作业帮基于 StarRocks 画像系统的设计及优化实践

作业帮为提高孩子学习效率通过搜索、答题、咨询等各种行为数据以及辅导效果等结果数据,利用算法、规则等技术手段建立用户画像,用于差异化辅导提升学习效率。我们根据画像标签特点并结合 StarRocks 能力建设了一套相对适合全场景的画像圈人系统。本文主要介绍此画像服务、标签接入的系统设计及圈人性能优化方式。
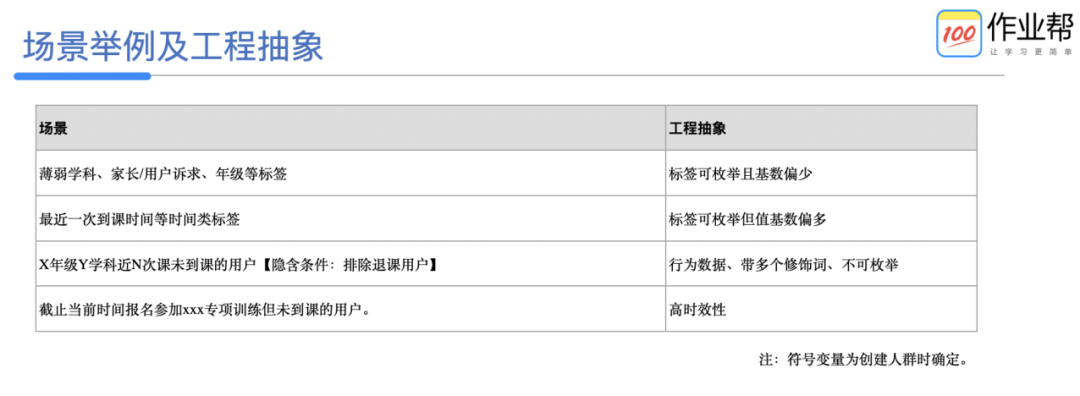
注:符号变量为创建人群时确定。
为保证系统支持业务需求灵活可扩展、架构合理、实现后系统稳定且性能满足预期,在设计前梳理相关问题及思考。
如果满足以上全部标签类型,常规大宽表、标签 bitmap 化设计无法满足需求。需要将带有修饰词的行为类数据和常规标签做交叉,而往往两类数据存储在不同的表或数据结构中,同时支持秒级查询利用常规 join 又无法满足,最合理的方式仍然是利用 bitmap 的交叉能力,针对不同规则人群分别形成 bitmap,然后结果交叉。而使用 bitmap 结构就必须将用户唯一标识字符串 cuid 转化为数值类型 guid。
如何将用户唯一标识转化为数值型全局唯一自增 guid,并且实时和离线标签要采用同一套映射关系。离线时效性不够所以必须采用实时方案形成映射关系,然后同步到离线 hive 用于补充离线标签,映射必须覆盖实时和离线标签全部用户 id。
标签会越来越多而且每个标签基本都需要经过生产计算、补充 guid、数据校验报警、写入存储、原子切换上线等一系列操作,同时需要控制新增标签的接入成本和后期维护成本。为此需要将标签生产部分和标签接入部分解耦,抽象接入流程,按照指定规范实施,尽可能做到标签配置化接入,统一化管理,支持长线平台化建设兼容。标签生产也可按照业务方向多人并行落地。
性能方面保障需要利用真实数据做相关测试,并保证每个环节设计可按照资源扩展线性提高相关处理能力。例如数据入库、圈人查询、实时 cuid->guid mapping 等。
稳定性方面保障需要针对关键环节配置相关监控报警,设置预案并做故障演练。
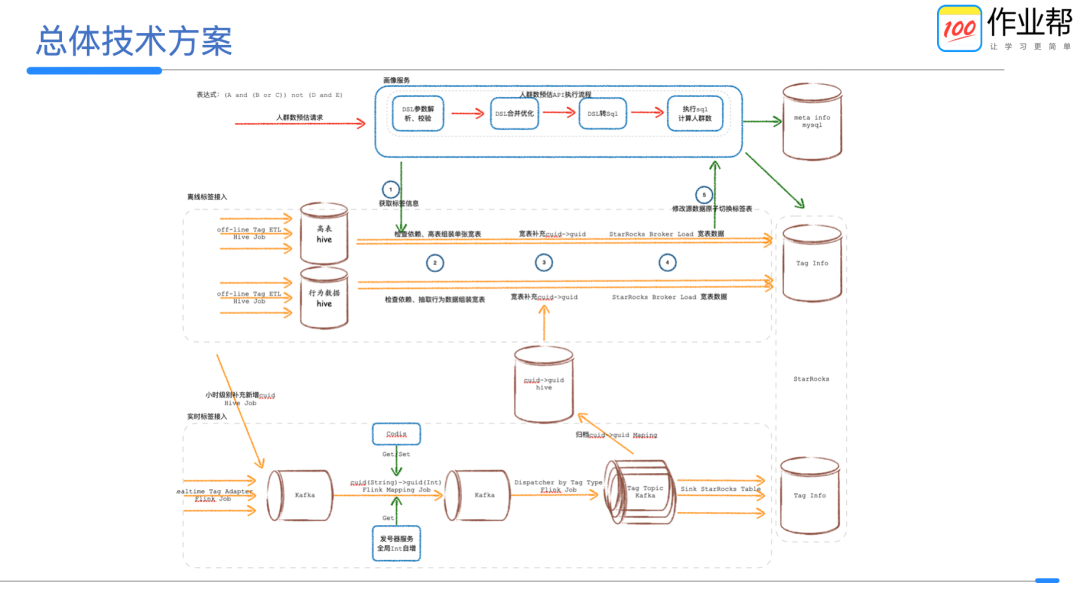
大概由画像服务、实时标签接入、离线标签接入三部分组成。
(1)画像服务主要承担标签配置管理、标签枚举值解释映射、人群圈选人群包管理、其他功能系统对接、标签数据接入配置管理及快速回滚能力等。
(2)实时标签接入主要负责标签接入规范、cuid->guid 映射及备份、标签实时入库三部分。通过抽象工具,任务可配置化完成。
(3)离线标签接入主要负责标签接入规范、配置化接入(标签数据组装、cuid->guid 映射、校验、监控、入库等)。
StarRocks 作为全场景 MPP 数据库,支持多种表模型、秒级实时分析、并发查询等能力,同时又具有 bitmap 存储结构和配套的 UDF 函数,降低了对 bitmap 存储、交叉、管理等方面的工程复杂程度,所以我们最终选用 StarRocks 作为标签的存储。
