ConvNeXt:手把手教你改模型

极市导读
本文目的是结合代码对该工作中的trick进行梳理,帮助广大工程师童鞋抄作业,整合到自己的项目中。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
A ConvNet for the 2020s
我愿称之为2022年cv算法工程师抄作业必备手册,手把手教你改模型,把ResNet50从76.1一步步干到82.0。或许对于广大researcher而言这只是一个堆trick的工作,但对于工程师来说,光是验证哪些trick能work,哪些trick堆叠在一起能都产生收益,这件事本身就已经散发着money的味道了。现在大佬们烧了这么多电费把结果摆到大家面前,还要什么自行车。
本文的目的是结合代码对该工作中的trick进行梳理,帮助广大工程师童鞋抄作业,整合到自己的项目中。
Roadmap
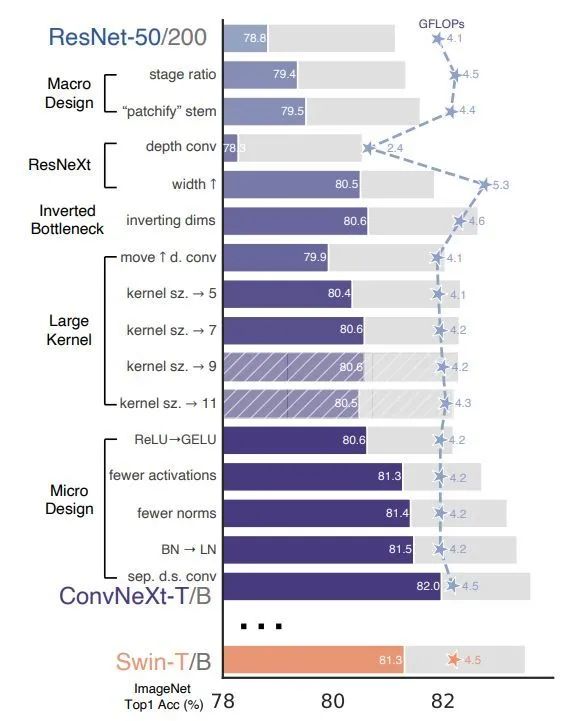
这张图可以说是整篇论文的精华,有经验的童鞋光是看这张图就知道该做什么了。
0. 训练策略优化(76.1-78.8)
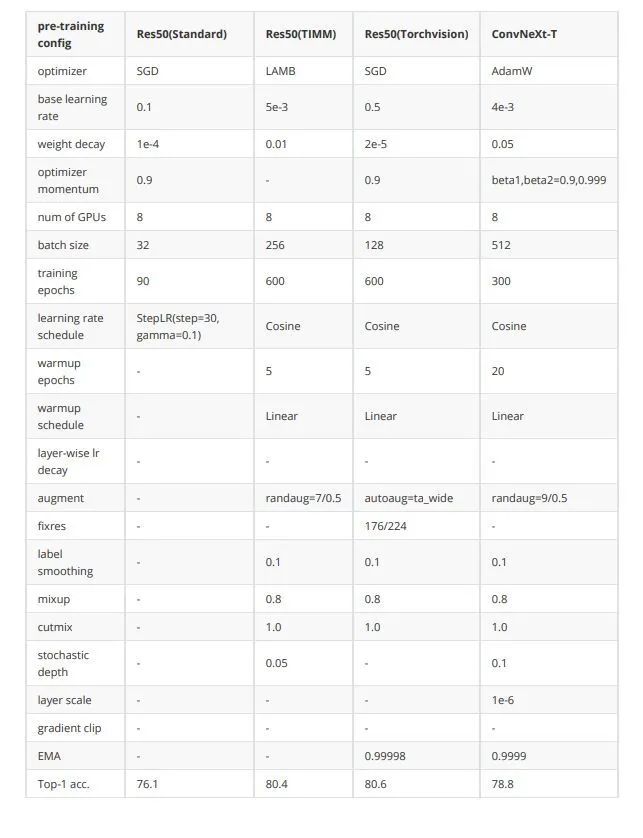
深度学习发展了这么久,除了结构上的创新,各种训练策略也在升级。2021年timm和torchvision团队均有工作讲述如何通过优化训练策略来使resnet50性能提升到80以上。
考虑到跟Swin Transformer的公平对比,本文的训练策略没有完全follow前面的工作,但仍然可以将ResNet50从76.1提升到78.8。
这里我汇总了一下训练策略横向对比,方便大家查表:
1. 宏观设计
1.1 改变stage compute ratio(78.8-79.4)
改变layer0到layer3的block数量比例,由标准的(3,4,6,3)改为Swin-T使用的(3,3,9,3),即1:1:3:1。对于更大的模型,也跟进了Swin所使用的1:1:9:1。
1.2 使用Patchify的stem(79.4-79.5)
从ViT开始,为了将图片转化为token,图片都会先被分割成一个一个的patch,而在传统ResNet中stem层是使用一个stride=2的7x7卷积加最大池化层。
本文仿照Swin-T的做法,用stride=4的4x4卷积来进行stem,使得滑动窗口不再相交,每次只处理一个patch的信息。
# 标准ResNet
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=7, stride=2),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# ConvNeXt
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
通过代码我们可以注意到,在stem中还加入了一个LN。
2. ResNeXt化(79.5-80.5)
由于ResNeXt在FLOPs/accuracy的trade-off比ResNet更优秀,于是进行了一些借鉴,主要是使用了分组卷积。
ResNeXt的指导准则是“分更多的组,拓宽width”,因此本文直接使用了depthwise conv,即分组数等于输入通道数。这个技术在之前主要是应用在MobileNet这种轻量级网络中,用于降低计算量。但在这里,作者发现dw conv由于每个卷积核单独处理一个通道,这种形式跟self-attention机制很相似,都是在单个通道内做空间信息的混合加权。
