FastText词嵌入的可视化指南

作者:Amit Chaudhary
编译:ronghuaiyang
非常清楚的解释了FastText的来龙去脉。
单词嵌入是自然语言处理领域中最有趣的方面之一。当我第一次接触到它们时,对一堆文本进行无监督训练的简单方法产生了显示出语法和语义理解迹象的表示,这很有趣。
在这篇文章中,我们将探索由Bojanowski等人介绍的名为“FastText”的单词嵌入算法,并了解它是如何对2013年的Word2Vec算法进行增强的。
词表示的直觉
假设我们有下面的单词,我们想把它们表示成向量,这样它们就可以用于机器学习模型。
Ronaldo, Messi, Dicaprio
一个简单的想法是对单词进行独热编码,其中每个单词都有一个唯一的位置。
| isRonaldo | isMessi | isDicaprio | |
|---|---|---|---|
| Ronaldo | 1 | 0 | 0 |
| Messi | 0 | 1 | 0 |
| Dicaprio | 0 | 0 | 1 |
我们可以看到,这种稀疏表示没有捕捉到单词之间的任何关系,而且每个单词都是相互独立的。
也许我们可以做得更好。我们知道Ronaldo和Messi是足球运动员,而Dicaprio是演员。让我们使用我们的世界知识并创建手动特征来更好地表示这些单词。
| isFootballer | isActor | |
|---|---|---|
| Ronaldo | 1 | 0 |
| Messi | 1 | 0 |
| Dicaprio | 0 | 1 |
这比之前的独热编码更好,因为相关的项在空间上更接近。

我们可以继续添加更多的方面作为维度来获得更细微的表示。
| isFootballer | isActor | Popularity | Gender | Height | Weight | … | |
|---|---|---|---|---|---|---|---|
| Ronaldo | 1 | 0 | … | … | … | … | … |
| Messi | 1 | 0 | … | … | … | … | … |
| Dicaprio | 0 | 1 | … | … | … | … | … |
但是为每个可能的单词手动这样做是不可扩展的。如果我们根据我们对单词之间关系的认知来设计特征,我们能在神经网络中复制同样的特征吗?
我们能让神经网络在大量的文本语料库中进行梳理并自动生成单词表示吗?
这就是研究词嵌入算法的目的。
Word2Vec回顾
2013年,Mikolov等提出了一种从大量非结构化文本数据中学习单词向量表示的有效方法。这篇论文从语义分布的角度实现了这个想法。
你可以通过这个单词和哪些单词在一起出现来了解这个单词 — J.R. Firth 1957
由于相似的单词出现在相似的上下文中,Mikolov等人利用这一观点制定了表征学习的两个任务。
第一种方法叫做“连续词包(Continuous Bag of Words)”,它预测相邻词的中心词。
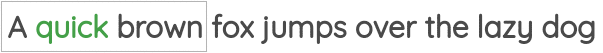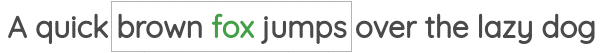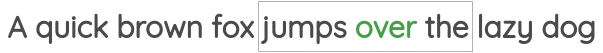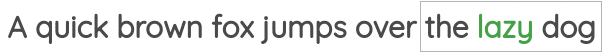
第二项任务叫做“Skip-gram”,在这个任务中,我们给定中心词,预测上下文词。
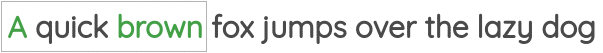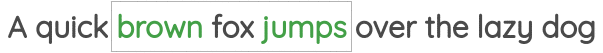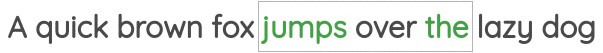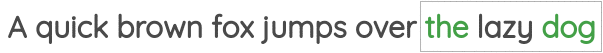
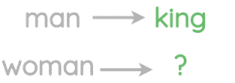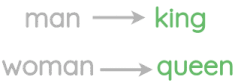
学习到的表征具有有趣的特征,比如这个流行的例子,在这个例子中,对单词向量的算术运算似乎保留了意义。

Word2Vec的局限性
虽然Word2Vec改变了NLP的游戏规则,我们将看到如何仍有一些改进的空间:
-
Out of Vocabulary(OOV)单词:
在Word2Vec中,需要为每个单词创建嵌入。因此,它不能处理任何在训练中没有遇到过的单词。例如,单词“tensor”和“flow”出现在Word2Vec的词汇表中。但是如果你试图嵌入复合单词“tensorflow”,你将会得到一个词汇表错误。
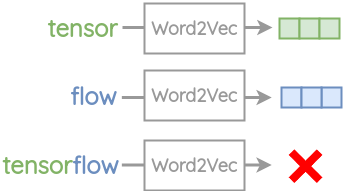
-
形态学:对于词根相同的单词,如“eat”和“eaten”,Word2Vec没有任何的参数共享。每个单词都是根据上下文来学习的。因此,可以利用单词的内部结构来提高这个过程的效率。