根据需求场景、性能、灵活性等方面因素考虑,将标签信息抽象为如下几类进行存储。每个分类会对应一个查询模板解决不同业务场景问题。因读写性能、标签更新时效、幂等接入等因素考虑,同一个类型支持了多个 StarRocks 表模型,同一标签也可存储在不同业务类型表中。
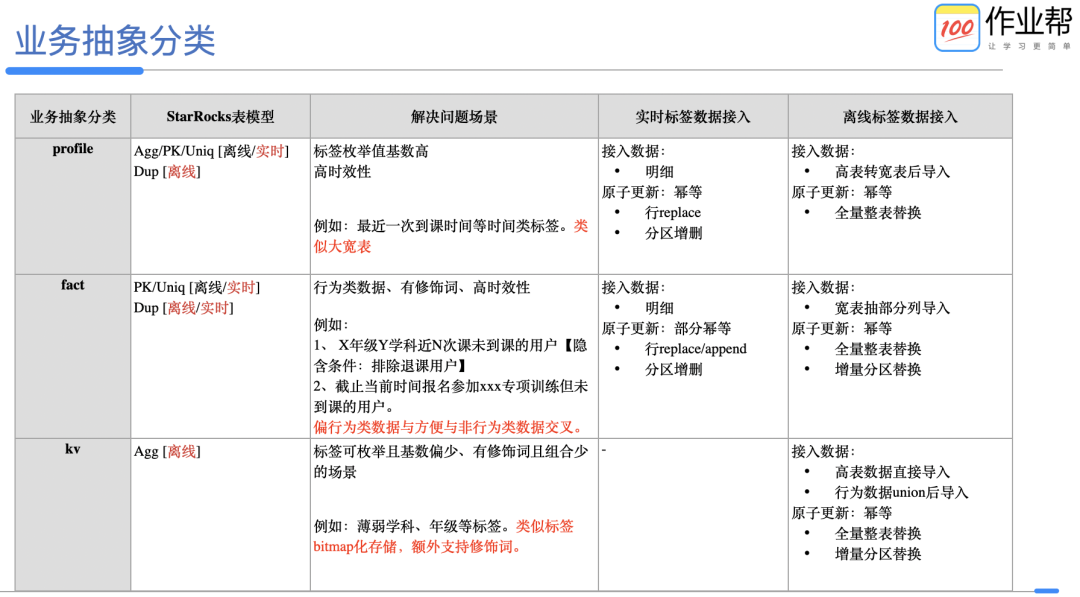
画像服务核心能力有两个。第一个人群圈选能力,特点为内部系统 qps 不高,秒级返回。第二个单用户 id 规则判定能力,特点为 qps 很高,10 毫秒级返回。第二个不在本系统设计范围内,只说人群圈选部分,大体执行过程如下:
请求 DSL 参数解析及校验:将人群圈选 DSL 按标签拆分为多个独立的表达式和组合关系,然后根据标签配置信息补充隐含条件,同时校验每个表达式的合理性。
查询逻辑优化:标签同表存储时合并表达式,减少单表达式数据返回量加速查询速度。
表达式转 SQL:根据抽象类型对应的查询模板,将优化合并后的表达式分别转化为多个子查询,然后结合组合关系形成整条 SQL 。
执行 SQL 圈选人群。
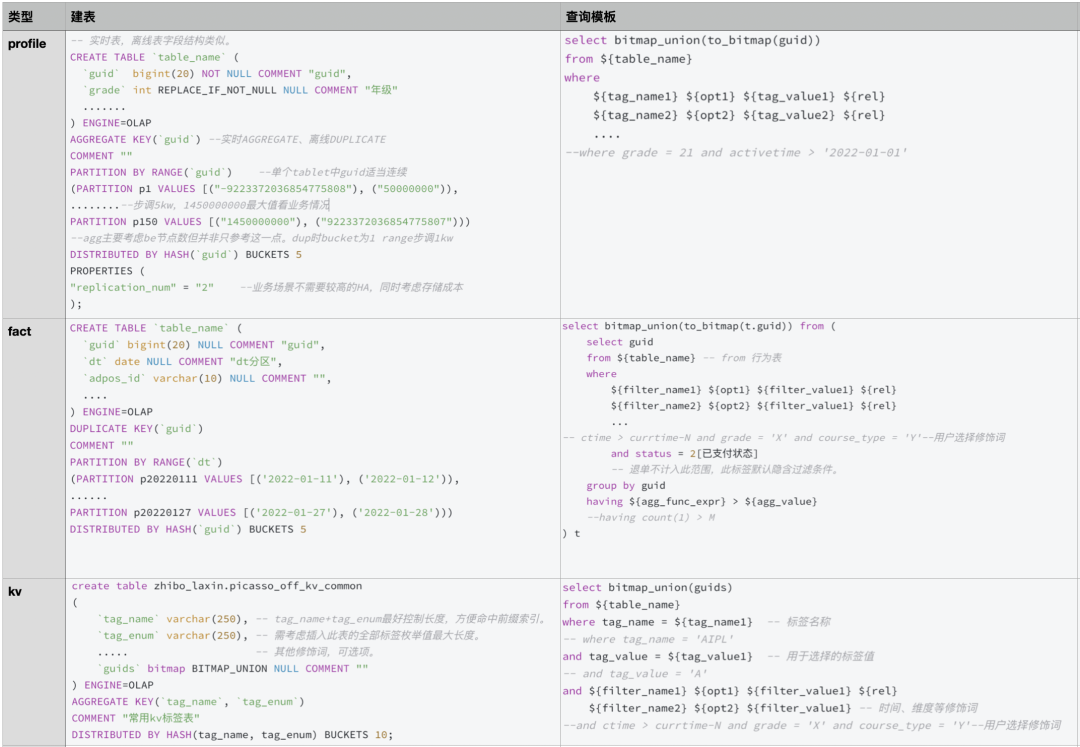
(1)Profile + Agg 测试
实时场景未采用 PK 主要因为不支持 REPLACE_IF_NOT_NULL 和局部列更新,标签间入库解耦需要此能力。性能测试如下:
测试所用集群:32C 96G 1TSSD * 5台,3个FE,5个BE,5个Broker。1.19.5版本表数据:2.58亿行,3个指标列,单副本约1.7G,AGGREGATE KEY(`guid`), DISTRIBUTED BY HASH(`guid`),数据分布均匀。1.profile_b5表 bucket 5 共5个tablet 每个tablet 365M2.profile_b20表 bucket 20 共20个tablet 每个tablet 95M3.profile_b5_p5kw表 bucket 5 共30个tablet 每个tablet 67M1)profile_b5_p5kw表中adpos_id、unit_id加bitmap索引。2)profile_b5_p5kw表按PARTITION BY RANGE(`guid`) 每5kw一个分区。测试数据说明:Fragment 1有5个instance,下边均采用ip为211的instance相关数据。Fragment 0有1个instance,直接引用结果。数据均为多次查询后取相对合理且耗时较少的profile信息此测试前已有认知:离线标签采用profile+dup模型测试bitmap_union(to_bitmap(guid))性能,单BE 1个instance 1500W/s,to_bitmap耗时是bitmap_union耗时的2倍左右,两个算子耗时主要由guid数量决定。bitmap_union算子耗时与单个tablet内guid集中度有关,guid取值范围越集中性能越好,建表时采用Range guid分区,步调1000W,bucket为1。
