阿里巴巴首次揭秘电商知识图谱AliCoCo!淘宝搜索原来这样玩!


本文将通过介绍 AliCoCo 的背景、定义、底层设计、构建过程中的一些算法问题,以及在电商搜索和推荐上的广泛应用,分享 AliCoCo 从诞生到成为阿里巴巴核心电商引擎的基石这一路走来的思考。
本文作者:搜索推荐事业部认知图谱团队 Xusheng Luo, Luxin Liu, Yonghua Yang, Le Bo, Yuanpeng Cao, Jinhang Wu, Qiang Li, Keping Yang and Kenny Q. Zhu
背景
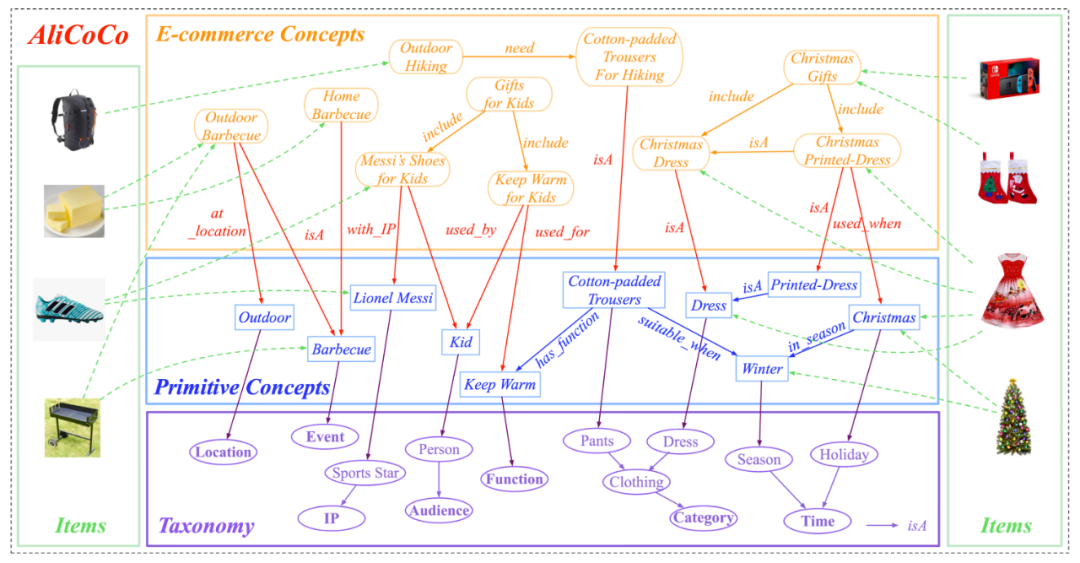
AliCoCo
电商概念层(E-commerce Concepts)
