从托管到原生,MPP架构数据仓库的云原生实践

一 前言
二 ADB PG云原生架构
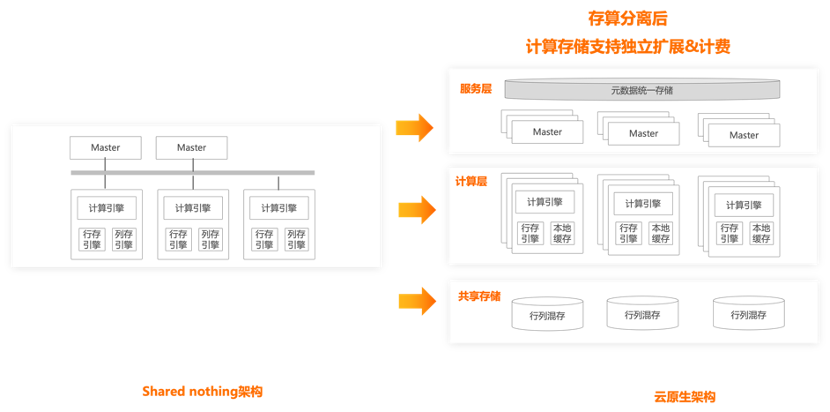
-
一个是文件与表的关系 -
另外一个是被删除的数据的delete bitmap
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三 关键技术
1 弹性伸缩
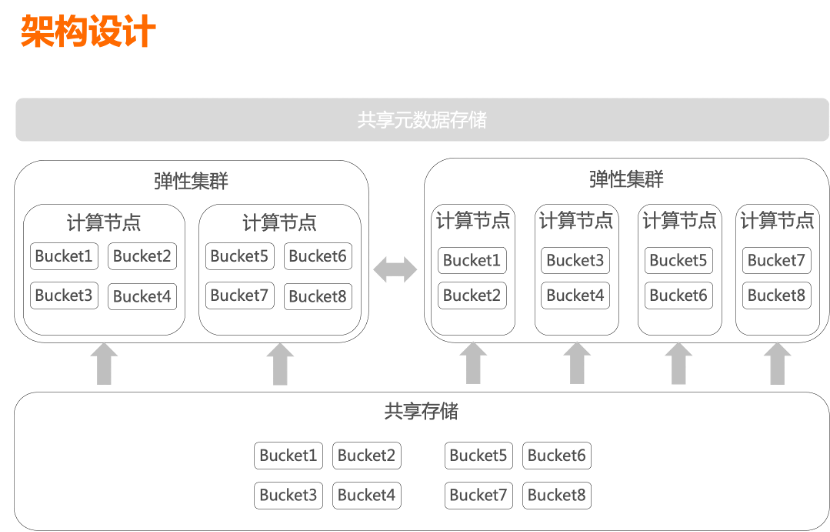
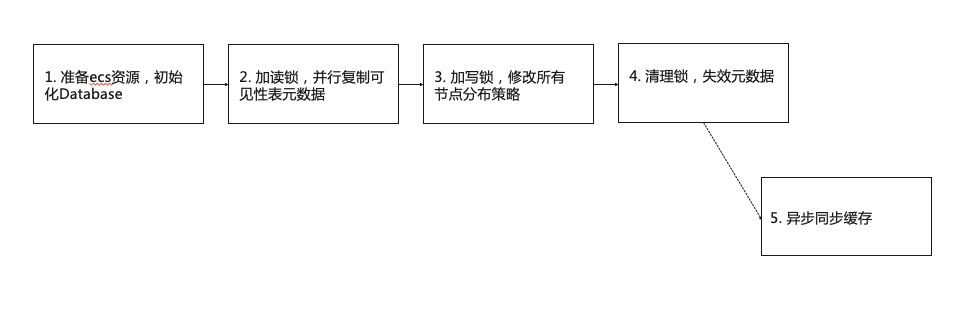
2 分层存储
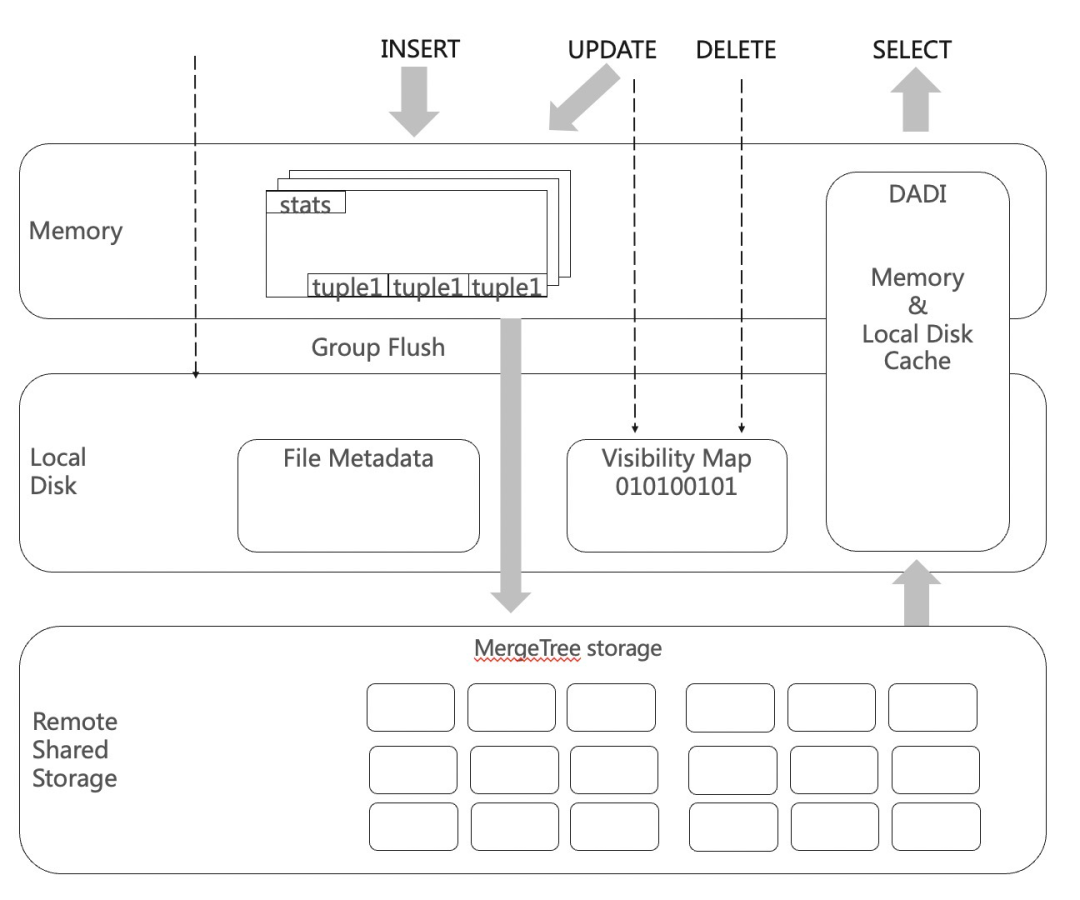
3 读写流程
-