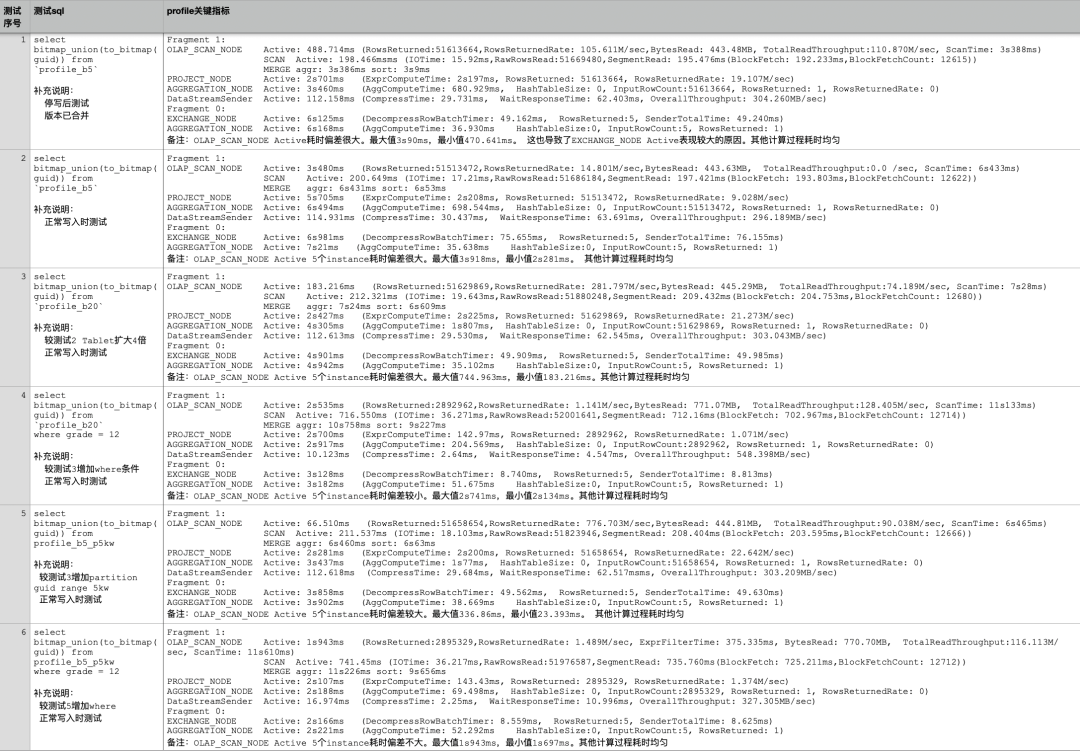
结论 1:测试 1/2 可知查询耗时点为 Fragment 1 阶段 Scan 操作含 Merge-on-Read 过程 [OLAP_SCAN_NODE]、to_bitmap[PROJECT_NODE]、bitmap_union[AGGREGATION_NODE],而 Fragment 0 阶段因数据量很少所以耗时很少。
结论 2:测试 2/3 对比考虑优化 Scan 耗时。增加 bucket 数量后,Scan 耗时明显下降。tablet 数量增加引起 scan 并行度提高。doris_scanner_thread_pool_thread_num 默认 48,tablet 数量调整前后为 5->25 均在此范围内,除 profile 信息外还可以通过 Manager 查看对应时间 Scan 相关监控。可根据集群负载情况适当增加线程数用于提高查询速度。
结论 3:测试 3/5 对比考虑优化 bitmap_union 耗时并兼顾写负载平衡。采用 Range guid 分区,5kw 一个步调,bucket 设为 5。每个 tablet 大约 1kw 数据量且差值低于 5kw,避免部分 guid 活跃度高带来的单分区写热点问题。同为 5160W+ 数据量 bitmap_union 耗时减少约 700ms。
结论 4:测试 3/4 对比考虑加上 where 条件后的查询耗时表现,因返回数据量降低一个数量级 bitmap_union(to_bitmap(guid)) 耗时明显减少,性能瓶颈主要表现在 Scan 阶段。因增加 where 条件后多扫描了 grade 列,增加耗时部分主要消耗在此列的数据扫描和 merge 过程,暂无较好优化方式。
(2)Fact + Dup 测试
实时场景 Fact + Agg/Uniq 和 Profile + Agg 情况差不多,相关优化可结合上边结论。针对离线场景 Fact + Dup 模型测试数据如下:
测试所用集群:32C 96G 1TSSD * 5台,3个FE,5个BE,5个Broker。1.19.5版本表数据:按日期天级别分区、3个分区有数据,每个分区3.4亿,DUPLICATE KEY(`guid`), DISTRIBUTED BY HASH(`guid`),其他字段见上边建表sql。测试过程无数据写入。dup表:bucket 5。共15个tablet,每个tablet 450M,单副本数据分布均匀,总大小6G左右dup_b5表:bucket 20 共60个tablet,每个tablet 110M,单副本数据分布均匀,总大小6G左右dup_bitmap表:bucket 5。共15个tablet,每个tablet 670M,单副本数据分布均匀,总大小9G左右,adpos_id、unit_id加bitmap索引测试数据说明:Fragment 2/1有5个instance,下边均采用ip为211的instance相关数据。Fragment 0有1个instance,直接引用结果。数据均为多次查询后取相对合理且耗时较少的profile信息。