FastText
为了解决上述挑战,Bojanowski等提出了一种新的嵌入方法FastText。他们的关键见解是利用单词的内部结构来改进从skip-gram法获得的向量表示。
对skip-gram法进行如下修正:
1. Sub-word生成
对于一个单词,我们生成长度为3到6的n-grams表示。
-
我们取一个单词并添加尖括号来表示单词的开始和结束

-
然后生成长度n的n-grams。例如,对于单词“eating”,从尖括号开始到尖括号结束滑动3个字符的窗口,可以生成长度为3个字符的n-grams。在这里,我们每次将窗口移动一步。
Interactive example of generating 3-grams -
这样,我们就得到了一个单词的n-grams的列表。


不同长度的字符n-grams的例子如下:
| Word | Length(n) | Character n-grams |
|---|---|---|
| eating | 3 | <ea, eat, ati, tin, ing, ng> |
| eating | 4 | <eat, eati, atin, ting, ing> |
| eating | 5 | <eati, eatin, ating, ting> |
| eating | 6 | <eatin, eating, ating> |
-
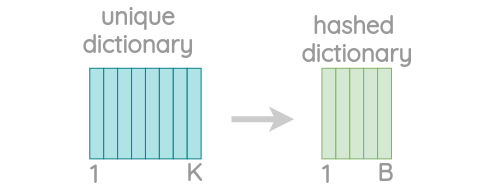
由于存在大量的唯一的n-grams,我们应用哈希来限制内存需求。我们不是学习每个唯一的n-grams的嵌入,而是学习一个总的B嵌入,其中B表示存储桶的大小。文章中用的桶的大小为200万。
Hash dictionary to store n-grams 每个字符n-gram被散列到1到b之间的整数,尽管这可能会导致冲突,但它有助于控制词汇表的大小。本文使用Fowler-Noll-Vo散列函数的FNV-1a变体将字符序列散列为整数值。

2. 使用负采样的Skip-gram
为了理解预训练,让我们以一个简单的玩具为例。我们有一个中心词是“eating”的句子,需要预测上下文中的词“am”和“food”。

1、首先,中心词的嵌入是通过取字符n-grams的向量和整个词本身来计算的。

2、对于实际的上下文单词,我们直接从嵌入表示中获取它们的单词向量,不需要加上n-grams。

3、现在,我们随机采集负样本,使用与unigram频率的平方根成正比的概率。对于一个实际的上下文词,将抽样5个随机的负样本单词。

4、我们在中心词和实际上下文词之间取点积,并应用sigmoid函数来得到0到1之间的匹配分数。
5、基于这种损失,我们使用SGD优化器更新嵌入向量,使实际上下文词更接近中心词,同时增加了与负样本的距离。

论文中的直觉
-
对于形态丰富的语言(如捷克语和德语),FastText显著提高了句法词类比任务的性能。

| word2vec-skipgram | word2vec-cbow | fasttext | |
|---|---|---|---|
| Czech | 52.8 | 55.0 | 77.8 |
| German | 44.5 | 45.0 | 56.4 |
| English | 70.1 | 69.9 | 74.9 |
| Italian | 51.5 | 51.8 | 62.7 |
-
与Word2Vec相比,FastText降低了语义类比任务的性能。
| word2vec-skipgram | word2vec-cbow | fasttext | |
|---|---|---|---|
| Czech | 25.7 | 27.6 | 27.5 |
| German | 66.5 | 66.8 | 62.3 |
| English | 78.5 | 78.2 | 77.8 |
| Italian | 52.3 | 54.7 | 52.3 |
-
FastText比常规的skipgram慢1.5倍,因为增加了n-grams的开销。
-
在单词相似度任务中,使用带有字符ngrams的sub-word信息比CBOW和skip-gram基线具有更好的性能。用子词求和的方法表示词外词比用空向量表示具有更好的性能。
skipgram cbow fasttext(null OOV) fasttext(char-ngrams for OOV) Arabic WS353 51 52 54 55 GUR350 61 62 64 70 German GUR65 78 78 81 81 ZG222 35 38 41 44 English RW 43 43 46 47 WS353 72 73 71 71 Spanish WS353 57 58 58 59 French RG65 70 69 75 75 Romanian WS353 48 52 51 54 Russian HJ 69 60 60 66
实现
要训练自己的嵌入,可以使用官方CLI工具或使用fasttext实现。
157种语言在Common Crawl和Wikipedia的预训练词向量:https://fasttext.cc/docs/en/crawl-vectors.html,各种英语的词向量:https://fasttext.cc/docs/en/english-vectors.html。

英文原文:https://amitness.com/2020/06/fasttext-embeddings/#intuition-on-word-representations
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



