深度学习的几何理解(3) - 概率变换的几何观点

作者:顾险峰
(最近,哈佛大学丘成桐先生领导的团队,大连理工大学罗钟铉教授、雷娜教授领导的团队应用几何方法研究深度学习。老顾受邀在一些大学和科研机构做了题为“深度学习的几何观点”的报告,汇报了这方面的进展情况。这里是报告的简要记录,具体内容见【1】。)

2018年6月15日严东辉教授邀请老顾在泛华统计协会( International Chinese Statistical Association)举办的应用统计会议(ICSA2018 Applied Statistics Symposium)上做了“深度学习的几何观点”的报告。会议上Eric Xing教授给出报告,用统计概率的观点统一了变分自动编码器(VAE,Variational Autoencoder)和生成对抗网络(GAN,Generative Aderseral Network)。老顾用几何观点将VAE和GAN加以分析,再度阐述GAN模型中的对抗是虚拟的,没有必要的,生成器网络和判别器网络是冗余的。(以前的博文曾经系统阐述过,请见 “虚构的对抗,GAN with the wind”)下面我们从几何角度详细解释。
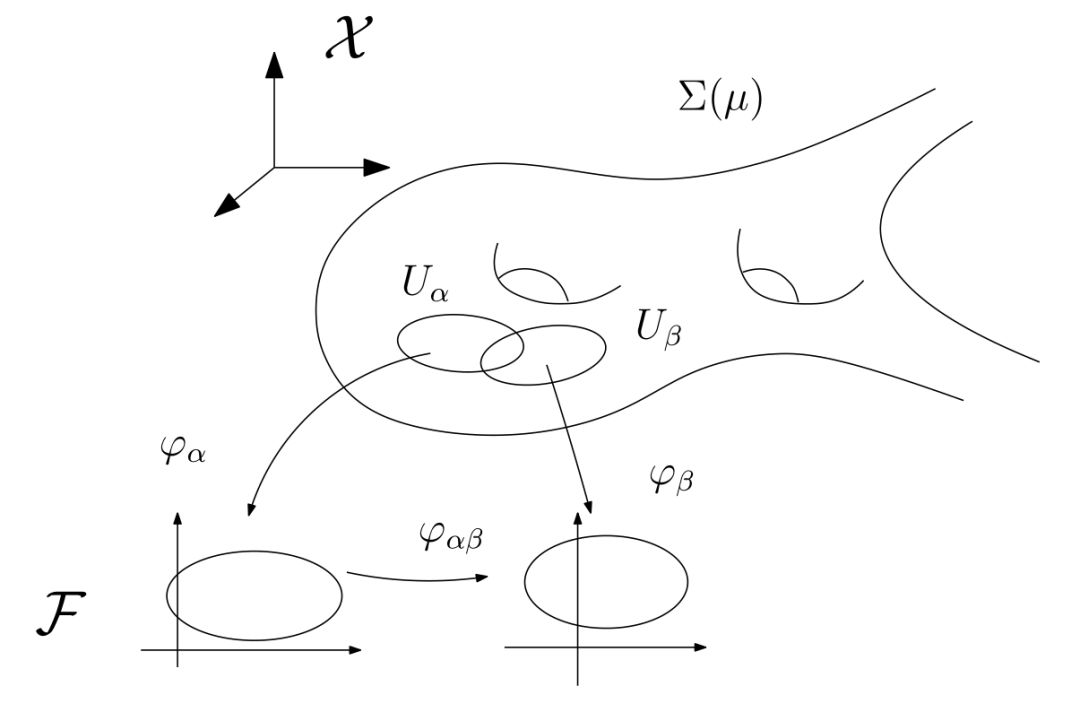
图1. 流形结构。
我们前面阐述过深度学习成功的核心原因可以部分归结为流形分布律和聚类分布律(深度学习的几何观点(1) - 流形分布定律),深度学习的基本任务就在于从数据中学习流形结构,建立流形的参数表达;和变换概率分布。
如图1所示,假设概率分布
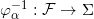
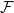
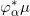
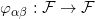



