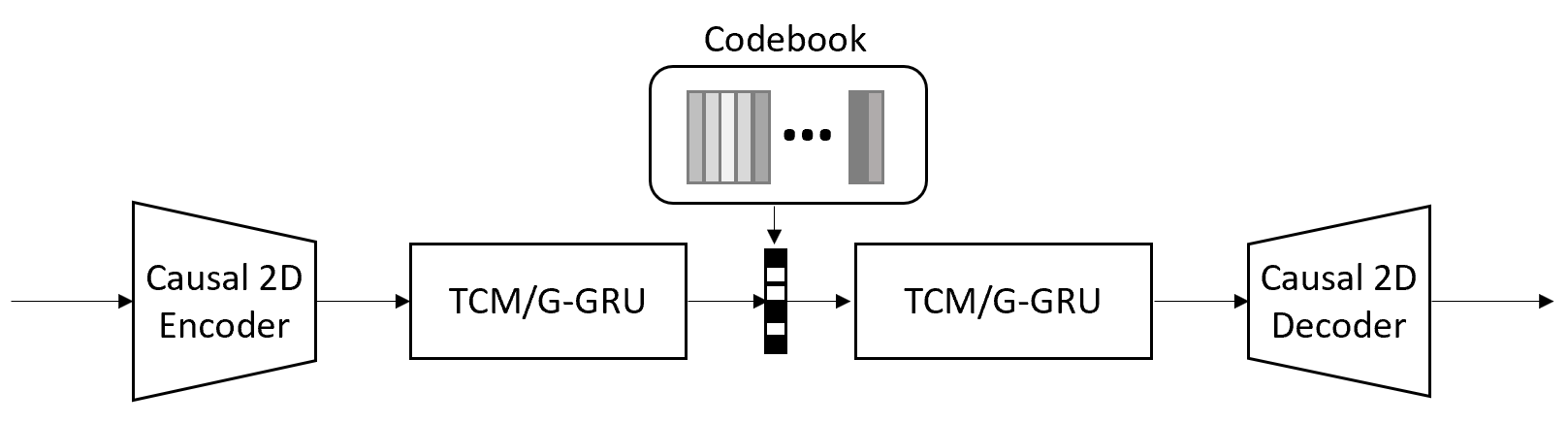
Deep-learning based methods have shown their advantages in audio coding over traditional ones but limited attention has been paid on real-time communications (RTC). This paper proposes the TFNet, an end-to-end neural audio codec with low latency for RTC. It takes an encoder-temporal filtering-decoder paradigm that seldom being investigated in audio coding. An interleaved structure is proposed for temporal filtering to capture both short-term and long-term temporal dependencies. Furthermore, with end-to-end optimization, the TFNet is jointly optimized with speech enhancement and packet loss concealment, yielding a one-for-all network for three tasks. Both subjective and objective results demonstrate the efficiency of the proposed TFNet.
翻译:深层学习方法显示了其在传统编码上的音频编码优势,但对实时通信的注意有限。本文件提议TFNet,这是一个终端至终端神经音解码器,为RTC提供低潜线。它需要一种在音频编码中很少被调查的编码器-时空过滤器-解码器模式。提议了一种间断结构,用于时间过滤,以捕捉短期和长期时间依赖性。此外,随着终端至终端的优化,TFNet与语音增强和包封损失隐藏联合优化,为三项任务产生了一对一的网络。主观和客观结果都表明拟议的TFNet的效率。