原子概念层(Primitive Concepts)
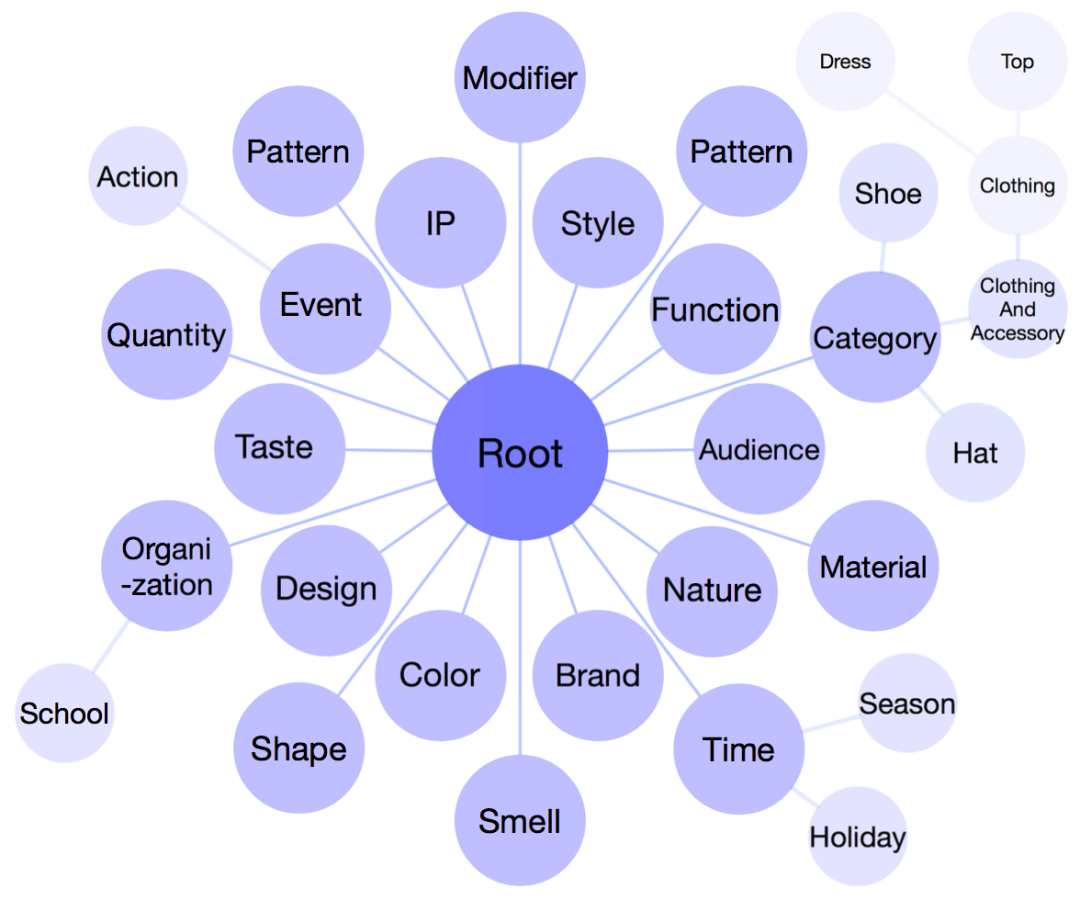
分类体系(Taxonomy)
商品层 (Items)
分类体系(Taxonomy)
原子概念层 (Primitive Concepts)
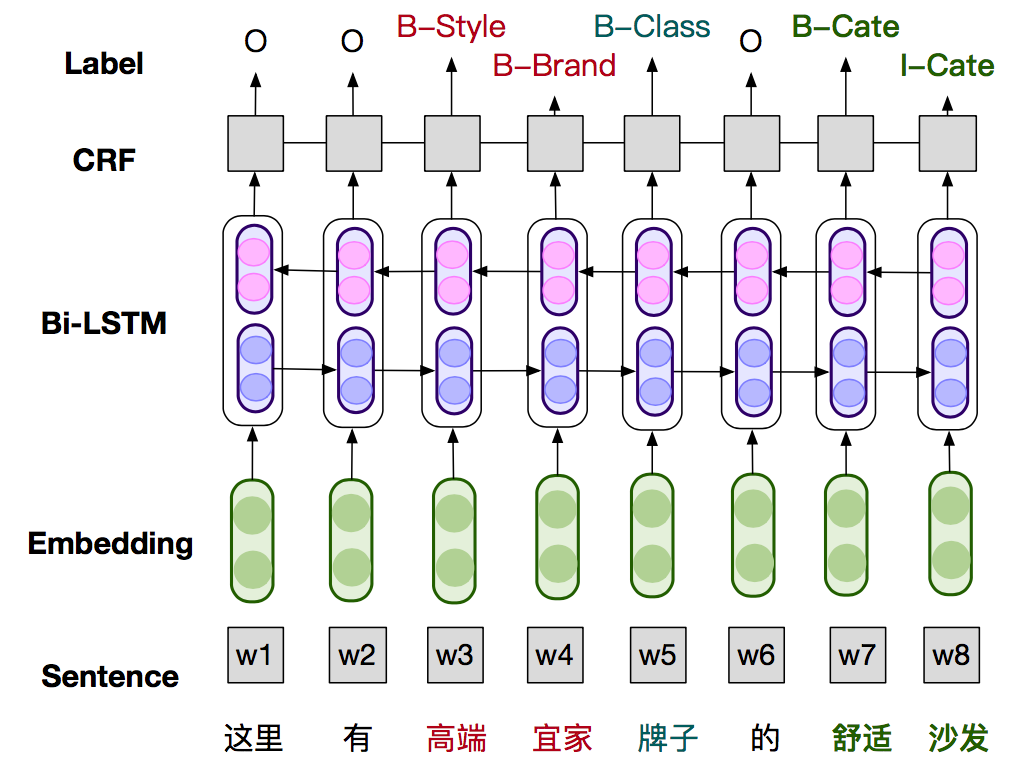
原子概念词汇的挖掘
原子概念之间的上下位关系构建
词汇挖掘
上下位关系构建
Pattern based
Projection learning
 和上位词 embedding
和上位词 embedding  ,有监督去学习一个映射函数
,有监督去学习一个映射函数  ,使得
,使得  和 尽可能地接近。这方面有很多前人的工作
[3, 4]