图2. 隐空间的同胚映射,改变概率分布。
如图2所示,我们将米勒佛曲面
给定欧氏空间中的两个区域和定义其上的概率测度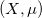
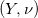
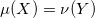
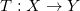
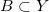

那么我们说此映射保持测度,记成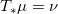
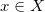
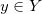
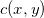
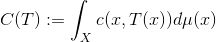
法国数学家蒙日(Monge)于1781年提出了著名的最优传输问题:寻找保持测度的传输映射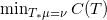
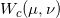
Kantorovich将传输映射(transportation map)减弱为传输规划(transportation scheme),用联合概率分布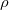
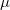

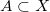
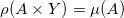
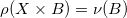
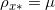
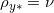
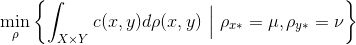
如果最优传输映射存在,那么最优联合概率分布的支集为对角线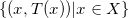
Kantarovich问题等价于其对偶形式, Wasserstein距离等于

这里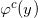
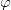
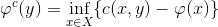
我们将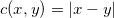
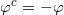
二十世纪八十年代,Brenier进一步发展了Kantarovich的理论。如果采用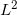
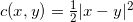
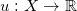
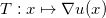
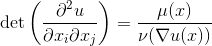
更进一步,在
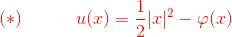
最优传输的
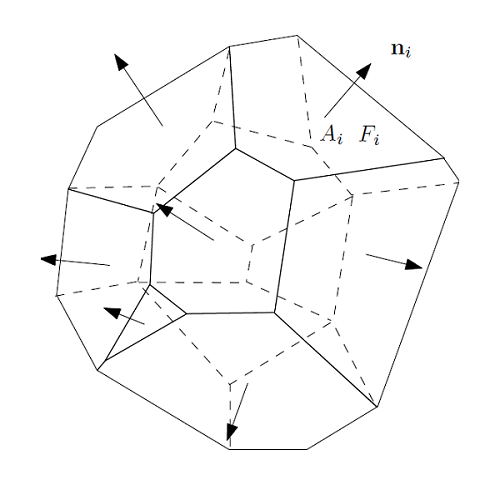
图3. 闵可夫斯基定理。
如图3所示,给定一个凸多面体,每个面的法向量已知,面积已知,所有面的面积和法向量的乘积之和等于0,闵可夫斯基(Minkowski)定理证明这样的凸多面体存在,并且彼此相差一个平移。
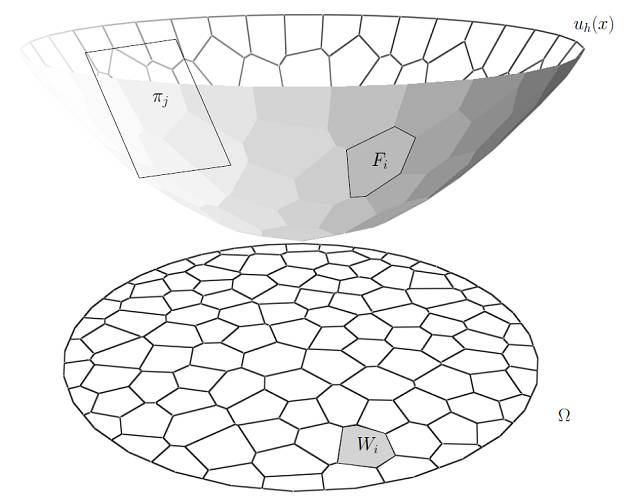
图5. 亚历山大定理。
闵可夫斯基的学生亚历山大(Alexandroff)将闵可夫斯基的结果推广到开的凸多面体,如图5所示。给定凸多面体每个面的法向量,和每个面向平面圆盘的投影面积,总投影面积等于平面圆盘面积,那么这样的凸多面体存在,并且彼此相差一个垂直平移。亚历山大在1950年给出的证明是基于代数拓扑原理,从中无法构造算法。2013年,丘成桐先生,罗锋,孙剑和老顾给出一个基于变分法的证明【2】。证明的大致思路如下:每个面的线性方程记为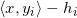
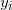
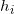
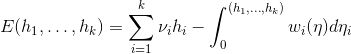
这里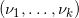