将bottleneck中的3x3卷积替换成dw conv,再把网络宽度从64提升到96。
3. 反瓶颈结构(80.5-80.6)
在标准ResNet中使用的bottleneck是(大维度-小维度-大维度)的形式来减小计算量。后来在MobileNetV2中提出了inverted bottleneck结构,采用(小维度-大维度-小维度)形式,认为这样能让信息在不同维度特征空间之间转换时避免压缩维度带来的信息损失,后来在Transformer的MLP中也使用了类似的结构,中间层全连接层维度数是两端的4倍。
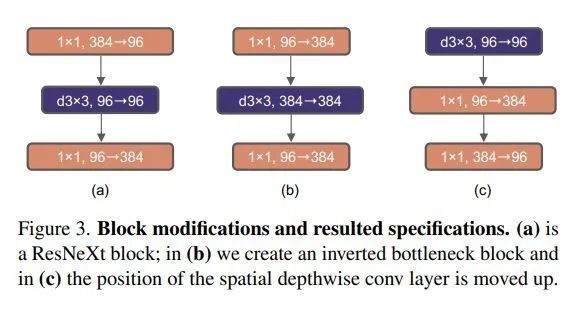
4. 大卷积核(80.6-80.6)
由于Swin-T中使用了7x7卷积核,这一步主要是为了对齐比较。又因为inverted bottleneck放大了中间卷积层的缘故,直接替换会导致参数量增大,因而作者把dw conv的位置进行了调整,放到了反瓶颈的开头。最终结果相近,说明在7x7在相同参数量下效果是一致的。
5. 微观设计
5.1 用GELU替换ReLU(80.6-80.6)
主要是为了对齐比较,并没有带来提升。
5.2 减少激活层数量(80.6-81.3)
由于Transformer中只使用了一个激活层,因此在设计上进行了效仿,结果发现只在block中的两个1x1卷积之间使用一层激活层,其他地方不适用,反而带来了0.7个点的提升。这说明太频繁地做非线性投影对于网络特征的信息传递实际上是有害的。
5.3 减少归一化层数量(81.3-81.4)
基于跟减少激活层相同的逻辑,由于Transformer中BN层很少,本文也只保留了1x1卷积之前的一层BN,而两个1x1卷积层之间甚至没有使用归一化层,只做了非线性投影。
5.4 用LN替换BN(81.4-81.5)
由于Transformer中使用了LN,且一些研究发现BN会对网络性能带来一些负面影响,本文将所有的BN替换为LN。
5.5 单独的下采样层(81.5-82.0)
标准ResNet的下采样层通常是stride=2的3x3卷积,对于有残差结构的block则在短路连接中使用stride=2的1x1卷积,这使得CNN的下采样层基本与其他层保持了相似的计算策略。而Swin-T中的下采样层是单独的,因此本文用stride=2的2x2卷积进行模拟。又因为这样会使训练不稳定,因此每个下采样层后面增加了LN来稳定训练。
self.downsample_layers = nn.ModuleList()
# stem也可以看成下采样层,一起存到downsample_layers中,推理时通过index进行访问
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
# 由于网络结构是downsample-stage-downsample-stage的形式,所以stem和后面的下采样层中的LN是不会连在一起的
对以上内容进行整合,最终得到了单个block的设计及代码:
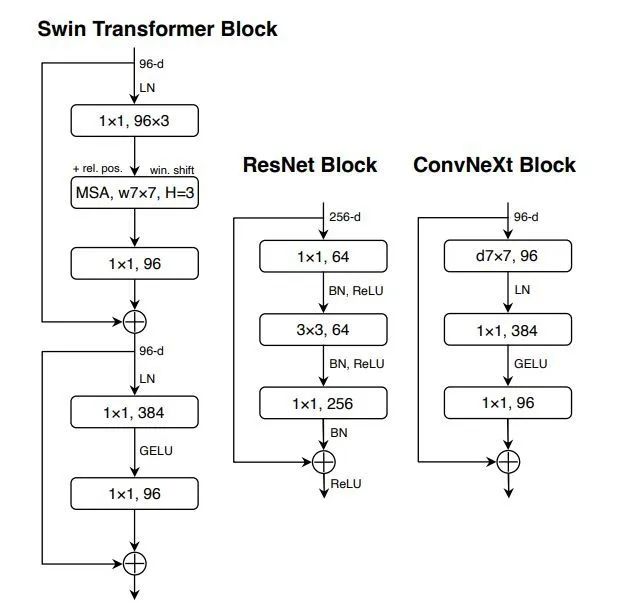
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
# 分组卷积+大卷积核
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim)
