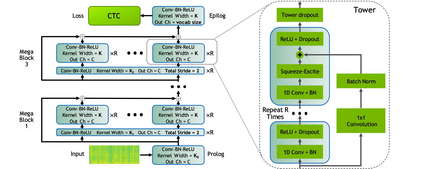
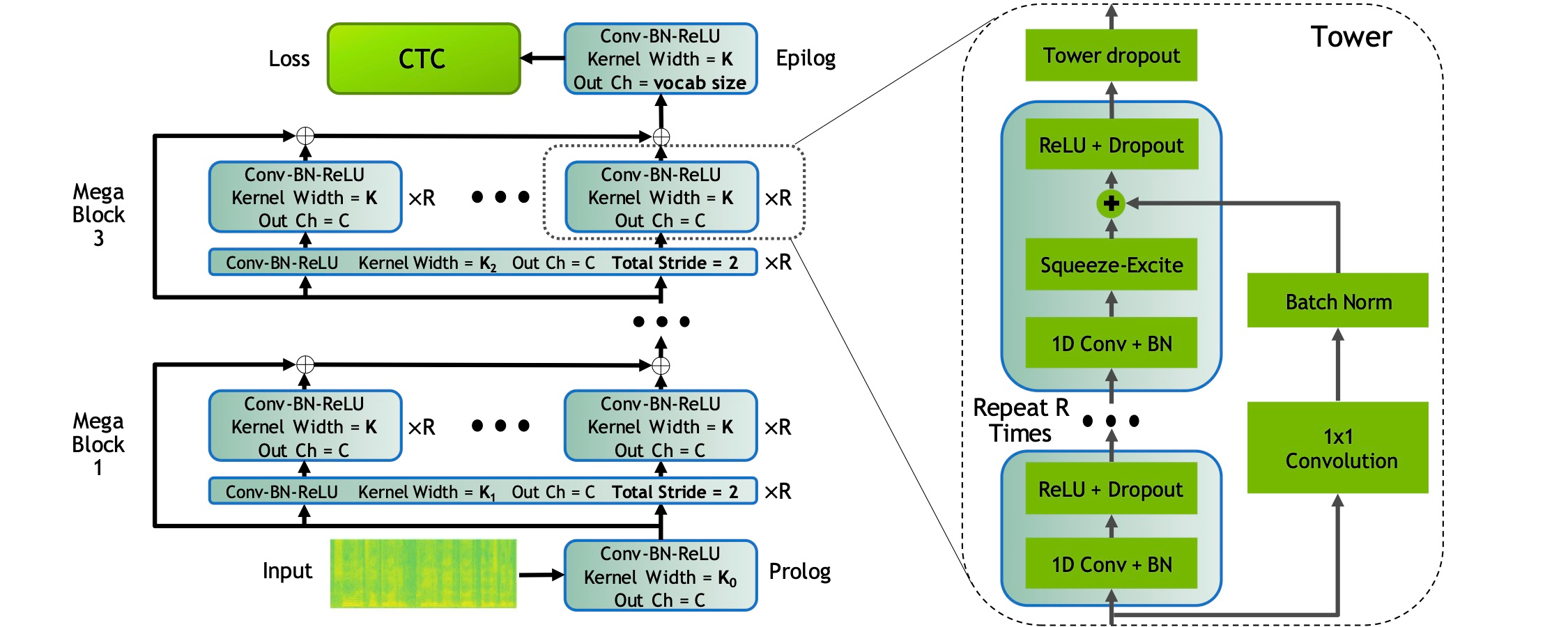
End-to-end automatic speech recognition systems have achieved great accuracy by using deeper and deeper models. However, the increased depth comes with a larger receptive field that can negatively impact model performance in streaming scenarios. We propose an alternative approach that we call Neural Mixture Model. The basic idea is to introduce a parallel mixture of shallow networks instead of a very deep network. To validate this idea we design CarneliNet -- a CTC-based neural network composed of three mega-blocks. Each mega-block consists of multiple parallel shallow sub-networks based on 1D depthwise-separable convolutions. We evaluate the model on LibriSpeech, MLS and AISHELL-2 datasets and achieved close to state-of-the-art results for CTC-based models. Finally, we demonstrate that one can dynamically reconfigure the number of parallel sub-networks to accommodate the computational requirements without retraining.
翻译:端到端自动语音识别系统通过使用更深和更深的模型实现了非常准确性。然而,越深的语音识别系统越发精确。越广的深度越大,就会有一个更大的可接受域,对流景中的模型性能产生消极影响。我们建议了一种我们称之为神经混合模型的替代方法。基本想法是引入一种平行的浅层网络组合,而不是一个非常深的网络。为了验证这一想法,我们设计了由3个超大型区块组成的以CONT为基础的神经网络CarneliNet。每个超大型区块由多个平行的浅层子网络组成,这些网络以1D深度可分离的相容为根据。我们评价了LibriSpeech、MLS和ASISELL-2数据集模型,并接近了基于CT的模型的最新结果。最后,我们证明可以动态地重新配置平行的子网络数量,以适应不进行再培训的计算要求。