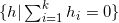
这一理论可以直接推广到任意维,证明不需要改动。
最优传输的Brenier理论和凸几何的Alexandroff理论本质上是等价的。下面我们来具体分析。

图6. 离散最优传输问题。
图6显示了离散最优传输问题。目标概率测度为离散的Dirac测度,
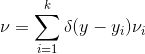
源概率测度是单位圆盘上的均匀分布。我们希望找到单位圆盘上的一个剖分,每个胞腔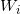
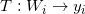
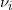
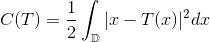
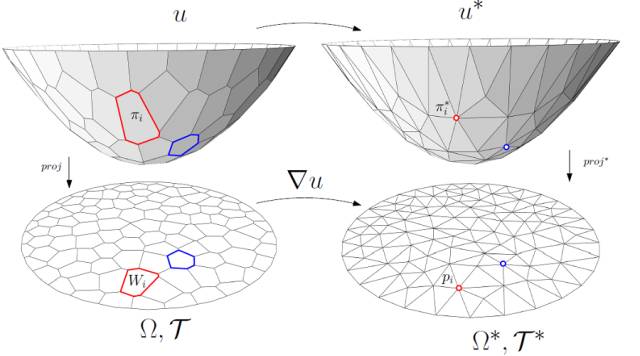
图7. 离散Brenier势能函数的构造。
根据Brenier理论,存在一个凸函数,其梯度映射给出最优传输映射。对于每一个目标点


图6. 最优传输映射的计算实例。
图6显示了这种方法的一个计算实例,首先我们将滴水兽曲面用黎曼映照映射到平面单位圆盘,黎曼映射的像如下行左帧所示,那么曲面的面元诱导了平面圆盘上的一个测度。平面圆盘上的欧氏面元定义了均匀测度。我们用上面讲述的变分法来构造平面圆盘到自身的最优传输映射,最优传输映射的像如下行右帧所示。那么最优传输映射的结果给出了从曲面到平面圆盘的保面元映射。
2014年,Goodfellow 提出了GAN的概念,他的解释如下:GAN的核心思想是构造两个深度神经网络:判别器D和生成器G,用户为GAN提供一些真实货币作为训练样本,生成器G生成假币来欺骗判别器D,判别器D判断一张货币是否来自真实样本还是G生成的伪币;判别器和生成器交替训练,能力在博弈中同步提高,最后达到平衡点的时候判别器无法区分样本的真伪,生成器的伪造功能炉火纯青,生成的货币几可乱真。这种计算机左右手互搏的对抗图景,使得GAN成为最为吸引人的深度学习模型。
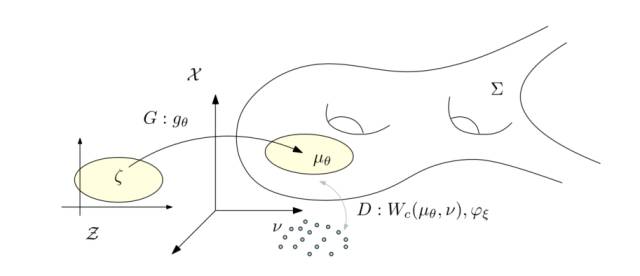
图7. WassersteinGAN的理论框架。
图7显示了Wasserstein GAN的理论框架。假设在隐空间有一个固定的概率分布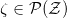
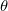
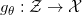
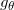
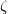
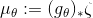
我们称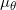

