CVPR 2020 | 眼见为虚:利用对抗文本图像攻击场景文本识别模型
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

论文已上传,文末附下载方式
本文转载自:CSIG文档图像分析与识别专委会

本文简要介绍CVPR2020录用论文“What Machines See Is Not What They Get: Fooling Scene Text Recognition Models with Adversarial Text Images”的主要工作。该论文针对目前主流的场景文字识别(STR)模型,提出了一种高效的基于优化的对抗攻击方法。这是对抗攻击在场景文本识别模型中的首次尝试和研究。实验证明,该方法在7个真实数据和2个生成数据上大大降低了STR模型的识别性能,并成功攻击了百度OCR的识别引擎。
http://openaccess.thecvf.com/content_CVPR_2020/html/Xu_What_Machines_See_Is_Not_What_They_Get_Fooling_Scene_CVPR_2020_paper.html
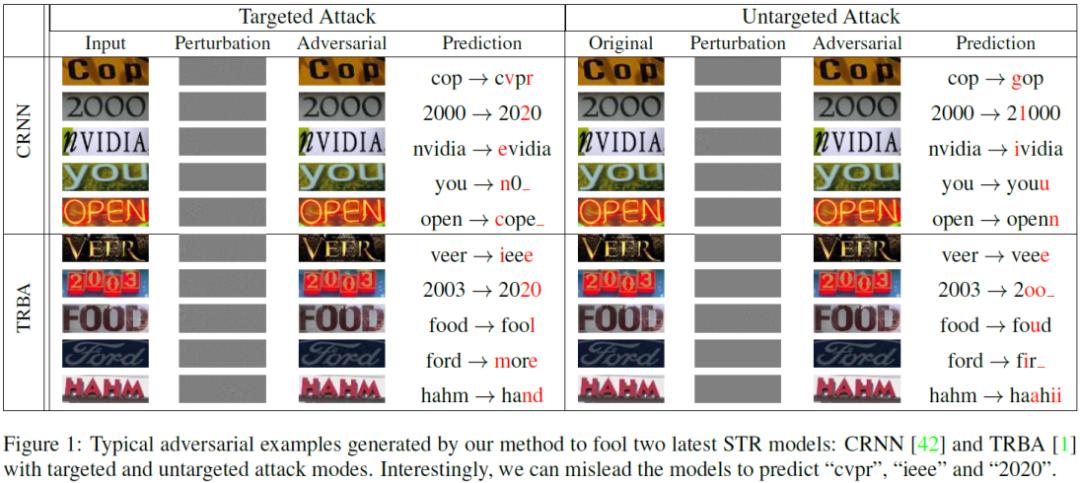
STR模型的对抗攻击目标可以定义为找到一个与普通样本非常相似(人眼几乎不能发现差异)但识别结果却差异很大的样本。因此该文章假定输入的场景文本图片为x,相应的Ground-truth为l={l0, l1,…, lT},T为序列的长度。目标是找到对抗样本x’=x+δ(δ为对抗扰动)来欺骗STR模型,使得其预测出错误的序列l’。其对应的优化问题可以被描述为:
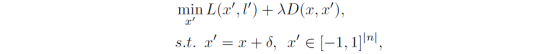
根据解码器(CTC-based解码器和Attention-based解码器)以及攻击方式(有目标攻击和非目标攻击)的组合,该方法有四种不同的形式。
训练CTC-based识别模型 [4-6] 需要考虑所有有效对齐路径(π∈S(l))到ground-truth(l)的概率,对应的损失函数为:
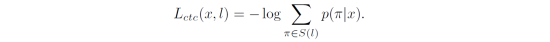
a) 有目标攻击
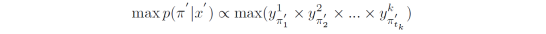
所以,最终的目标函数为:
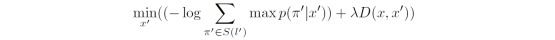
b) 非目标攻击
非目标攻击只要求模型预测出不为l的序列,因此只要使有效路径到l概率最小即可:
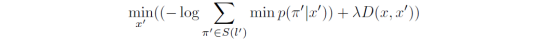
2) 攻击Attention-based STR模型
Attention-based STR模型 [7, 8] 会根据t时刻之前(1, 2,…,t-1)的输出,预测出t时刻的输出,对应的损失函数为:
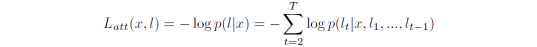
a) 有目标攻击
首先,假设只改变目标序列中的一个字符(lt’),对应的损失函数为
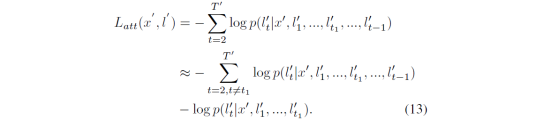