,其中有一些工作会先将不同的词进行聚类,在每个类别上分别学习不同的映射,取得了较好的效果。具体地,我们学习一个打分函数,用于表征一对候选词之间的上下位关系强弱,并使用多个 matrix 来模拟不同维度的特征(隐式的聚类),其中第 k个 score 计算如:
和 尽可能地接近。这方面有很多前人的工作
[3, 4]
,其中有一些工作会先将不同的词进行聚类,在每个类别上分别学习不同的映射,取得了较好的效果。具体地,我们学习一个打分函数,用于表征一对候选词之间的上下位关系强弱,并使用多个 matrix 来模拟不同维度的特征(隐式的聚类),其中第 k个 score 计算如: 。最后将 k 个 score 过一层全连接得到最终的probability:
。最后将 k 个 score 过一层全连接得到最终的probability: 。之后我们采用交叉熵损失函数进行训练。模型中使用的预训练的词向量是在前面提到的电商语料上用 word2vec 进行训练的。同时,我们针对部分品类词在语料中出现较为稀疏的问题,用 ALaCarte embedding
[5]
进行了强化,其主要思想是学习一个映射关系矩阵
。之后我们采用交叉熵损失函数进行训练。模型中使用的预训练的词向量是在前面提到的电商语料上用 word2vec 进行训练的。同时,我们针对部分品类词在语料中出现较为稀疏的问题,用 ALaCarte embedding
[5]
进行了强化,其主要思想是学习一个映射关系矩阵  ,利用稀疏词
,利用稀疏词  周围的 context 的 embeddings 之和
周围的 context 的 embeddings 之和  对其进行表征:
对其进行表征:
 可以通过利用语料中所有的词
可以通过利用语料中所有的词  进行训练得到:
进行训练得到:

Active learning
电商概念层 (E-commerce Concepts)
电商概念的定义
1)有消费需求
即一个电商概念必须可以让人很自然地联想到一系列商品,反例如“蓝色天空”、“母鸡下蛋”等就不是电商概念。
电商概念的生成
候选生成

电商概念判别
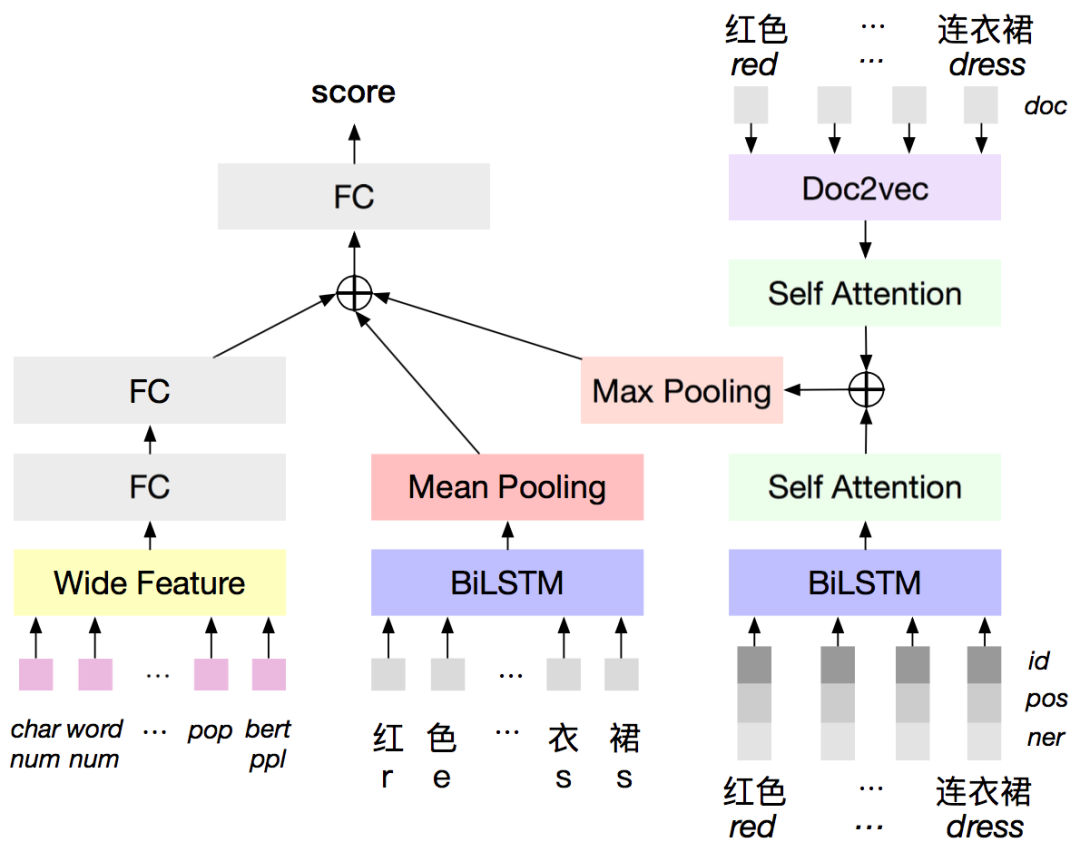
和原子概念的链接
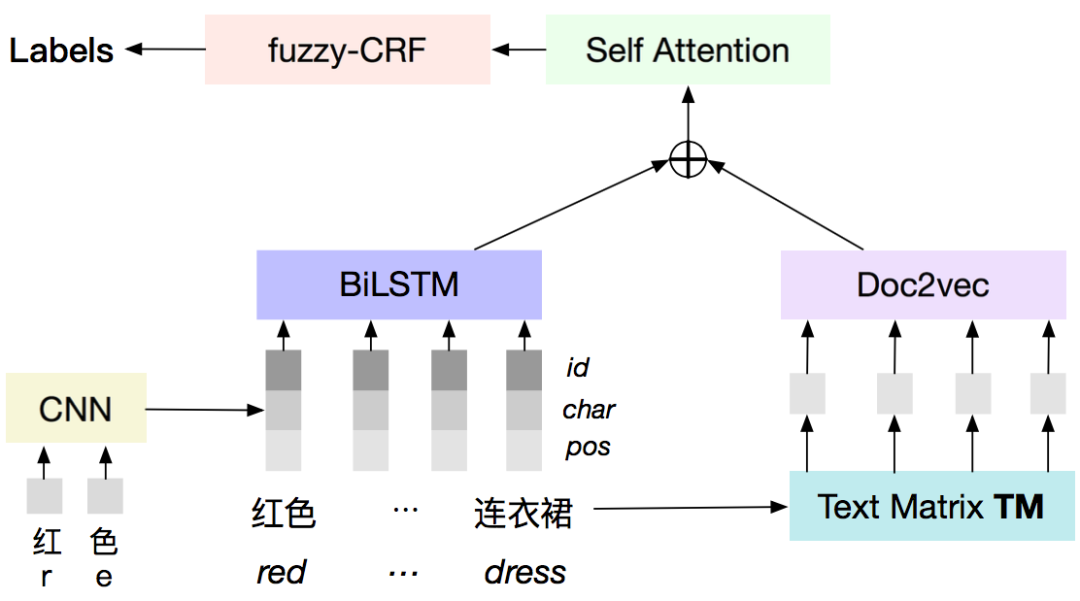
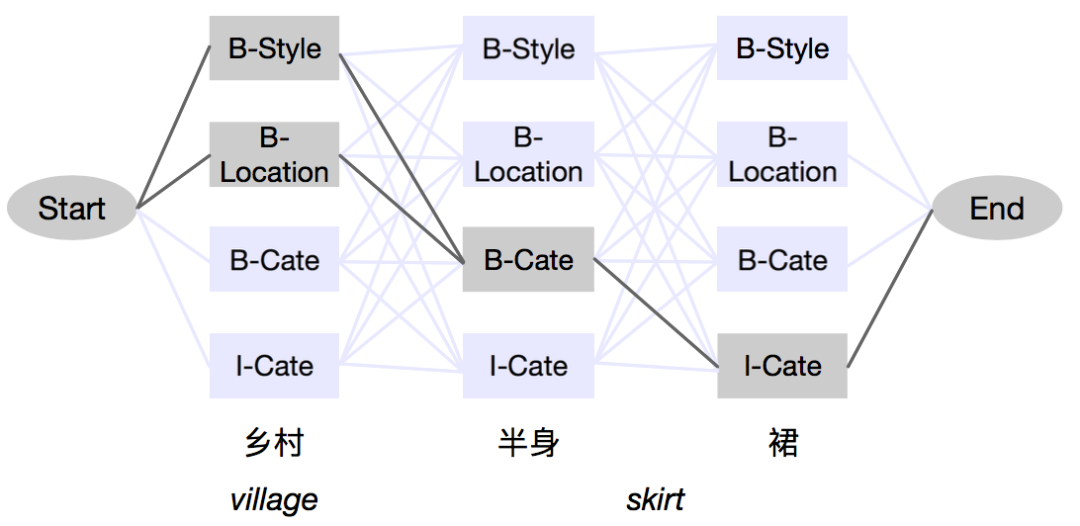
商品关联 (Item Association)