用户写入数据通过数据攒批直接写入OSS,同时会在本地磁盘上记录一条元数据。这条元数据记录了,文件和数据表的对应关系。元数据使用PG的行存表实现,我们通过file metadata表来保存这个信息。
-
更新或者删除的时候,我们不需要直接修改OSS上面的数据,我们通过标记删除来实现,标记删除的信息也是保存在本地行存表中,我们通过visibility bitmap来存这个信息。标记删除会导致读的性能下降,我们通过后台merge来应用删除信息到文件,减少删除带来的读性能影响。
-
我们通过读取file metadata表,得到需要扫描的OSS文件。
-
根据OSS文件去读取对应文件。
-
读到的文件通过元数据表visibility bitmap过滤掉已经被删除的数据。
4 可见性表
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5 行列混存
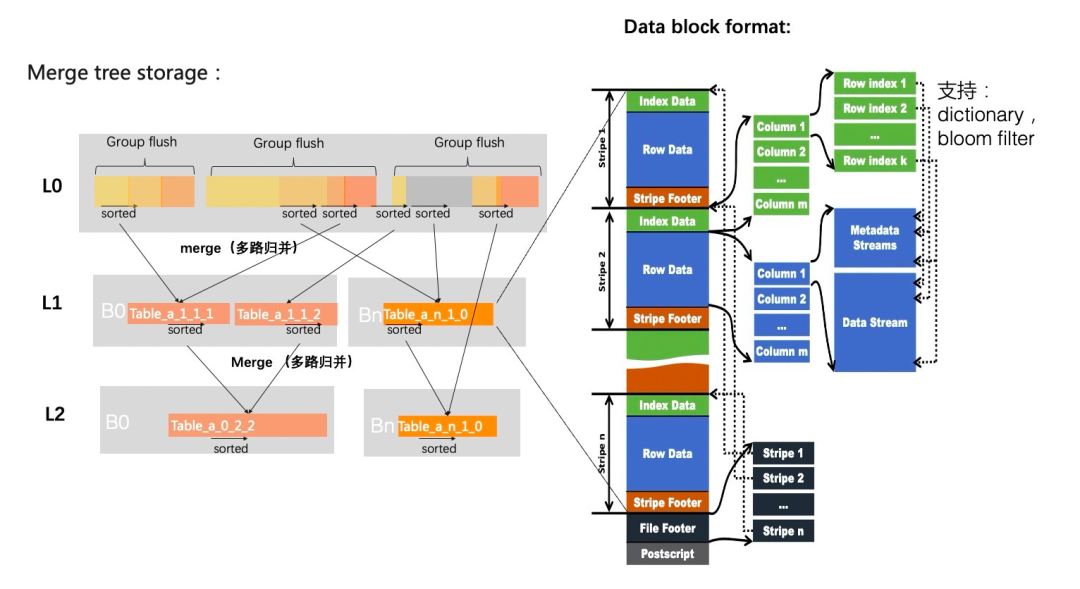
6 本地缓存
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
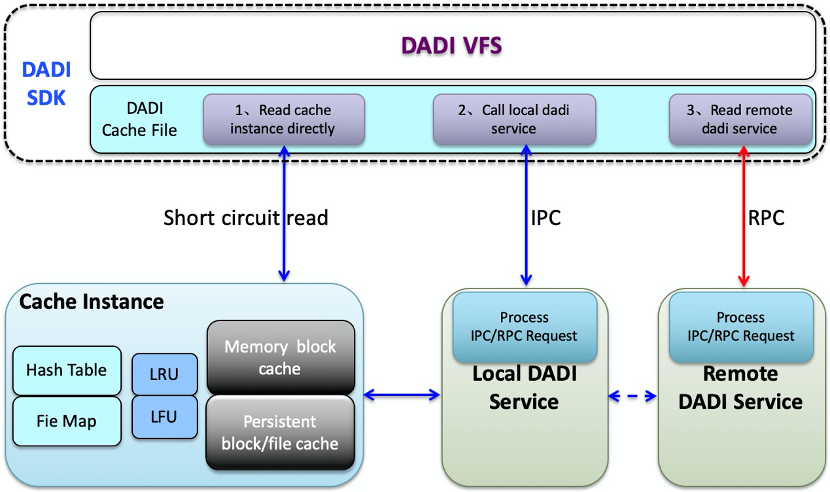
7 向量化执行
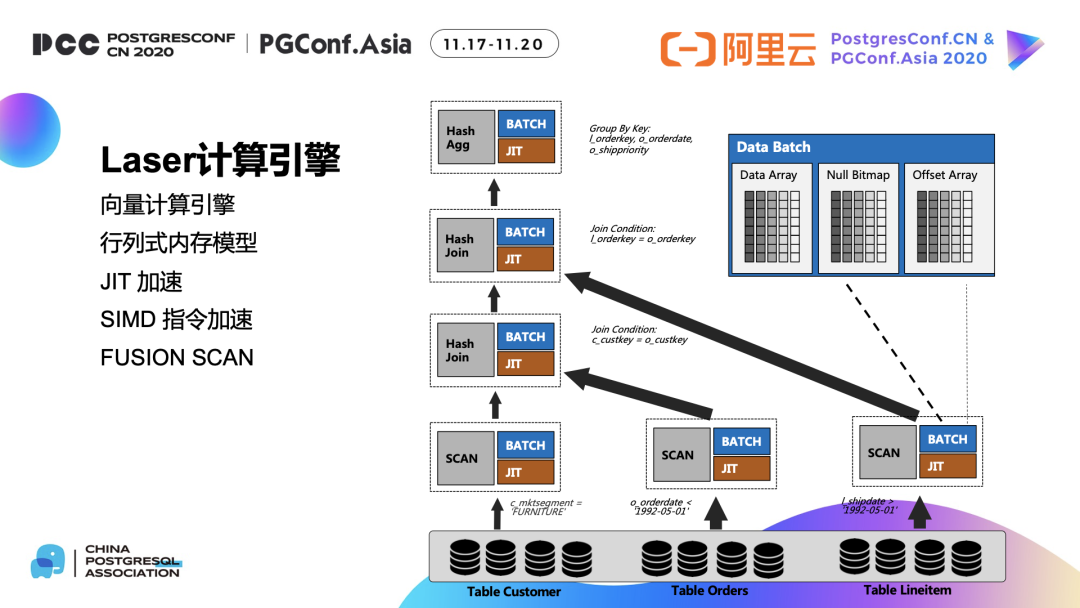
8 有序感知
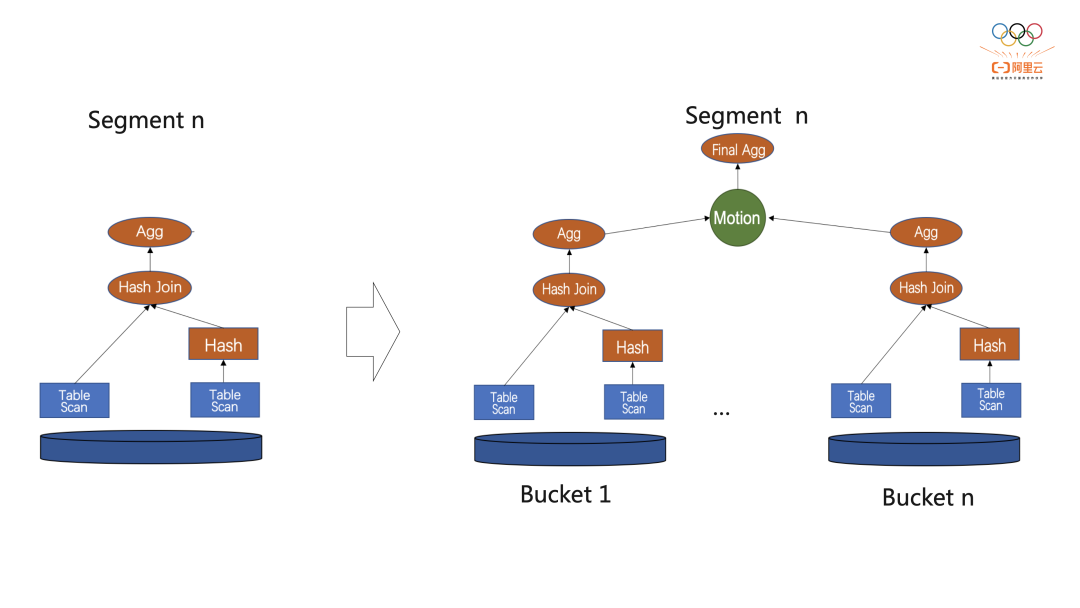
9 细粒度并行
四 性能结果
1 扩缩容性能
|
|
|
|
|
|
|
|
|
|
|
|
