迁移学习实战 | 快速训练残差网络 ResNet-101,完成图像分类与预测,精度高达 98%!


前言
笔者在实现ResNet的过程中,由于电脑性能原因,不得不选择层数较少的ResNet-18进行训练。但是很快发现,虽然只有18层,传统的训练方法仍然很耗时,甚至难以完成对101层的ResNet-101的训练。
出于这个原因,这一次,我将采用一种巧妙的方法——迁移学习来实现。即在预训练模型的基础上,采用101层的深度残差网络ResNet-101,对如下图所示的花数据集进行训练,快速实现了对原始图像的分类和预测,最终预测精确度达到了惊人的98%。


迁移学习
(1) 迁移学习简介
什么是迁移学习呢?百度词条给出了一个简明的定义:迁移学习是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。以我们的图像分类任务为例:
假如任务A的任务是猫狗分类,任务B是要对老虎、狮子进行分类。可以发现,任务 A 和任务 B 存在大量的共享知识,比如这些动物都可以从毛发,体型,形态等方面进行辨别。因此在已经存在一个针对任务A训练好的模型前提下,在训练任务B的模型时,我们可以不从零开始训练,而是基于在任务 A 上获得的知识再进行训练。在这里,针对A任务已经训练好的模型参数称之为:预训练模型。
这和“站在巨人的肩膀上”的思想非常类似。通过迁移任务 A 的知识,在任务 B 上训练分类器可以使用更少的样本,更少的训练代价来获得不错的泛化能力。
(2) 迁移学习原理
为了更清楚地解释迁移学习的原理,下面借一张有意思的图进行表达:
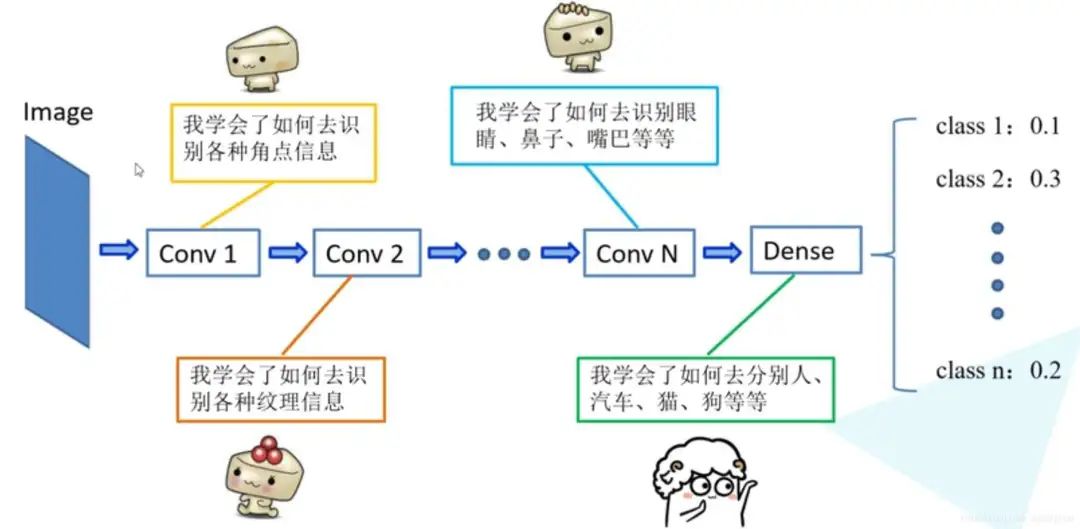
这是一个很常见的分类网络结构图,LeNet-5、AlexNet、VGG系列、GoogLeNet等都是基于这种多个卷积层+全连接层的结构来实现的。
图中,Conv1、Conv2…ConvN指的就是N个卷积层,用来提取图像不同层次的特征。其中,浅层的Conv1、Conv2等来提取图像的浅层特征,比如:角点、纹理、明亮等;深层的ConvN-1、ConvN等来提取的是图像更为抽象的特征,比如:眼睛、鼻子、嘴巴、肢体等。而Dense层指的是全连接层,用来对已学得的特征进行组合,从而学会了如何分辨人、汽车、猫、狗等。
对于这种经典的分类网络结构,有一个特点:浅层网络识别的特征具有通用性。正是得益于这种通用性,我们才不用再重新花费大量时间和资源去训练这些浅层特征,而是借助前人已经训练好的模型,在其基础上微调,来训练出应对特定任务的模型参数。这就是所谓“站在巨人肩膀上”的思想。
(3) 迁移学习的优势
迁移学习的优势也很明显,主要有以下两点:
由于是在预训练模型的基础上再进行训练,因此训练时间大大缩短,而且结果一般也比较理想。
当数据集较少时,也能训练出理想的效果。
(4) 常见的形式
常见的迁移学习方式有以下三种:
载入预训练模型后,训练所有的参数。
载入预训练模型后,只训练最后几个全连接层的参数。
载入预训练模型后,在原网络结构的基础之上再添加一层全连接层,仅训练最后一个全连接层。