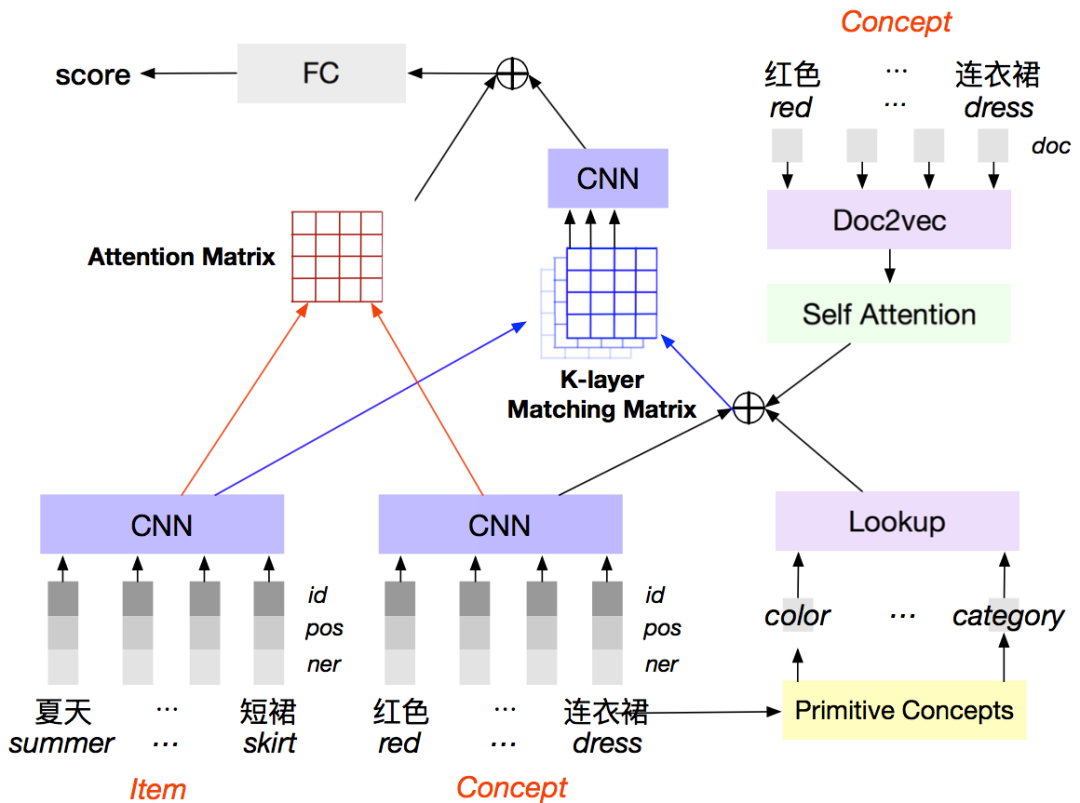
应用
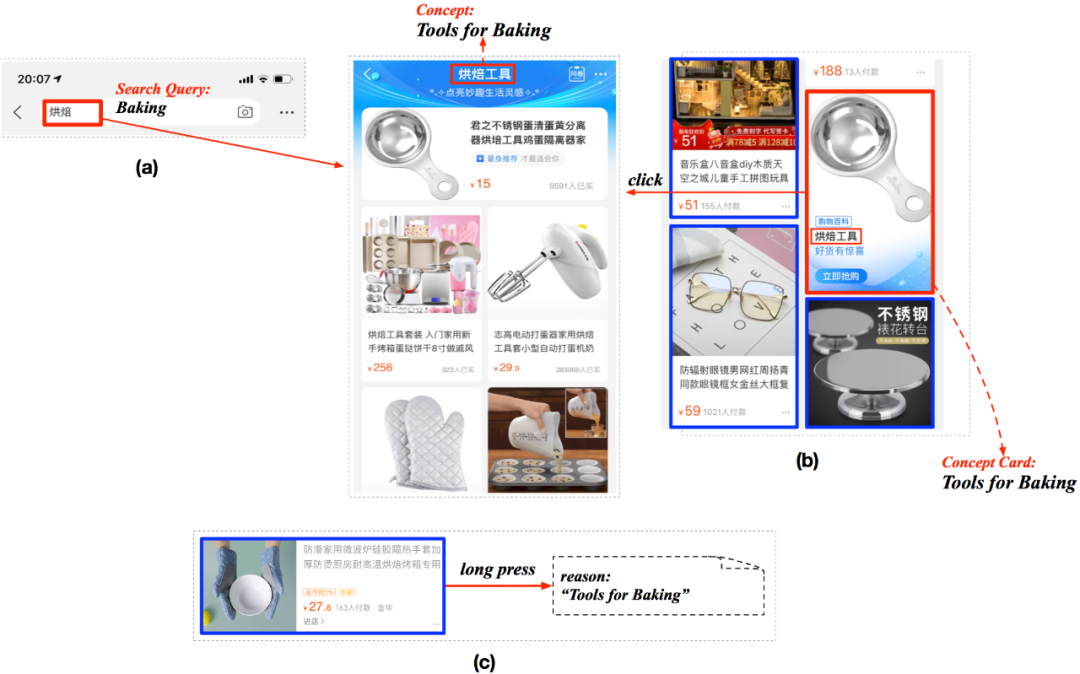
电商搜索
电商推荐
总结

识别下方二维码或点击文末“阅读原文”,查看招聘详情:

推荐阅读
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

登录查看更多
相关内容

Arxiv
4+阅读 · 2019年11月5日
Arxiv
21+阅读 · 2019年5月11日





相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年11月5日
Arxiv
21+阅读 · 2019年5月11日