2 读写性能
写性能测试
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
在单并发下新版本与存储弹性版本的性能差不多,主要在于资源都没有满; -
在4并发下新版本的吞吐是存储弹性的2倍,原因在于使用lineitem表都定义了sort key,新版本在写入数据无需写WAL日志,另外攒批加上流水线并行相比弹性存储版本先写入,再merge,merge的时候也需要写额外的WAL有一定优势; -
在8并发下新版本与4并发差不多,主要由于4C 4并发已经把CPU用满,所以再提升并发也没有提升。
读性能测试
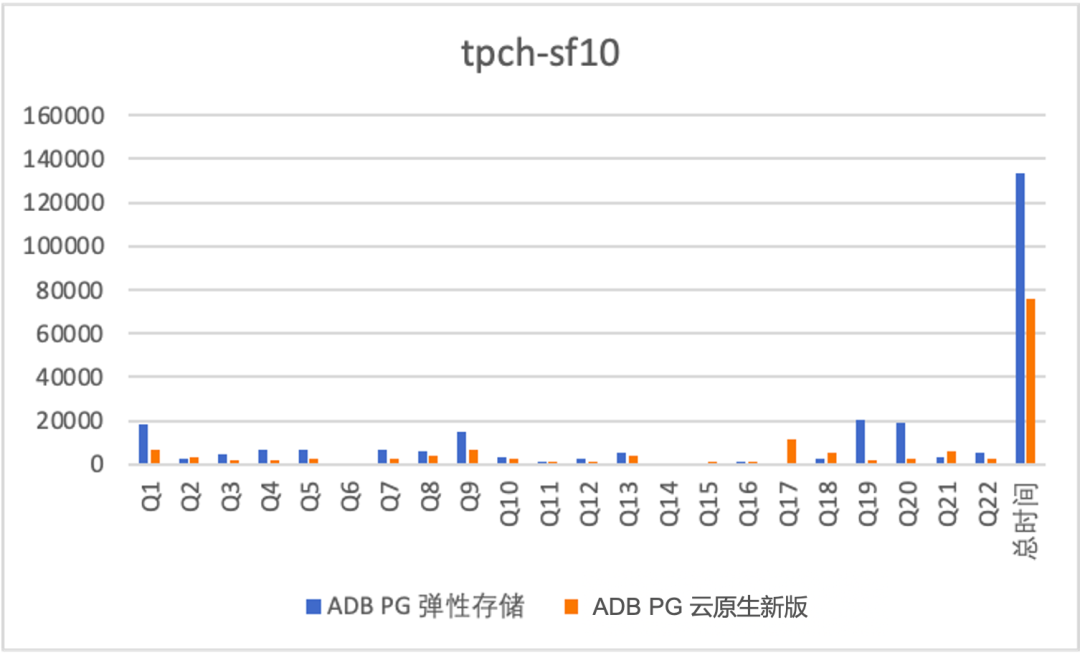
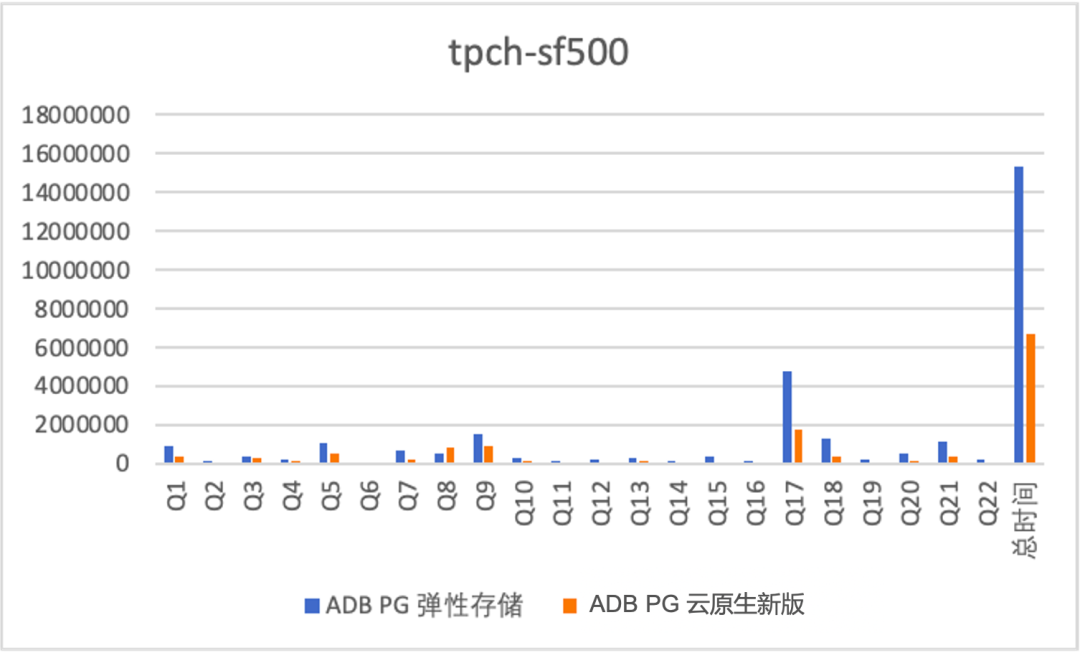