判别器计算测度间的Wasserstein距离,等价于求解Kantarovich势能函数。如果距离函数为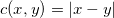
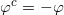
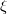
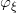
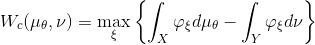
生成器极小化Wasserstein距离,
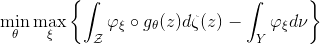
生成器极大化,判别器极小化,各自由一个深度网络交替完成。在优化过程中,解码映射
如果,我们用
这意味着:在最优情况下,判别器D由生成器G的结果直接给出;生成器G由判别器D的结果直接给出;判别器D和生成器G之间的对抗是虚拟的;判别器网络和生成器网络是冗余的。这和人们对于GAN模型生成器、判别器相克相生的想象大相径庭。
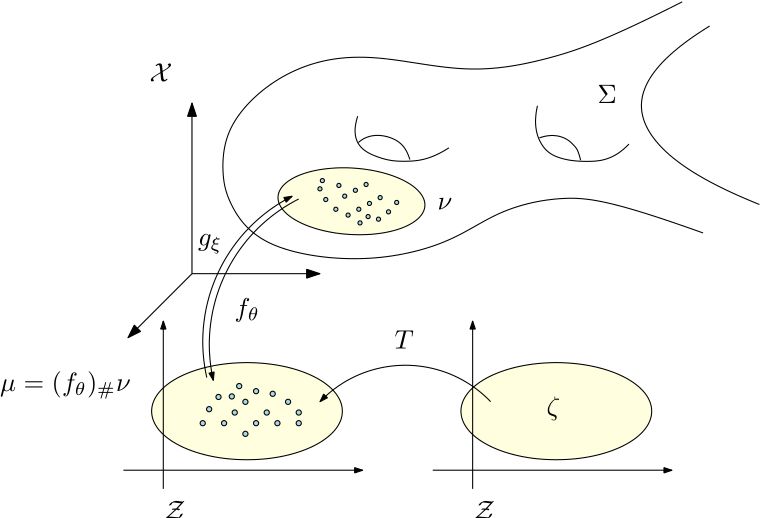
图8. 半透明深度网络模型。
传统的变分自动编码器VAE核心想法是将隐空间的概率分布变换成高斯分布,手法相当曲折。
因为概率变换可以用最优传输理论来清晰阐释,并且用牛顿法优化凸能量可以保证全局最优性,和高阶收敛速度,我们可以将深度学习中的概率变换部分分离出来,用透明的数学模型来取代,其他部分依然用传统的黑箱来运算,如此得到了半透明的网络模型【4】。
如图8所示,我们将GAN和VAE进行改进,流形的编码解码映射依然用autoencoder来计算,数据分布

real digits and VAE results

WGAN and AE-OMT
图9. 半透明网络的计算结果和其他模型的计算结果比较。
我们将半透明网络做为生成模型,在手写体数据集合上进行测试。如图9所示,半透明网络的计算结果优于传统的VAE和WGAN结果。

图10. VAE和半透明网络比较。
我们将半透明网络做为生成模型,在人脸图片数据集合上进行测试。如图10所示,半透明网络的计算结果优于传统的VAE结果。
最优传输理论可以用于解释深度学习中的概率分布变换。
References
Na Lei, Zhongxuan Luo, Shing-Tung Yau and David Xianfeng Gu. "Geometric Understanding of Deep Learning". arXiv:1805.10451 .
https://arxiv.org/abs/1805.10451
Xianfeng Gu, Feng Luo, Jian Sun, and Shing-Tung Yau. "Variational principles for minkowski type problems, discrete optimal transport", and discrete monge-ampere equations. Asian Journal of Mathematics (AJM), 20(2):383-398, 2016.
Na Lei,Kehua Su,Li Cui,Shing-Tung Yau,David Xianfeng Gu, "A Geometric View of Optimal Transportation and Generative Model", arXiv:1710.05488. https://arxiv.org/abs/1710.05488
Huidong L,Xianfeng Gu, Dimitris Samaras, "A Two-Step Computation of the Exact GAN Wasserstein Distance", ICML 2018.
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习