结论 1:测试 1/2 可知查询耗时点为:
Scan 过程 [OLAP_SCAN_NODE]。
两阶段 group by guid [Fragment2 AGGREGATION_NODE 和 Fragment1 的第一个 AGGREGATION_NODE]。group by 耗时主要为 HashTable 构建时间含 count(1) 结果更新,本质取决于 scan 返回数据条数以及 HashTableSize 大小 。
to_bitmap[Fragment1 的第一个 PROJECT_NODE] 和 bitmap_union[Fragment1 的第二个 AGGREGATION_NODE] 算子,总体优化思路见上边测试结论。结论 2:测试 2/3 分析无论是否增加 bitmap 索引,查询都有一定程度的下推到存储层【simd filter】,增加 bitmap 索引但未应用,因区分度太低而不走 bitmap 索引【过滤条件枚举值数量 / 总数据条数 < 1/1000 ,可通过 bitmap_max_filter_ratio 参数调节】,但执行计划发生变化 bitmap 表少了一次 group by agg 操作,就总体查询耗时变化不大。同时增加 bitmap 索引后存储成本增加,所以不增加 bitmap 索引。
结论 3:[推测未做测试] 针对测试 1 DUPLICATE KEY(guid), DISTRIBUTED BY HASH(guid) ,如果不用 guid 作为排序列和分桶使数据分布均匀那么会因为每个节点都有全部 guid 导致 HashTableSize 基本为现在节点的 5 倍,进而影响查询耗时会更长。
结论 4:测试 4 分析 fragment 1/2 实际并行度计算公式如下。适当增加 tablet 个数【partition、bucket】和 exec instance num 可以加快查询速度。此加速过程会作用于结论 1 中全部耗时点。
当 tablet 个数【不含副本】小于 parallel_fragment_exec_instance_num * BE 个数时取 tablet 个数
当 tablet 个数【不含副本】大于 parallel_fragment_exec_instance_num * BE 个数时取 exec_instance_num * BE 个数
(3)kv + Agg 测试
此部分主要用于存储标签枚举值较少的用户集合,所以数据量并不多,基本 1s 内返回。
根据查询模板猜测当数据量较大时可能的性能瓶颈点主要:
Scan 过程 [OLAP_SCAN_NODE]:bitmap 对象反序列化和 SegmentRead 过程。可考虑用 enable_bitmap_union_disk_format_with_set 优化。