预训练模型
在上文中,所说的针对任务A已经训练好的模型就是预训练模型。那么在此预训练模型的基础之上,就可以继续训练任务B的模型参数了。
(1) 预训练模型的获取
由于我们本次要对101层的ResNet-100进行训练,因此我们可以在ResNet-101的预训练模型的基础上,再来训练针对自己任务的模型参数。对于很多经典的深度神经网路,网上都会有很多官方的预训练模型。
比如,我们本次实战所要用的ResNe-101的预训练模型就可从github上的tensorflow官方开源项目上获取:https://github.com/tensorflow/models/tree/master/research/slim
下面绿色框代表的就是我们需要下载的版本:ResNet_v1_101
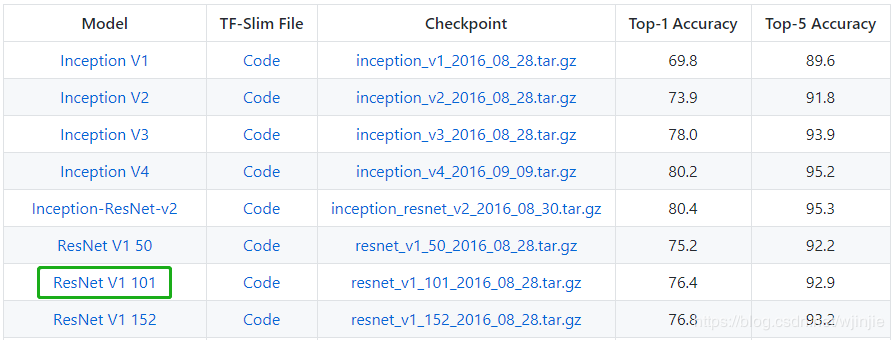
作为暖男的我,当然也考虑到有些同学可能出现github下载慢的问题,那么你可以选择从我的百度网盘下载:ResNet-101预训练模型,提取码:dg2m
(2) 预训练模型的微调
下载好预训练模型,解压后得到一个名为resnet_v1_101.ckpt的文件,放入如下图所示的工程文件目录下。
由于原模型是1000分类网络。而本次我们是要对花数据集进行五分类,所以我们需要对模型进行微调:去掉预训练模型的全连接层,改用节点数为5的全连接层,从而能对自定义数据集进行5分类。
实现上面这个过程,只需要先运行如下图所示的read_ckpt.py文件,就可将官网提供的预训练模型,转换为我们所需要的预训练模型。文件已上传到我的github:【AI 菌】的Github:https://github.com/Keyird/DeepLearning-TensorFlow2.0。
运行结束后,在原工程文件下,就会产生我们所需要的预训练权重文件,如下图红色框中所示:
3. 数据集介绍
这次我采用的是花分类数据集,该数据集一共有5个类别,分别是:daisy、dandelion、roses、sunflowers、tulips,一共有3670张图片。按9:1划分数据集,其中训练集train中有3306张、验证集val中有364张图片。
数据集下载地址:花分类数据集, 提取码:9ao5
大家下载完,将文件解压后直接放在工程根目录下,就像我这样:
预训练权重和数据集准备好了,我们就可以开始实战啦!

