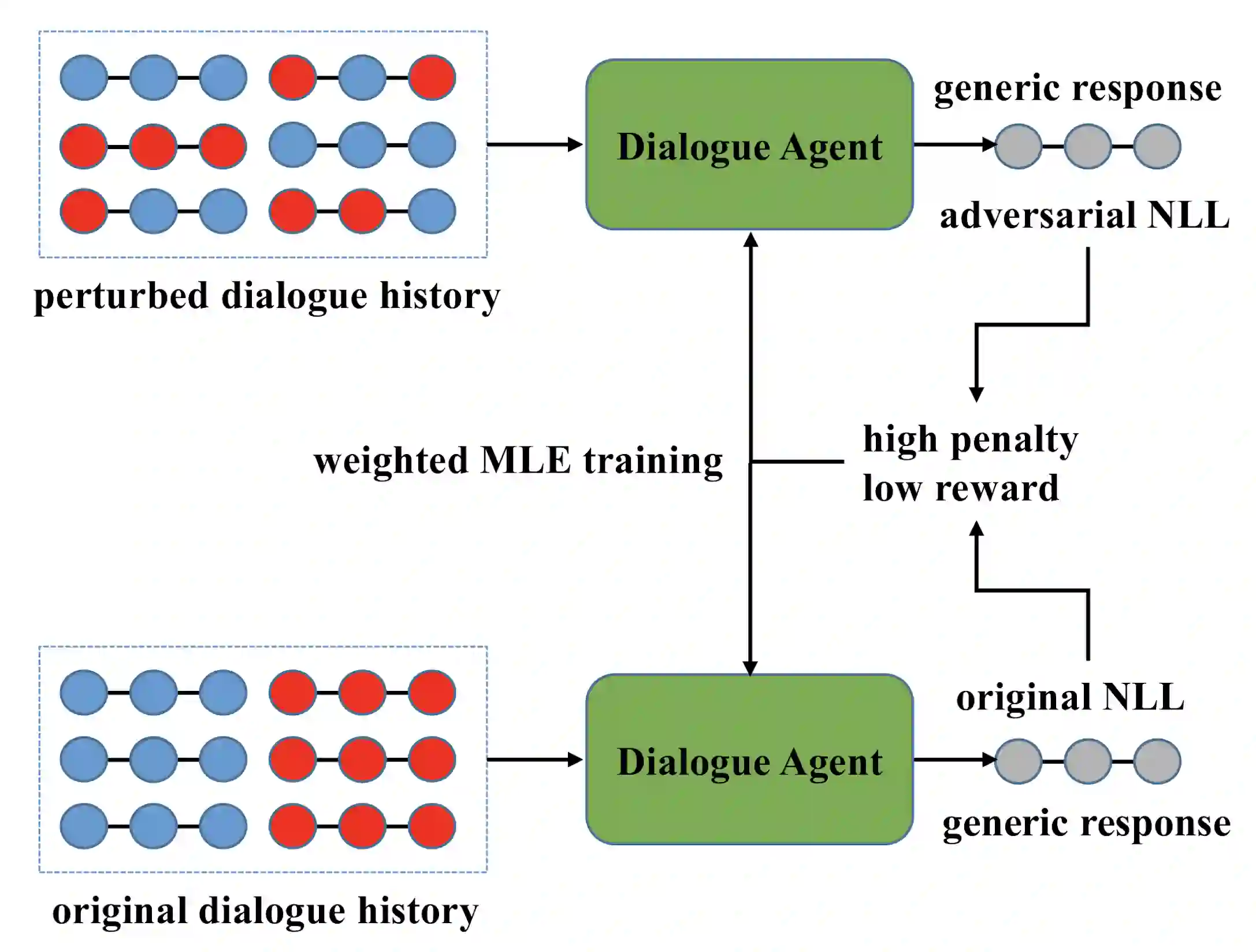
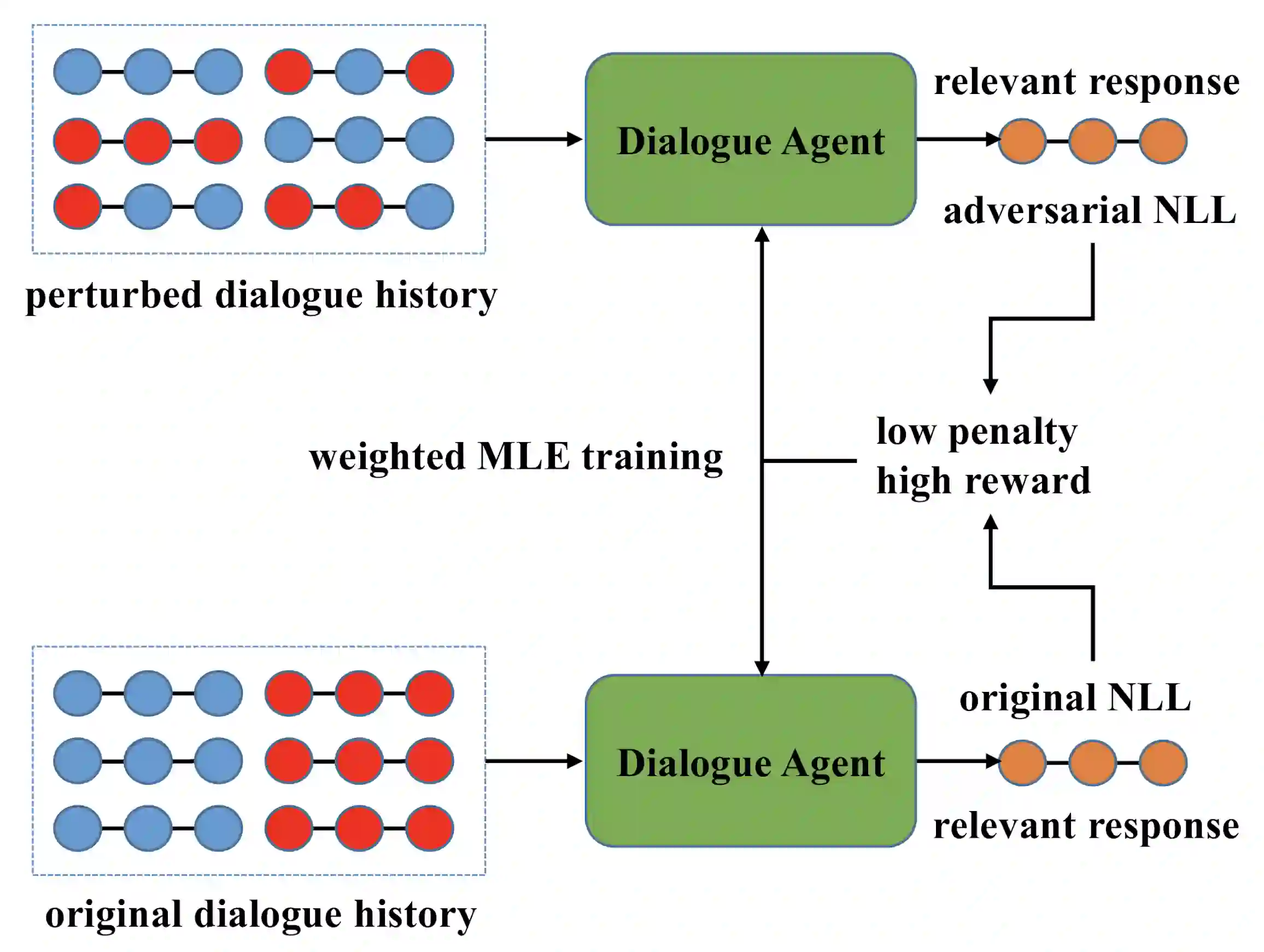
In this paper, we propose Inverse Adversarial Training (IAT) algorithm for training neural dialogue systems to avoid generic responses and model dialogue history better. In contrast to standard adversarial training algorithms, IAT encourages the model to be sensitive to the perturbation in the dialogue history and therefore learning from perturbations. By giving higher rewards for responses whose output probability reduces more significantly when dialogue history is perturbed, the model is encouraged to generate more diverse and consistent responses. By penalizing the model when generating the same response given perturbed dialogue history, the model is forced to better capture dialogue history and generate more informative responses. Experimental results on two benchmark datasets show that our approach can better model dialogue history and generate more diverse and consistent responses. In addition, we point out a problem of the widely used maximum mutual information (MMI) based methods for improving the diversity of dialogue response generation models and demonstrate it empirically.
翻译:在本文中,我们建议为培训神经对话系统制定反反向培训(IAT)算法,以更好地避免通用反应和模拟对话历史。与标准的对抗性培训算法相反,IAT鼓励模型对对话历史的扰动敏感,从而从扰动中学习。如果对话历史受到扰动时,其产出概率下降幅度更大,则对答复给予更高的奖励,鼓励模型产生更加多样和一致的响应。当模型产生与受扰动的对话历史相同的响应时,通过惩罚模型,该模型被迫更好地捕捉对话历史并产生更多的信息反应。两个基准数据集的实验结果显示,我们的方法可以更好地模拟对话历史并产生更加多样和一致的响应。此外,我们指出广泛使用最大程度的相互信息(MMI)方法来改进对话反应生成模型的多样性并用经验来证明这一问题。