bitmap_union 算子,如果按照上边优化方案调整 bitmap 元素分布就需要在表中增加更多行的数据性能未必会好。需要测试看数据后选择平衡。
(4)补充说明
遇到的坑 :
查询 bitmap_or(to_bitmap(字段 A),to_bitmap(字段 B)),字段 A/B 有空值时计算错误。通过 ifnull(to_bitmap(字段名),bitmap_empty()) 解决。
Uniq 模型多副本排除外部干扰的情况下,5be 节点、无分区、bucket 为 5、副本数为 2,数据分布均匀、tablet 状态正常。查询时会出现 4 个 Be 节点工作,其中一个扫描 2 个 tablet,BE 接收的 task 分布不均匀的情况导致总体耗时变长。已反馈 StarRocks 同学。
增加 where 条件后比全量扫描 Scan 耗时多不太合理。见 profile 类型性能测试结论 4 和 fact 类型性能测试结论 1 相关测试。应该可以通过 simd 过滤 where 部分数据,这样 merge 过程数据量就会减少可降低查询耗时。已反馈 StarRocks 同学。
测试为排除 be 任务调度不均匀的情况造成测试不准确,全部采用单副本进行。
优化思路主要是依据对 StarRocks 及其他 OLAP 技术的认识,猜测执行过程思考优化方式,结合具体测试并查看 explain、profile、manager 监控来验证效果迭代认识以达到优化效果。
实时标签接入大概分为一个规范和三类 Flink 工具任务。规范指实时标签计算后写入指定 Kafka Topic 规范。三类 Flink 工具任务指 1. cuid->guid mapping 过程。2. 根据标签类型进行数据分发。3. 各标签数据独立写入到 StarRocks 表。注意全流程按照 cuid 做 kafka partition 分区保证顺序。
标签计算类任务将标签结果统一输出为如下格式,写入指定 kafka topic,并按照 cuid 分区。
-
{"header":{"type":"", "cuid":"cuid"}, "body":{"xxx":"xxx",...}}type表是标签类型,全局唯一。sys_offline_cuid、sys_cguid_mapping 为 type 保留字用补数和新映射数据输出。
body 为标签的结果数据,接入过程不做额外处理。
mapping 过程逻辑非常简单就是获取全局自增数值型 guid 和 cuid 形成一一映射关系。此过程大体存在如下几步 1. 查 task LRU 堆外内存 2. 内存不存在查 codis 3.codis 不存在通过发号器取新号 4. 逐层缓存 mapping 信息。
此过程稳定性是整个系统的关键,结合作业帮已有的发号器和 codis 能力作为选型的主要参考。利用发号器产生全局唯一自增数值 id guid,利用 codis 存储 cuid 与 guid 关系。为保证一一映射关系将 mapping 过程设计为一个 flink 任务。思考如下:
业务实际情况:
cuid 总量 十亿级,日增百万高峰期每小时新增 20W 每秒 30+。全量实时标签数据最高 10W qps
理论资源测算:
发号器:默认支持 3W qps,数据第一次初始化耗时 十几个 小时,之后最高 qps 不需额外资源即可满足需求。
codis:十亿级 mapping 数据存储约 200G【未考虑 buffer 部分】,12 个 pod 每个 pod 16G 内存大约可支持 50W qps。
flink 任务:
qps 取决于上游 kafka 写入的标签数据量约 10W qps。
计算由近 N 个月活跃 cuid mapping 总内存占用除以每个 task 500M 到 1G 堆外内存得到数值 A,和上游 kafka 数据 10W qps 除以在确定内存命中率时单个 task 可处理的 qps 得到数值 B,然后可算出 flink 并行度 max(A, B) + 对业务预期发展给予一定 buffer 决定。
上游 kafka topic 需按照 cuid 分区并且分区数最好为 flink 并行度的 3 倍以上【取决于后续新增标签数据量】。
任务重启后对 codis 产生的最大 qps 小于 10W,如果 flink task LRU 缓存足够平时 codis qps 最高基本在 万级别以内,就目前 codis 资源配置已满足需求。
任务本身只关注 cuid,除 cuid 以外数据可不做解析。
潜在风险思考:
数据延迟:因使用场景更多用于触达,一定程度的延迟可以接受,较大延迟触发报警暂停触达。
cuid 脏数据,当 guid 超过 Integer.MAX_VALUE 后 StarRocks bitmap 查询性能下降。增加 cuid 严格校验逻辑,根据业务实际情况设置每天 cuid 增量监控,超过后人工排查,如果 cuid 脏数据不多时可不做处理,因错误 cuid 并不会收到触达信息。如果 cuid 脏数据较多时需要重置发号器位置并恢复到某一时间点数据后重刷全部标签、人群包数据。
codis+ 发号器替换为 mysql 主键自增,此方案并未经过实际测试就目前的场景是可以满足需求的,弊端在于 flink 任务重启后会对 mysql 造成比较大的冲击【flink 增量 checkpoint 无人维护存储所以暂未使用】,做好 mysql qps 限流后会造成一段时间的数据延迟。好处在于任务实现简化同时可以避免一些特殊情况导致的同一 cuid 被分配多个 guid 造成数据错误的情况。
根据标签类型将 mapping 后的数据分发到独立的 kafka topic,方便写入 StarRocks 时表级别管控。
利用 flink-starrocks-connector 将标签数据写入 StarRocks。注意考虑写入频次、数据行数、数据大小等参数配置。
实时已接入激活标签流数据,为防止出现遗漏及第一次初始化数据采用小时级增量补实时未覆盖的 cuid。
常规标签数据当计算完成后可统一写入指定的高表【建表语句见下方】中,以高表为媒介做到标签开发和接入的解耦。带有修饰、行为类标签数据可直接利用基础数仓表和标签源数据信息完成自动接入。
