7 Papers | 微信团队等NumNet论文;神经算术逻辑单元评价方法;将量子电路转为机器学习模型
机器之心整理
本周有一些较为前沿的研究成果,包括微信团队提出的 NumNet——即 DROP 榜首的 NumNet+的前身。还有关于量子计算、神经算术逻辑单元评价方法等方面的最新研究。
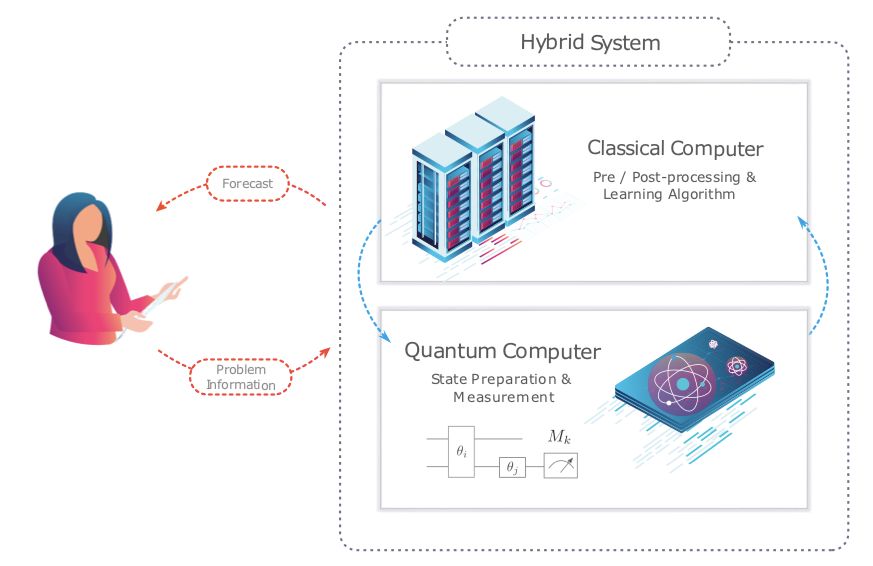
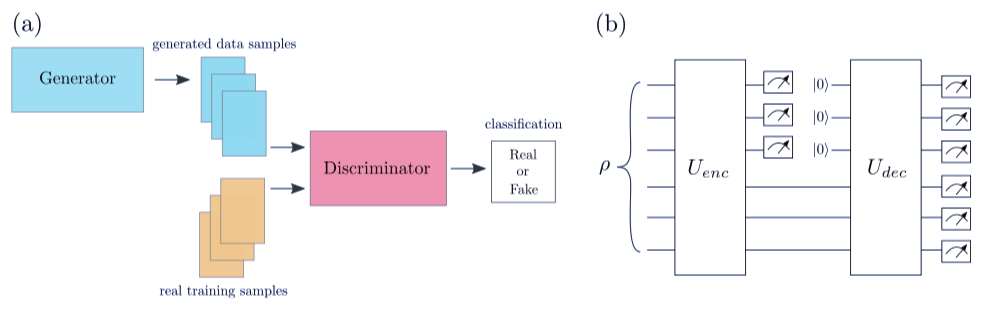
Parameterized quantum circuits as machine learning models
On Empirical Comparisons of Optimizers for Deep Learning
Measuring Arithmetic Extrapolation Performance
Stabilizing Transformers for Reinforcement Learning
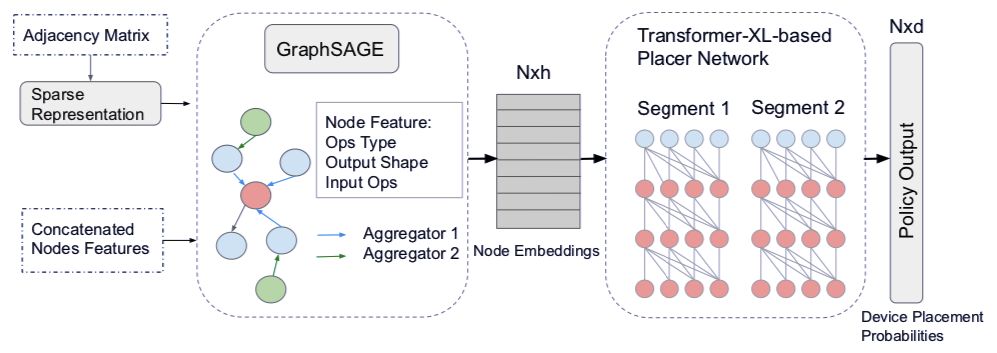
GDP:Generalized Device Placement for Dataflow Graphs
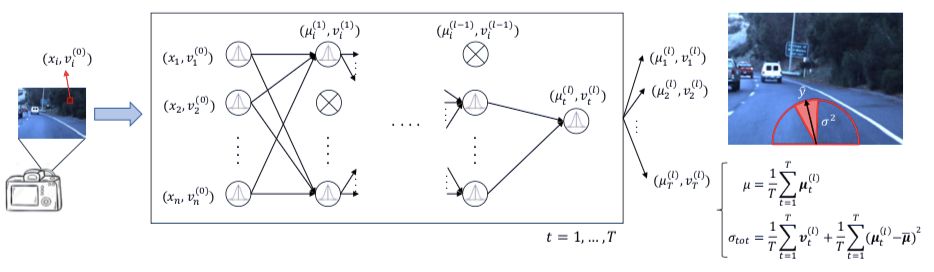
A General Framework for Uncertainty Estimation in Deep Learning
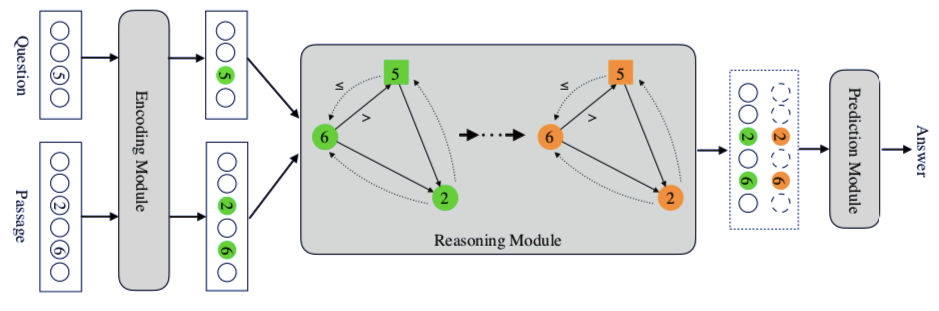
NumNet: Machine Reading Comprehension with Numerical Reasoning
作者:Marcello Benedetti、Erika Lloyd、Stefan Sack、Mattia Fiorentini
论文地址:https://arxiv.org/pdf/1906.07682v2.pdf
作者:Dami Choi、Christopher J. Shallue、Zachary Nado等
论文地址:https://arxiv.org/pdf/1910.05446.pdf
作者:Andreas Madsen、Alexander Rosenberg Johansen
论文地址:https://arxiv.org/abs/1910.01888
作者:Emilio Parisotto 等
论文地址:https://arxiv.org/abs/1910.06764
作者:Yanqi Zhou 等
论文链接:https://arxiv.org/pdf/1910.01578.pdf
作者:Antonio Loquercio、Mattia Segu、Davide Scaramuzza
论文地址:https://arxiv.org/pdf/1907.06890v3.pdf
作者:Qiu Ran, Yankai Lin, Peng Li, Jie Zhou, Zhiyuan Liu
论文地址:https://arxiv.org/pdf/1910.06701.pdf