# 在1x1之前使用唯一一次LN做归一化
self.norm = LayerNorm(dim, eps=1e-6)
# 全连接层跟1x1conv等价,但pytorch计算上fc略快
self.pwconv1 = nn.Linear(dim, 4 * dim)
# 整个block只使用唯一一次激活层
self.act = nn.GELU()
# 反瓶颈结构,中间层升维了4倍
self.pwconv2 = nn.Linear(4 * dim, dim)
# gamma的作用是用于做layer scale训练策略
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
# drop_path是用于stoch. depth训练策略
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
# 由于用FC来做1x1conv,所以需要调换通道顺序
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
通过代码可以注意到,以上Block中两层1x1卷积是用全连接层来实现的,按照作者的说法,这样会比使用卷积层略快。
但作者是在GPU上进行的实验,考虑到CPU上很多情况会不同,因此我缩减得到了一个轻量的ConvNeXt-ExTiny模型,并转换成MNN模型,测试了两种实现方案的速度,发现在CPU上还是使用1x1卷积层的速度更快。
实现如下:
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.act = nn.GELU()
self.norm = LayerNorm(dim, eps=1e-6, data_format="channels_first")
self.pwconv1 = nn.Conv2d(dim, dim*4, kernel_size=1, stride=1)
self.pwconv2 = nn.Conv2d(dim*4, dim, kernel_size=1, stride=1)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,1,1)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = input + self.drop_path(x)
return x
MNN下CPU推理速度对比:
fc版:
mnn_inference: 16.39620065689087
mnn_inference: 17.782490253448486
mnn_inference: 17.42337703704834
mnn_inference: 16.68517827987671
mnn_inference: 15.608322620391846
1x1 conv版本:
mnn_inference: 14.232232570648193
mnn_inference: 14.07259225845337
mnn_inference: 13.94277572631836
mnn_inference: 14.112122058868408
mnn_inference: 13.633315563201904
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


