GPT-3诞生,Finetune也不再必要了!NLP领域又一核弹!
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:夕小瑶的卖萌屋 | 论文已上传,文末附下载方式
2018年10月推出的BERT一直有着划NLP时代的意义,然而还有一个让人不能忽略的全程陪跑模型——OpenAI GPT(Generative Pre-Training)在以它的方式坚持着,向更通用的终极目标进发。
最初的GPT只是一个12层单向的Transformer,通过预训练+精调的方式进行训练,BERT一出来就被比下去了。之后2019年初的GPT-2提出了meta-learning,把所有NLP任务的输入输出进行了整合,全部用文字来表示,比如对于翻译任务的输入是“英翻法:This is life”,输出是“C'est la vie”。直接把任务要做什么以自然语言的形式放到了输入中。通过这种方式进行了大规模的训练,并用了15亿参数的大模型,一举成为当时最强的生成模型。
遗憾的是,GPT-2在NLU领域仍并不如BERT,且随着19年其他大模型的推出占据了下风,年初微软推出的Turing-NLG已经到达了170亿参数,而GPT-2只有15亿。这些模型的尺寸已经远远超出了大部分公司的预算和调参侠们的想象。。。已经到极限了吗?
不,“极限挑战”才刚刚开始,OpenAI在十几个小时前悄然放出了GPT第三季——《Language Models are Few-Shot Learners》。

GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
-
对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。 -