离线接入大概分为两类数据源,高表接入、数仓行为数据接入。
高表接入
标签计算后写入高表【已按 cuid 排重】,tagkv 为 map 结构,其中 key 为标签名字。
高表中如果存增量数据数据接入走增量逻辑,如果为全量标签走全量接入逻辑。
-
hive 建表 sqlcreate table picasso_all(
cuid string comment '同用户唯一标识体系下的唯一 id',
tagkv Map<string, string> comment '组合标签 kv 数据'
)
partitioned by (dt string, tagk string)
stored as parquet
数仓行为数据接入:
只能应用于单表且需包含 cuid
任务入口:通过画像服务接口获取需要导入的目标表名字,然后通过调度系统 api 创建并行接入任务,以下为每个任务的执行逻辑 。
状态检查:根据目标表名通过画像服务接口获取需要导入此表标签对应的数据来源信息、hive 字段映射等信息【目前仅支持 hive 数据源】,检查依赖数据状态。
数据校验:以元数据配置规则为标准校验标签数据,例如标签枚举值合理性、数值型标签取值范围、空值率等。
数据组装:根据不同业务场景利用 insert overwrite directory select 组装数据【场景匹配 sql 模板、补充 guid 等】并写入 cos/hdfs 等存储。
数据导入:建表 / 分区,利用 StarRocks Broker Load 方式导入数据。
原子切换:调用画像服务接口,接口内完成表相关字段校验、与线上数据交换临时分区 / 表,归档临时分区 / 表用于回滚
恢复现状:删除此过程中产生的临时文件。

标签内容还需持续迭代,此部分主要为业务需求驱动。
单用户规则判定能力支持,用于解决例如某种活动、权益等参与资质判定。
标签数据多表冗余,根据人群圈选 DSL 支持自动化路由查询,以加快人群数计算速度。
实时、离线标签接入目前是通过通用化工具实现,可考虑和调度系统、数据地图系统打通进一步打通,实现标签生产、接入平台化。
标签准确是核心,为保证准确性还需要丰富标签接入过程的数据校验部分,支持更多数据校验方式比如分布同环比等。
作者介绍:
孙建业,2019 年加入作业帮,先后负责多条业务大数据建设。
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
俄罗斯或断开全球互联网引发关注;谷歌云业务支持部门裁员;工信部:不得要求用户不下载App就不给看全文 | Q资讯
Oracle等科技巨头对俄罗斯祭出“极限制裁”,我们能从中获得什么启示?
号外号外,首届写作平台 InfoQ 会员周上线啦!3 月 7 日 -3 月 13 日,参与活动即可抽苹果 Airpods 耳机、华为手环 6、JBL 蓝牙智能音箱……限时 7 天速速参加 http://gk.link/a/11dRl



