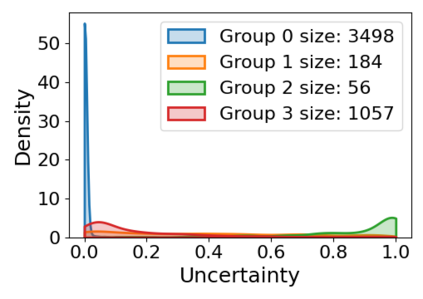
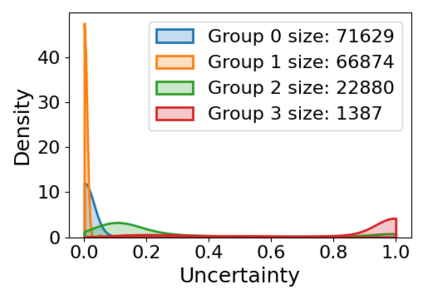
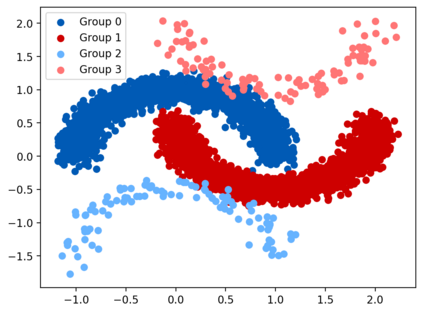
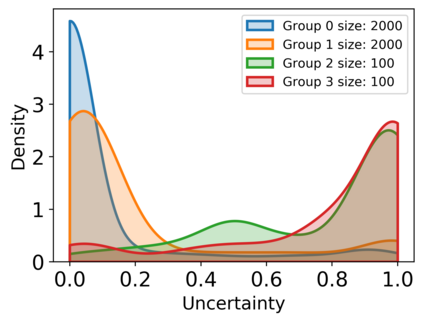
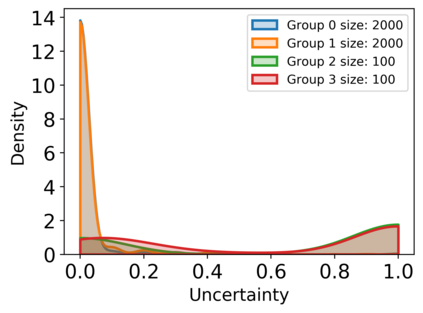
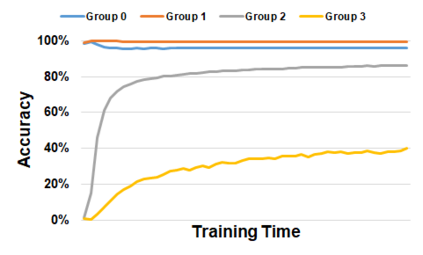
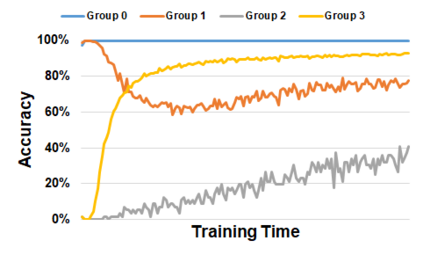
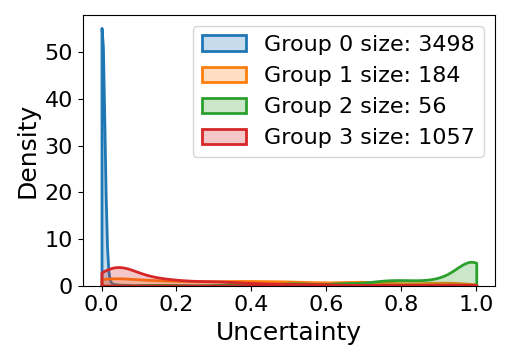
Subpopulation shift widely exists in many real-world machine learning applications, referring to the training and test distributions containing the same subpopulation groups but varying in subpopulation frequencies. Importance reweighting is a normal way to handle the subpopulation shift issue by imposing constant or adaptive sampling weights on each sample in the training dataset. However, some recent studies have recognized that most of these approaches fail to improve the performance over empirical risk minimization especially when applied to over-parameterized neural networks. In this work, we propose a simple yet practical framework, called uncertainty-aware mixup (UMIX), to mitigate the overfitting issue in over-parameterized models by reweighting the ''mixed'' samples according to the sample uncertainty. The training-trajectories-based uncertainty estimation is equipped in the proposed UMIX for each sample to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that UMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of our method both qualitatively and quantitatively. Code is available at https://github.com/TencentAILabHealthcare/UMIX.
翻译:许多现实世界的机器学习应用中广泛存在亚人口变化,指的是包含相同亚人口群的培训和测试分布,但在亚人口频率上各有差异。在培训数据集中,通过对每个样本施加恒定或适应性抽样权重,重新加权是处理亚人口变化问题的正常方法。然而,最近的一些研究认识到,这些方法大多未能提高实证风险最小化的性能,特别是在对过度参数化的神经网络应用时。在这项工作中,我们提出了一个简单而实用的框架,称为不确定性混合(UMIX),以通过根据抽样不确定性重新加权“混合”样本来减轻超标定模型中的过度适用问题。基于培训轨迹的不确定性估计载于拟议的UMIX,供每个样本灵活地描述亚人口分布。我们还提供了深刻的理论分析,以核实UMIX比先前的工程有更好的概括性约束。此外,我们开展了广泛的实证研究,以验证我们方法的定性和定量有效性。