将这个应用到一般情况,改变目标序列中k个字符,则l’可以分为k+1个部分,即1个没有改变的字符组和k个改变的字符。因为上列公式中第一项是常数项,所以损失函数可以改写为:
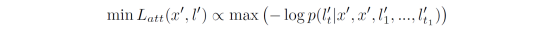
攻击方法的最终目标函数为:
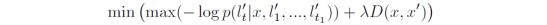
当l中任意位置上的预测字符获得比较低的概率时,该字符就会受到攻击,模型会输出和l不同的序列l’:
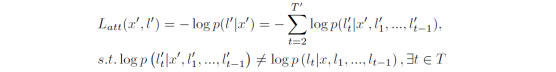
所以,最终的目标函数为:
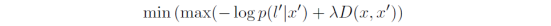
通过求解上述四个目标函数,可以得到相应的攻击样本,具体的流程如下图所示:

作者对五个STR模型进行了有目标攻击和非目标攻击,并在7个真实数据集和2个生成数据集上做了测试,结果如下:
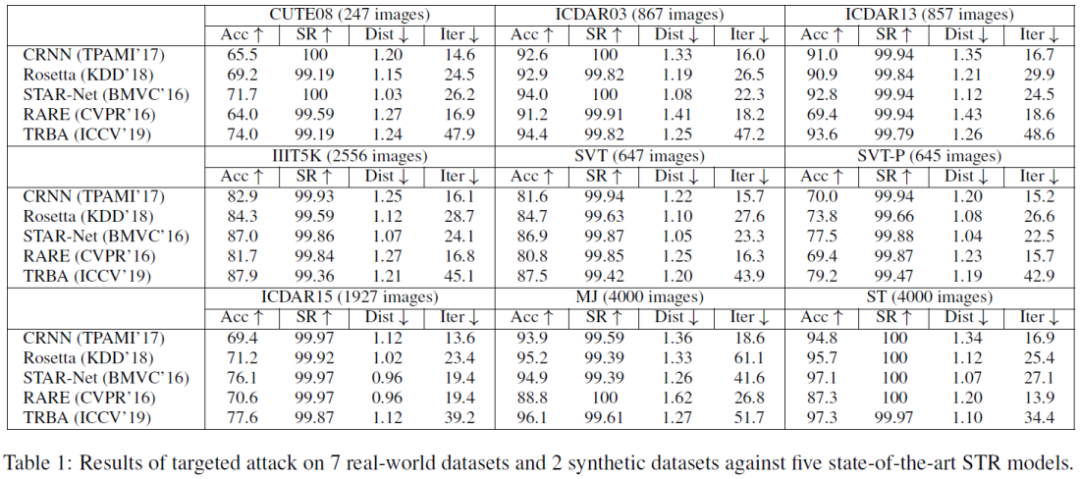
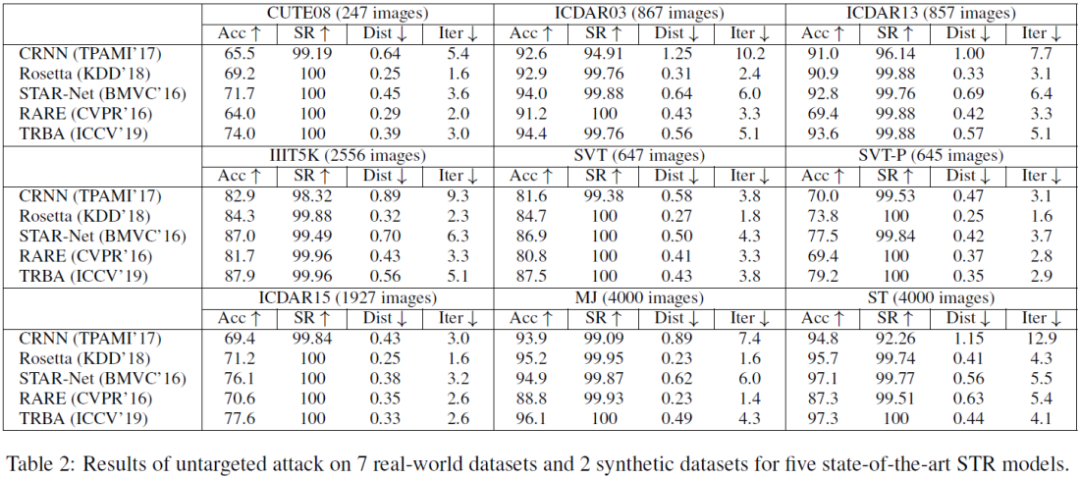
从表格中可以得出,目前主流的几个STR模型是非常脆弱的,几乎无法正确识别对抗样本,该攻击方法的成功率(SR)接近100%。除此之外,该方法还在真实系统百度OCR上进行了评估。在真实数据上选取800张图片,并用CRNN [4] 和TRBA [8] 的模型产生对抗样本,然后让百度OCR进行识别。识别结果如下:
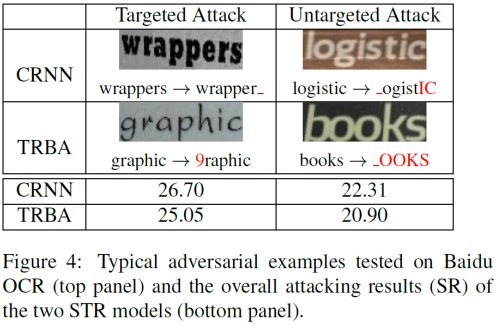
不管是有目标攻击还是非目标攻击,成功率都在20%以上,由此证明了该攻击方法对百度OCR模型的有效性。
本文首次提出了一种通用有效的STR攻击方法,并在目前主流的CTC-based和Attention-based STR模型中得到了验证。作者在7个真实数据、2个生成数据和真实STR系统上对该方法进行测试。结果显示,该攻击方法几乎完全欺骗了5个SOTA的STR模型,同时在商业STR系统上也显示出较高的攻击性能。
[1] Chaowei Xiao, Dawei Yang, Bo Li, Jia Deng, and Mingyan Liu. Meshadv: Adversarial meshes for visual recognition. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, pages 6898–6907, 2019.
[2] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Yuyin Zhou, Lingxi Xie, and Alan L. Yuille. Adversarial examples for semantic segmentation and object detection. In IEEE International Conference on Computer Vision, ICCV, pages 1378–1387, 2017.