对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
为了达到上述目的,作者们用预训练好的GPT-3探索了不同输入形式下的推理效果:
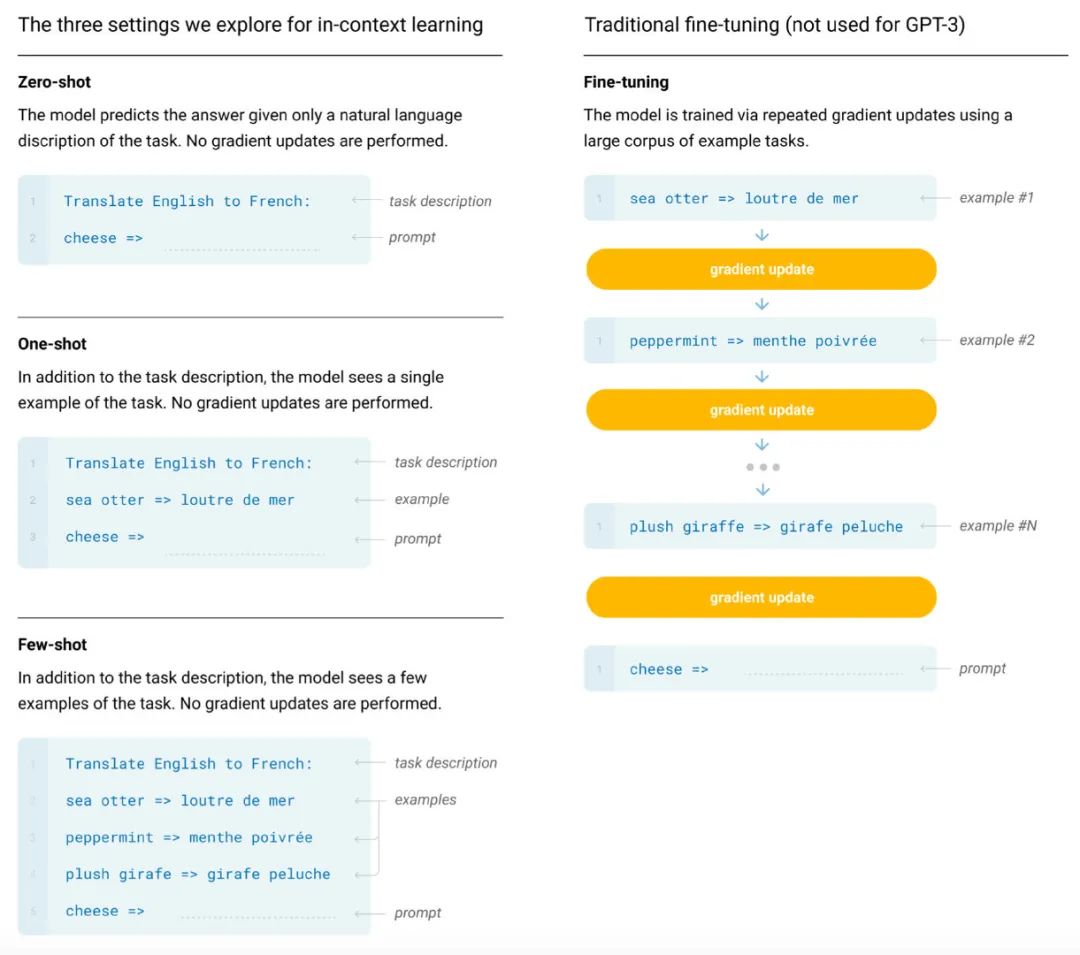
这里的Zero-shot、One-shot、Few-shot都是完全不需要精调的,因为GPT-3是单向transformer,在预测新的token时会对之前的examples进行编码。
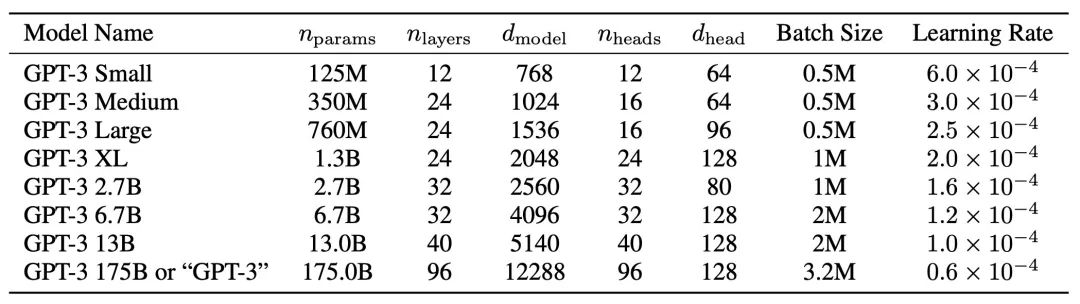
作者们训练了以下几种尺寸的模型进行对比:
实验证明Few-shot下GPT-3有很好的表现:
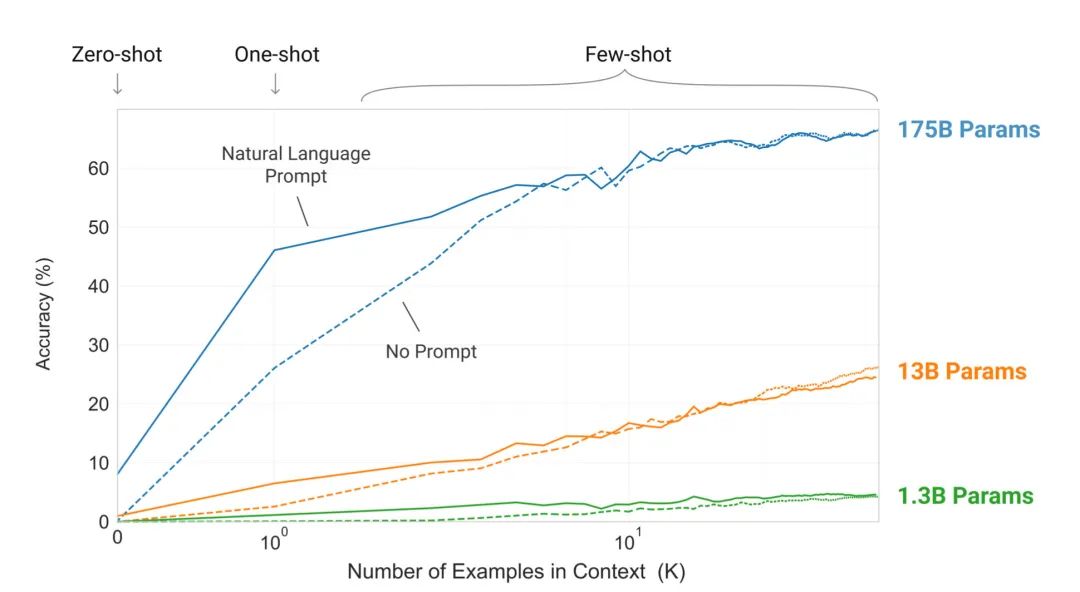
最重要的是,GPT-3在Few-shot设定下,在部分NLU任务上超越了当前Fine-tuning的SOTA。该论文长达72页(Google T5是53页),第10页之后都是长长的实验结果与分析。需要的同学们可以在公众号后台回复「0529」获取下载链接。
显然,GPT-3的模型参数、训练数据和工作量都是惊人的,论文署名多达31个作者,所有实验做下来肯定也耗费了不少时间。虽然一直都存在对于大模型的质疑声音,但我们确确实实从T5、GPT-3这样的模型上看到了NLP领域的进步,众多业务也开始受益于离线或者线上的BERT。事物的发展都是由量变到质变的过程,感谢科研工作者们的不懈努力和大厂们的巨额投入,奥利给。
论文下载
在CVer公众号后台回复:GPT,即可下载本论文
重磅!CVer-论文写作与投稿 交流群已成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满1900+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!