ResNet-101实战
温馨提示:完整工程代码已上传我的github地址:【AI 菌】的Github 。下面仅展示各个部分的核心代码,并做出必要的解释。
(1) 数据集准备
注意在数据集准备过程中,一定要对原图进行预处理。因为官方提供的预训练模型,在训练前也对数据集进行预处理了的,这里要采用对应的预处理方法,通过函数pre_function()来实现。
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # 获得根路径image_path = data_root + "/DeepLearning/ResNet-101/flower_data/" # 花数据集的路径train_dir = image_path + "train"validation_dir = image_path + "val"def pre_function(img): # 图像预处理img = img - [_R_MEAN, _G_MEAN, _B_MEAN]return img# 训练集准备:将图片载入、数据增强、预处理,然后转换成张量形式train_image_generator = ImageDataGenerator(horizontal_flip=True,preprocessing_function=pre_function)train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,batch_size=batch_size,shuffle=True,target_size=(im_height, im_width),class_mode='categorical')total_train = train_data_gen.n # 训练集样本总数
(2) 网络搭建
下面是ResNet整体网络结构的实现,对于ResNet的详细网络结构,我已经在TF2.0深度学习实战(七):手撕深度残差网络ResNet中详细讲到,这里不再赘述。
def _resnet(block, blocks_num, im_width=224, im_height=224, num_classes=1000, include_top=True):# 定义输入(batch, 224, 224, 3)input_image = layers.Input(shape=(im_height, im_width, 3), dtype="float32")# 第一层conv1x = layers.Conv2D(filters=64, kernel_size=7, strides=2,padding="SAME", use_bias=False, name="conv1")(input_image)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name="conv1/BatchNorm")(x)x = layers.ReLU()(x)x = layers.MaxPool2D(pool_size=3, strides=2, padding="SAME")(x)# conv2_xx = _make_layer(block, x.shape[-1], 64, blocks_num[0], name="block1")(x)# conv3_xx = _make_layer(block, x.shape[-1], 128, blocks_num[1], strides=2, name="block2")(x)# conv4_xx = _make_layer(block, x.shape[-1], 256, blocks_num[2], strides=2, name="block3")(x)# conv5_xx = _make_layer(block, x.shape[-1], 512, blocks_num[3], strides=2, name="block4")(x)if include_top:# 全局平均池化x = layers.GlobalAvgPool2D()(x)x = layers.Dense(num_classes, name="logits")(x)predict = layers.Softmax()(x)else:predict = xmodel = Model(inputs=input_image, outputs=predict)return modeldef resnet101(im_width=224, im_height=224, num_classes=1000, include_top=True):return _resnet(Bottleneck, [3, 4, 23, 3], im_width, im_height, num_classes, include_top)
(3) 网络微调
由于论文中ResNet-101是对ImageNet数据集进行1000分类,这里我们只对花数据集进行5分类。所以要对原网络进行微调:首先,去掉原ResNet101后面的全局平均池化和全连接层;然后,在模型后加入两个全连接层,节点数分别为1024和5,对自定义数据集进行5分类。
# 使用False,表示去掉原ResNet101后面的全局平均池化和全连接层feature = resnet101(num_classes=5, include_top=False)feature.load_weights('pretrain_weights.ckpt') # 加载预训练模型feature.trainable = False # 训练时冻结与训练模型参数feature.summary() # 打印预训练模型参数# 对网络微调:在模型后加入两个全连接层,进行自定义5分类model = tf.keras.Sequential([feature,tf.keras.layers.GlobalAvgPool2D(),tf.keras.layers.Dropout(rate=0.5),tf.keras.layers.Dense(1024),tf.keras.layers.Dropout(rate=0.5),tf.keras.layers.Dense(5),tf.keras.layers.Softmax()])model.summary() # 打印增加层的参数
(4) 模型装配与训练
在模型装配过程中,采用的是Adam优化器,CategoricalCrossentropy交叉熵损失函数,以及accuracy测试精确度。
# 模型装配# 1.目标损失函数:交叉熵loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False)# 2.优化器:Adamoptimizer = tf.keras.optimizers.Adam(learning_rate=0.0002)# 3.评价标准:loss和accuracytrain_loss = tf.keras.metrics.Mean(name='train_loss')train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')test_loss = tf.keras.metrics.Mean(name='test_loss')test_accuracy = tf.keras.metrics.CategoricalAccuracy(name='test_accuracy')
在模型训练过程中,我设置的batch_size = 16,epochs = 20。每训练完一个eopchs后,打印出平均分类精确度;并且利用当前epochs训练出的参数,对验证集进行测试,打印出当前epochs的验证机测试精确度。最后保存模型参数。
for epoch in range(1, epochs + 1):# 训练集训练过程for step in range(total_train // batch_size): # 一个epoch需要迭代的step数images, labels = next(train_data_gen) # 一次输入batch_size组数据train_step(images, labels) # 训练过程# 打印训练过程rate = (step + 1) / (total_train // batch_size) # 一个epoch中steps的训练完成度a = "*" * int(rate * 50) # 已完成进度条用*表示b = "." * int((1 - rate) * 50) # 未完成进度条用.表示acc = train_accuracy.result().numpy()print("\r[{}]train acc: {:^3.0f}%[{}->{}]{:.4f}".format(epoch, int(rate * 100), a, b, acc), end="")# 验证集测试过程for step in range(total_val // batch_size):test_images, test_labels = next(val_data_gen)test_step(test_images, test_labels) # 在验证集上测试,只进行前向计算# 每训练完一个epoch后,打印显示信息template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'print(template.format(epoch,train_loss.result(),train_accuracy.result() * 100,test_loss.result(),test_accuracy.result() * 100))# 保存模型参数model.save_weights("./save_weights/resNet_101.ckpt", save_format="tf")

