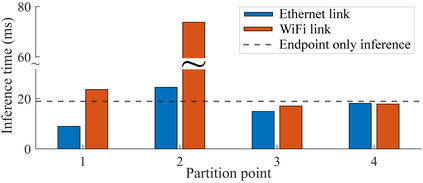
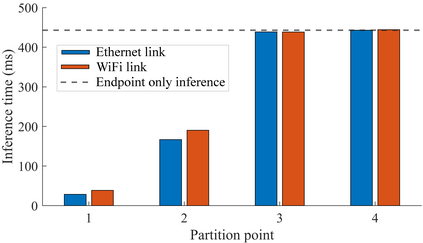
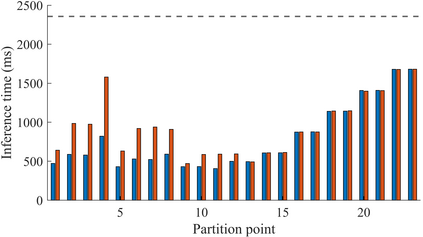
Collaborative deep learning inference between low-resource endpoint devices and edge servers has received significant research interest in the last few years. Such computation partitioning can help reducing endpoint device energy consumption and improve latency, but equally importantly also contributes to privacy-preserving of sensitive data. This paper describes Edge-PRUNE, a flexible but light-weight computation framework for distributing machine learning inference between edge servers and one or more client devices. Compared to previous approaches, Edge-PRUNE is based on a formal dataflow computing model, and is agnostic towards machine learning training frameworks, offering at the same time wide support for leveraging deep learning accelerators such as embedded GPUs. The experimental section of the paper demonstrates the use and performance of Edge-PRUNE by image classification and object tracking applications on two heterogeneous endpoint devices and an edge server, over wireless and physical connections. Endpoint device inference time for SSD-Mobilenet based object tracking, for example, is accelerated 5.8x by collaborative inference.
翻译:过去几年来,低资源端点装置和边缘服务器之间的深层次合作学习推论引起了相当大研究兴趣。这种计算分割有助于减少端点装置的能源消耗,改善延缓性能,但同样重要的是,也有助于保护敏感数据的隐私。本文描述了Edge-PRUNE,这是一个灵活但轻量的计算框架,用于在边缘服务器和一个或多个客户设备之间分配机器学习推论。与以往的做法相比,Edge-PRUNE基于正式的数据流计算模型,并且对机器学习培训框架持怀疑态度,同时为利用嵌入式GPU等深层学习加速器提供广泛的支持。本文实验部分通过图像分类和对象跟踪应用,展示了Edge-PRUNE在两个多变端点服务器和边缘服务器上的使用和性能。例如,通过协作推断,SD-Mobilenet天体跟踪的端点推断时间加快了5.8x的使用和性能。