
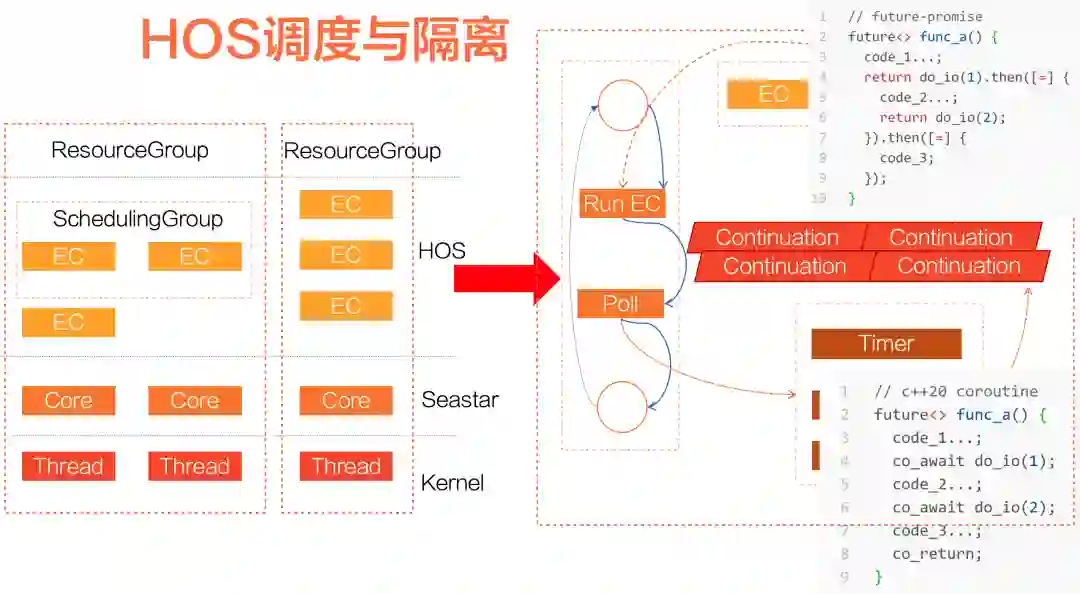
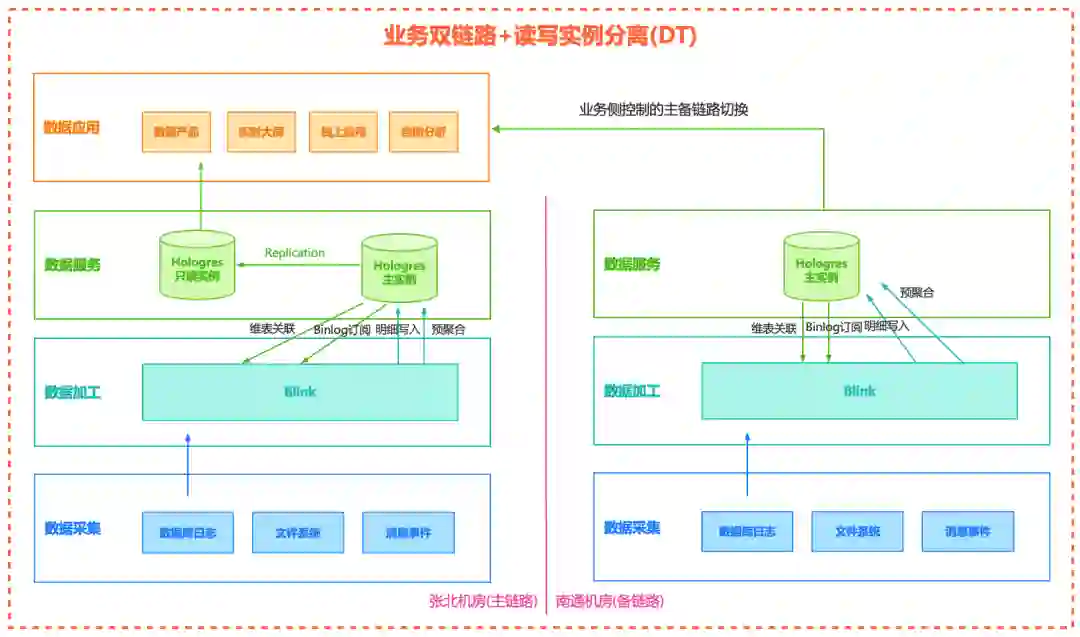
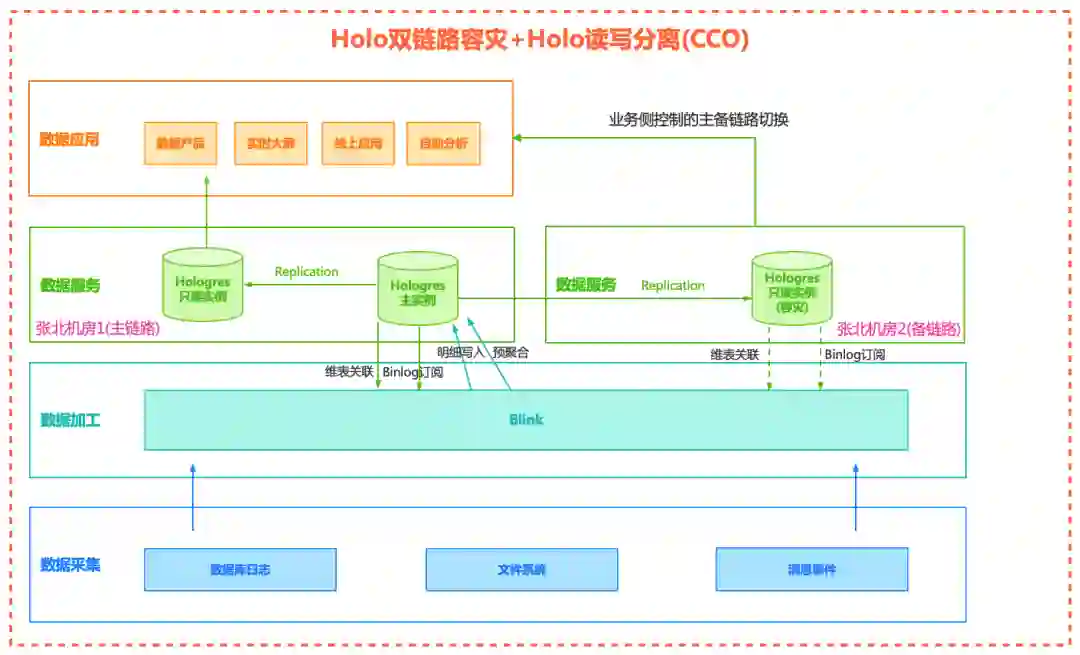
1、2020年VLDB的论文《Alibaba Hologres: A cloud-Native Service for Hybrid Serving/Analytical Processing》:http://www.vldb.org/pvldb/vol13/p3272-jiang.pdf
2、Hologres揭秘:首次公开!阿里巴巴云原生实时数仓核心技术揭秘:https://developer.aliyun.com/article/779118
3、Hologres揭秘:首次揭秘云原生Hologres存储引擎:https://developer.aliyun.com/article/779284?
4、Hologres揭秘:Hologres高效率分布式查询引擎:https://developer.aliyun.com/article/784506?
5、Hologres揭秘:高性能原生加速MaxCompute核心原理:https://developer.aliyun.com/article/784755?
6、Hologers揭秘:优化COPY,批量导入性能提升5倍+:
https://developer.aliyun.com/article/785001?
7、Hologres揭秘:如何支持超高QPS在线服务(点查)场景:https://developer.aliyun.com/article/785647?