[3] Xiaoyong Yuan, Pan He, and Xiaolin Andy Li. Adaptive adversarial attack on scene text recognition. CoRR, abs/1807.03326, 2018.
[4] Baoguang Shi, Xiang Bai, and Cong Yao. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell., 39(11):2298–2304, 2017.
[5] Fedor Borisyuk, Albert Gordo, and Viswanath Sivakumar. Rosetta: Large scale system for text detection and recognition in images. In ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD, pages 71–79, 2018.
[6] Wei Liu, Chaofeng Chen, Kwan-Yee K.Wong, Zhizhong Su, and Junyu Han. Star-net: A spatial attention residue network for scene text recognition. In British Machine Vision Conference, BMVC, 2016.
[7] Baoguang Shi, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. Robust scene text recognition with automatic rectification. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR, pages 4168–4176, 2016.
[8] Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, and Hwalsuk Lee. What is wrong with scene text recognition model comparisons? dataset and model analysis. In IEEE International Conference on Computer Vision, pages 652–661, 2019.
审校:殷 飞 | 发布:金连文
论文下载
在CVer公众号后台回复:0625,即可下载本论文
重磅!CVer-OCR交流群成立
扫码添加CVer助手,可申请加入CVer-OCR 微信交流群,目前已满400+人,旨在交流OCR、场景文本检测、场景文本识别等。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如OCR+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer一个在看!

