正则化到底是怎么消除过拟合的?这次终于有人讲明白了!
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
“
1 过拟合怎么产生的?
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
1 过拟合怎么产生的?
“
2 消除过拟合的通俗理解
2 消除过拟合的通俗理解
“
3 相比L2,L1正则更可能使模型变稀疏?
3 相比L2,L1正则更可能使模型变稀疏?
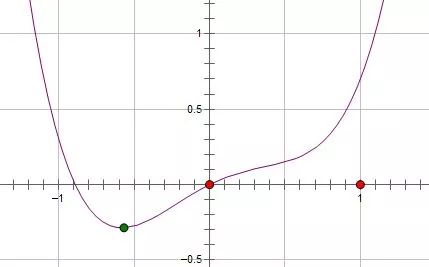
图片来源于网络
如果施加 L1,则新的函数为:Loss()+C|w|,要想消除这个特征的作用,只需要令 w = 0,使它取得极小值即可。
且可以证明:添加L1正则后 ,只要满足:
系数 C 大于原函数在 0 点处的导数的绝对值,
w = 0 就会变成一个极小值点。
证明过程如下,如上图所示,要想在0点处取得极小值,根据高数基本知识:
1) w小于0时,d(Loss)/d(w) - C 小于0
2) 且,w大于0时,d(Loss)/d(w) + C 大于0
上面两个式子同时满足,可以简写为:| d(Loss)/d(w) | < C, 得证。
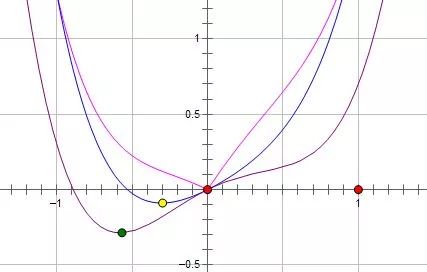
如果施加 L2, 则新的函数为:Loss()+Cw^2 ,求导可得:d(Loss)/d(w) + 2Cw,要想在w = 0点处取得极小值,必须得满足:
d(Loss)/d(w) = 0
言外之意,如果原函数在0点处的导数不为 0,那么施加 L2 正则后导数依然不为 0,也就不会在0点处取得极小值。
这种概率很明显小于L1正则在0点处取得极小值的概率值,由此可得,L1更容易使得原来的特征变弱或消除,换句话说就是更容易变稀疏。
讲完了,读者朋友们,你们看明白了吗?
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿也欢迎联系:simiter@126.com

长按关注计算机视觉life
推荐阅读
盘点卷积神经网络中十大变革操作:变形卷积核、可分离卷积。。。
Android手机移植TensorFlow,实现物体识别、行人检测、图像风格迁移
最新AI干货,我在看