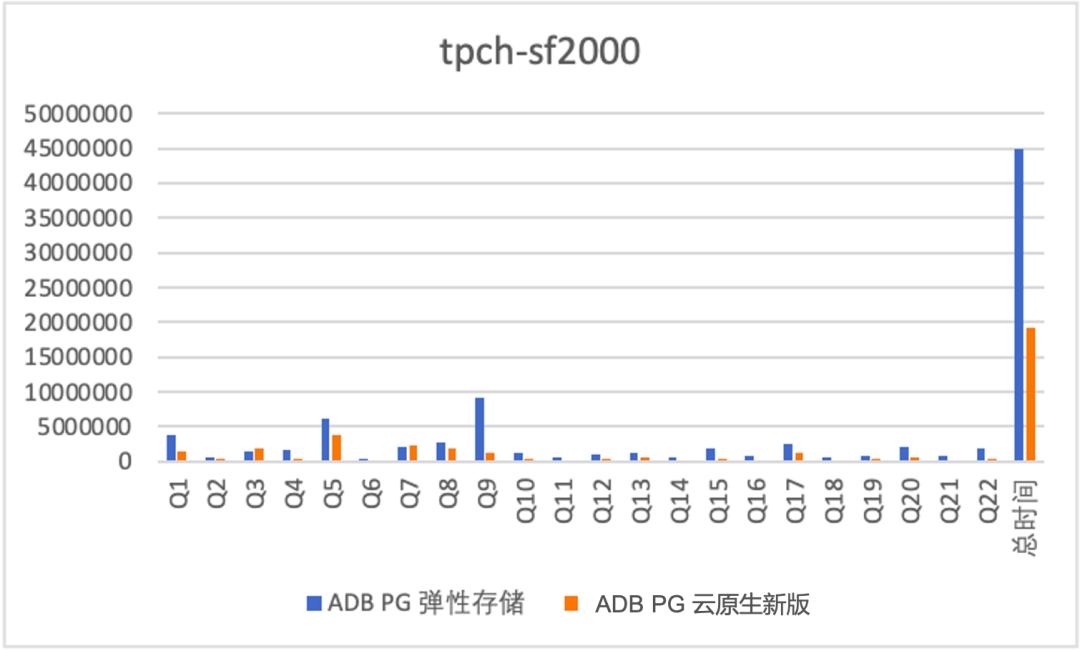
-
云原生版本对比老的弹性存储版本均有1倍多的性能提升,原因在于细粒度并行带来的加速效果; -
对于TPCH这种计算密集型的作业,即使数据一半缓存,一半OSS性能也不错,sf 2000数据量是sf 500的4倍,rt增加到原来的2.8倍,主要原因在于4*4C规格的实例没有到OSS的带宽瓶颈,另外由于本身读取的预取等优化。
五 总结
-
通过存储计算分离,用户可以根据业务负载模型,轻松适配计算密集型或存储密集型,存储并按使用计费,避免存储计算一体僵化而造成的资源浪费; -
动态的适配业务负载波峰和波谷,云原生MPP架构计算侧使用了shared-nothing架构,支持秒级的弹性伸缩能力,而共享存储使得底层存储独立不受计算的影响。这降低了用户早期的规格选型的门槛,预留了后期根据业务的动态调整灵活性; -
在存储计算分离基础上,提供了数据共享能力,这真正打破了物理机的边界,让云上的数据真正的流动了起来。例如数据的跨实例实时共享,可支持一存多读的使用模式,打破了传统数仓实例之间数据访问需要先导入,再访问的孤岛,简化操作,提高效率,降低成本。
六 后续计划
云原生版本将于2022年2月正式商业化发布,想要更多信息可以访问产品网站
https://www.aliyun.com/product/gpdb
七 引用资料
关系型数据库课程
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文