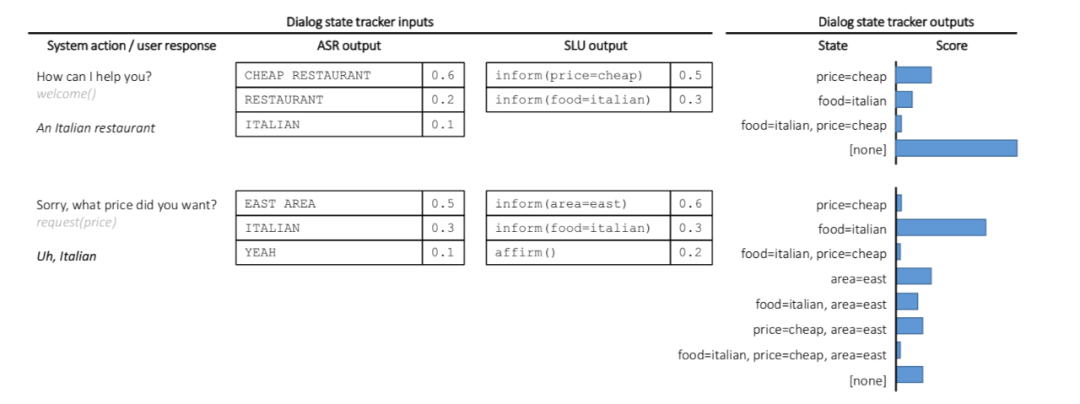
【DST系列】DST方法分类

上一篇文章我们介绍了什么是DST、状态的表示、以及DST的难点,这一篇我们主要介绍DST方法分类。
DST的常用方法主要有三种:基于规则的方法、生成式方法、判别式方法,目前来看判别式方法的表现最好,也是当前研究最多的方向。
1.基于规则的方法
早期的对话系统一般是基于规则进行对话状态追踪。在最早的形式中,这些方法通常仅考虑单个NLU结果,并追踪对话状态的单个假设。该设计将对话状态追踪问题简化为更新规则 , 是已有的状态, 是1-best NLU的识别结果,相当于选择NLU识别的概率值最大的状态和历史状态合并,而且输出的状态也是确定型。更新规则可以是直接覆盖或者按照阈值选择等。
基于规则的方法都有自身的局限性,需要大量的人工和专家知识,因此在较复杂的场景适用性不强。也没有办法同时追踪多种状态。一般使用的规则都很简单,没有办法定制复杂状态的更新机制,缺乏灵活性。基于规则的好处是不依赖于数据,而且很容易将领域的先验知识编码到规则中,这对于冷启动或者无法获取到高质量的对话数据的场景是有好处的。规则还为开发人员提供了一种合并领域知识的便捷方法。除了使用当前的NLU的结果,也可以基于规则设计的公式在整个ASR / NLU置信度得分和 的先前估计的情况下计算对话状态的后 ,从而可以克服一些NLU错误。
状态分布示意图
使用规则设计的公式来计算 有一个关键的局限性:公式参数不是直接从真实的对话数据中得出的,因此需要仔细调整,并且不能从对话数据中受益或学习。这种局限性促使人们使用数据驱动技术,该技术可以自动设置参数以使准确性最大化。数据驱动技术中最主要的是生成式方法和判别式方法,如下所述。
2.生成式方法
生成式方法主要是对数据集中存在的模式进行挖掘,学习出对话状态的条件概率分布。生成式方法假定对话可以建模为贝叶斯网络,该网络将对话状态 与系统动作 ,观察到或未观察到的用户动作 (指用户的输入query)以及ASR或NLU结果 相联系。当观察到系统动作和ASR / NLU结果时,可以通过应用贝叶斯推断来计算可能的对话状态分布。通过构建对话状态之间的转义关系图,建模各变量之间的依赖关系和概率分布计算公式。生成式方法主要是利用贝叶斯网络推断来学得整个状态的概率分布,其通用表达式如下:
是历史的对话状态分布, 是更新后的对话状态, 是ASR/NLU是通过识别用户的话得出的状态, 是在给定的对话状态 和系统动作 下的采取的动作, 是在给定状态 和系统动作 下状态转变成 的概率, 是一个归一化的常量。这个公式定义了状态 是转移到 的概率。其中真实对话状态 和真实用户动作 被视为未观察到的随机变量,等式第一个求和项叫作观测模型,第二个求和项叫作转移模型。
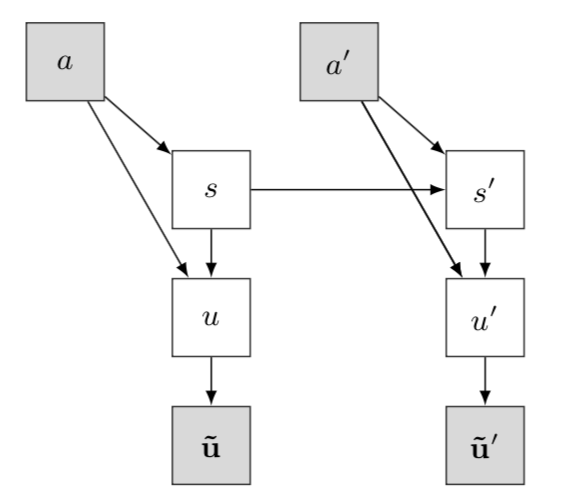
可以看出上面的公式还是比较复杂的,因此实现起来也比较复杂,传统的生成式方法还要列出所有可能的状态,以及状态概率转移矩阵等。
生成式方法比基于规则的方法具有更好的性能。但是,生成方法也不能轻易地合并来自ASR,NLU,对话历史记录和其他地方的大量潜在特征:必须明确地建模功能之间的所有依赖关系,这需要不切实际的数据量。因此,仍然无法完全利用所有有用的信息。为了易于处理,生成方法通常会做出无效的独立性假设,或者必须忽略对话历史的重要特征,从而违反了马尔可夫假设。最终结果是 的估算很差。这些问题共同激发了对判别式方法的研究,这些方法将在下面介绍。
3.判别式方法
与生成式方法相反,判别式方法根据模型直接计算对话状态的概率,其形式为 ,其中 是从ASR/NLU和对话历史记录抽取的特征。判别式方法的主要优点是它们可以合并大量特征,并且可以直接优化预测的准确率。模型直接从大量数据中学习用户行为,因此可以引入一些先验知识改善状态追踪效果,比如对一些置信度高的NLU结果设计一些特定规则以表示状态的转换等。
判别式方法的主要环节就是特征提取+模型,常见的方法有两大类:
-
一种是将特征用于训练分类器,预测状态的概率; -
另外一种是将特征用于序列建模。
主要使用SVM、最大熵模型、CRF等来建模。随着深度学习的发展,DNN,RNN等模型也越来越多的占领了这个领域。
4.总结
本篇没有过多的讲解具体的模型,主要是介绍了分类体系。规则的和生成式的都是比较旧的方法,当前主要研究也不在这些方法上。就目前来讲,判别式方法效果更好,也是目前研究最为广泛的,因为它通过特征提取的方法对对话状态进行精准建模,而且可以方便的结合深度学习等方法进行自动提取特征。因此下一篇主要介绍判别式模型,及如何解决第一篇提到的DST难点。
作者介绍
王文彬,2018年毕业于中国科学院大学。毕业后加入贝壳找房语言智能部,主要从事NLP、强化学习和搜索推荐相关工作。
戳下面👇
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



