一 背景
-
首先详细阐述,在大规模订单系统中,存在哪些需求,存在哪些痛点。
-
进而比较传统的架构,其现状如何,各存在什么样的劣势,无法满足哪些需求。
-
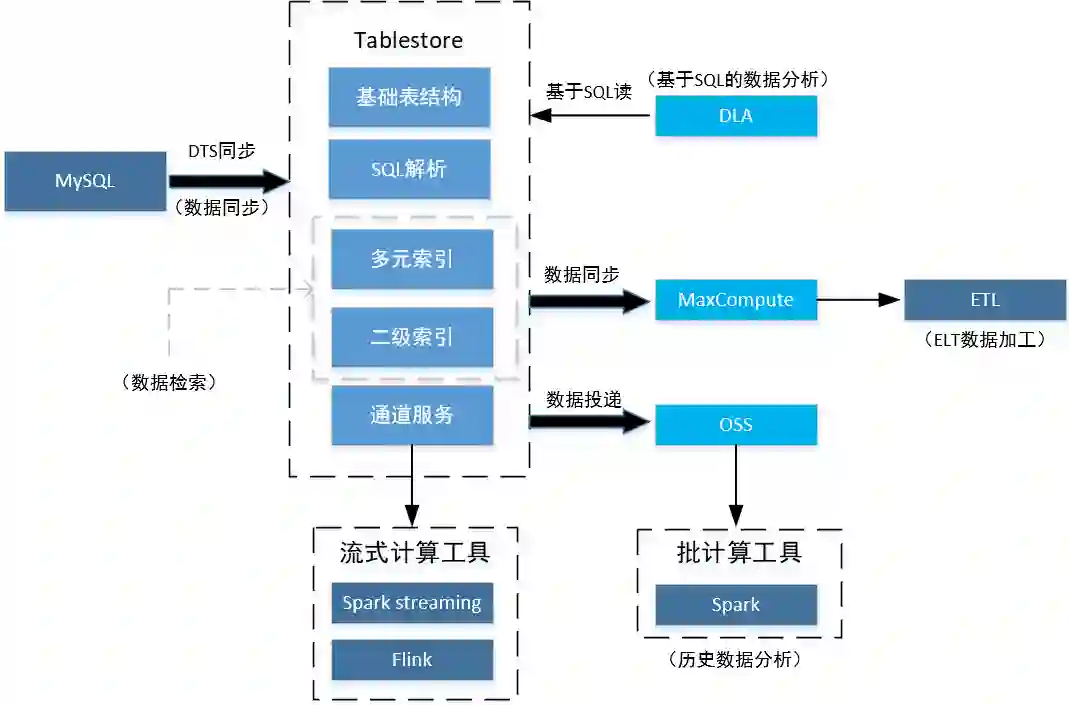
然后讲述 MySQL + Tablestore 架构,阐述这种架构是如何满足大规模订单系统的需求的。
二 需求场景
1 C 端需求
-
基于用户 id 查找用户近一月的订单。 -
基于订单号查询订单详情。 -
搜索用户购买过的包含某关键字的商品。
2 运营需求
-
统计在某旗舰店消费过的用户有哪些。
-
统计消费过某一件产品的客户有哪些并且他们还购买了什么产品,进而向客户推荐商品。
-
实时统计双十一开始后的实时成交额,用于宣传时的实时数据展示。
-
统计某店铺过去 10 年的成交额。
-
依赖订单数据对客户做实时更新的画像分析,以支持商品的推荐。
3 运维需求
-
系统高可用,并发能力强。
-
系统复杂度低,不需要维护多个集群,也不需要关注各集群间的数据同步过程,运维工作简单易上手。