测试结果
(1) 图像分类结果
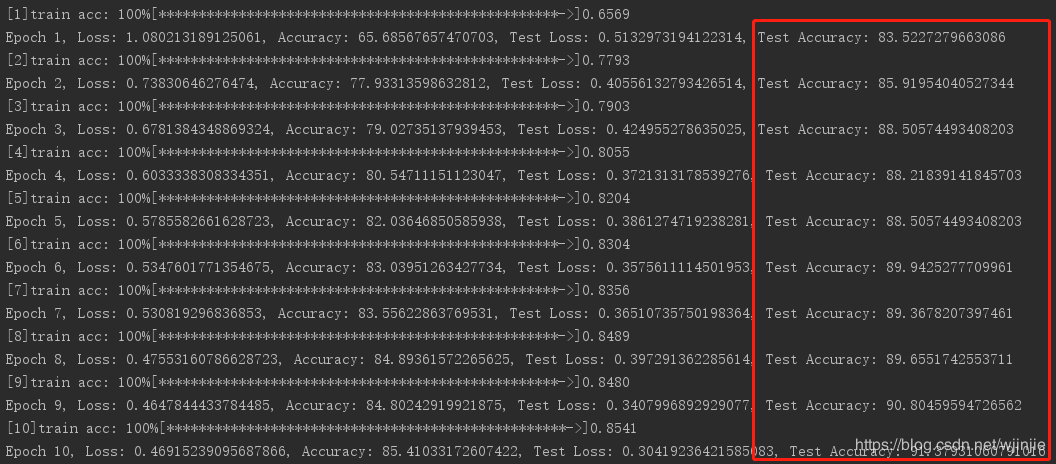
下面就是在训练过程中,打印出来的分类精确度信息。图中红色框显示的就是测试精确度。可以看到随着训练的进行,精确度在不断地升高,最终达到91.3%。由于时间关系,这里我只训练了10个epochs,如果继续训练下去,应该可以得到更好的模型。
(2) 对单张图像的预测结果
在工程根目录下,放入一张类别为roses的图片,将其命名为rose_test.jpg。我们读入这张图片,加载刚才已经训练好的模型,对图片进行预测。
在预测过程中,需要注意的是:
需要对输入的图片进行预处理,预处理方式和之前保持一致。
同样要对原网络模型进行微调,微调的方法和上述网络微调的方法一致。
预测代码在工程文件下的predict.py里,执行它即可得到预测结果。预测代码如下:
# 加载要进行预测的图片img = Image.open("E:/DeepLearning/ResNet-101/rose_test.jpg")# resize成224x224img = img.resize((im_width, im_height))plt.imshow(img)# 将图片做预处理_R_MEAN = 123.68_G_MEAN = 116.78_B_MEAN = 103.94img = np.array(img).astype(np.float32)img = img - [_R_MEAN, _G_MEAN, _B_MEAN]img = (np.expand_dims(img, 0))# class_indices.json中存放的是标签字典try:json_file = open('./class_indices.json', 'r')class_indict = json.load(json_file)except Exception as e:print(e)exit(-1)# 网络模型的微调feature = resnet50(num_classes=5, include_top=False)feature.trainable = Falsemodel = tf.keras.Sequential([feature,tf.keras.layers.GlobalAvgPool2D(),tf.keras.layers.Dropout(rate=0.5),tf.keras.layers.Dense(1024),tf.keras.layers.Dropout(rate=0.5),tf.keras.layers.Dense(5),tf.keras.layers.Softmax()])# 加载训练好的模型参数model.load_weights('./save_weights/resNet_101.ckpt')result = model.predict(img)prediction = np.squeeze(result)predict_class = np.argmax(result)print('预测该图片类别是:', class_indict[str(predict_class)], ' 预测概率是:', prediction[predict_class])plt.show()
输入的图片rose_test.jpg属于rose类,图片如下:

预测结果如下:

可见,预测结果与原图rose_test.jpg的标签一致,预测成功!且预测的概率高达98%,预测效果比较好!
(3) 实际训练参数量的对比
采用了迁移学习的方法训练ResNet-101后,我们在训练速度上得到很大的提升。而且得到的测试精度很高。那么下面,我们从定量的角度来分析,训练速度大大提升的原因。
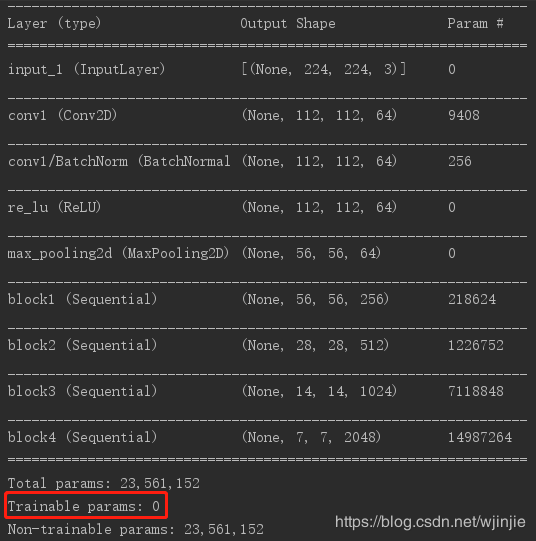
下图是ResNet-101所有的卷积层参数列表,也是我们所用的预训练模型的部分,其参数量有2300万多。这部分参数是预训练模型提供的,不用训练。因此,下图红色框表示卷积层需要训练的参数量为0。
下图是网络微调后的网络每层参数列表。其中,绿色框表示的是卷积层的总参数量,参数量是2300万多。实际训练的是全连接层中参数,如下图红色框所示,一共是200万多个参数。
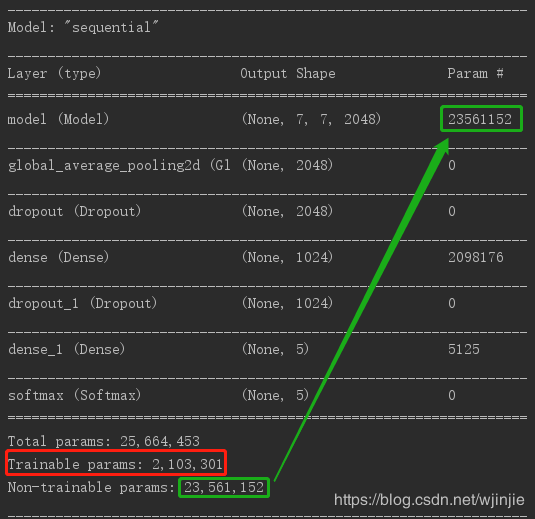
由此可知,使用了迁移学习的方法后,卷积层2300万多个参数可由预训练模型提供,不需要再进行训;只需要对全连接层200万多个参数进行训练。因此,训练的速度大大提升!

总结
采用迁移学习的方法,我们就可以在预训练模型的基础上,再进行训练。这种思想,就如同“站在巨人的肩膀上”,不仅能减少时间和资源的开销,还能提供一个本来就不错的精确度。而我们只需要在原网络模型基础上进行微调,训练出满足自己任务的网络模型参数。
版权声明:本文为CSDN博主「AI 菌」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wjinjie/article/details/105665214


更多精彩推荐
☞一秒带你穿越!AI 修复百年前北京影像,路边摊、剃头匠太真实了
![]()
你点的每个“在看”,我都认真当成了喜欢





