ACL'21 | 弱标签的垃圾数据,也能变废为宝!

文 | LawsonAbs
编 | 小戏
是不是感觉 NER 领域效果提升太过困难?最近一篇来自 Amazon 的文章提出使用强弱标签结合的方式来解决 NER 的问题。强弱标签结合其实非常立足实际的数据情况——干净又准确的强标签数据非常稀少,更多的是标注质量存在问题的弱标签垃圾数据。如果直接混在一起训练,模型很可能就直接拟合到那些弱标签数据上了(毕竟弱标签数据的量更大....)。如何有效将垃圾数据变废为宝就成为了一个很关键的问题。
尽管本文不是第一个提出使用强弱标签数据结合的方式来解决 NER 问题,但论文实验显示在 E-commerce NER 和 Biomedical NER 上,该方法具有一定的效果。话不多说,让我们进入这篇论文吧!
论文题目:
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
论文链接:
https://arxiv.org/pdf/2106.08977.pdf
![]() 文章在讲什么?
文章在讲什么?![]()
 文章在讲什么?
文章在讲什么?现实世界的场景是:少量的强标签数据(正确地人工标注数据)和大量的弱标签数据。但是之前的模型训练往往要么是基于大量的人工标签数据(不现实&难以为继),要么是使用大量的弱标签数据(模型效果不好)。于是文章采取一种折中的办法,使用少量的强标签数据结合大量的弱标签训练模型。
因此,从实质上讲,这篇文章所做的工作,就是采用少量的强标签和大量的弱标签数据联合分阶段训练模型。在深入模型之前,由于论文中的变量涉及的较多,这里先给出下面会用到的变量解释。
-
:人工标注的标签 -
:弱标签数据的标签 -
:由模型预测得到的标签 -
:根据 和 按照一定规则组合得到的补全( completed)数据的标签
![]() 文章是怎么做的?
文章是怎么做的?![]()
在进入文章的细节架构之前,我们首先看一下模型训练的整个过程。
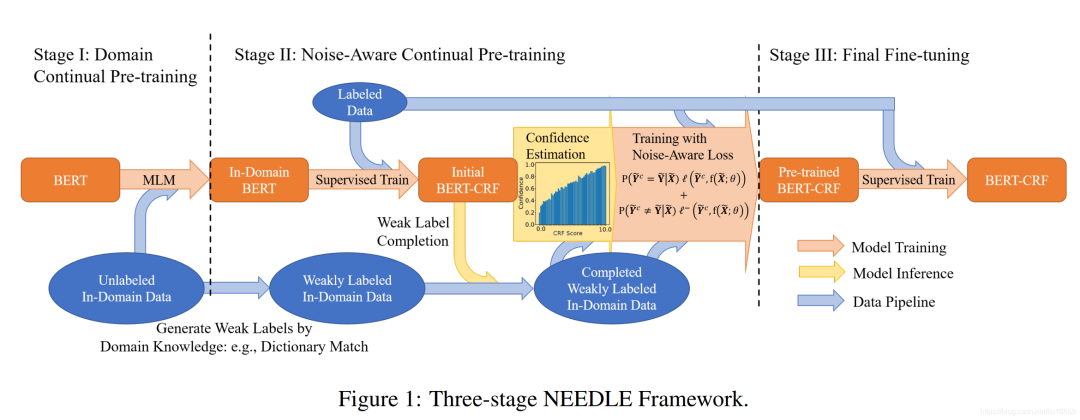
根据上图,我们看到模型训练主要分为三个阶段:
-
在 Stage 1 中会使用无标签数据进行预训练; -
在 Stage 2 中先用强标签进行NER任务训练;然后对弱标签数据进行一个补全操作,再用补全后的弱标签数据进一步训练; -
在 Stage 3 中使用强标签数据进行微调
有了对模型整体的把握,让我们分阶段看各个阶段分别做了什么。
Stage 1
首先,在 Stage 1 中,其核心操作是利用无标签数据进行预训练,预训练的方式 MLM 。而模型从朴素 BERT 变成了 In-Domain BERT。
Stage 2
强标签数据监督训练
完成了 Stage 1 的无监督预训练,从 Stage 2 开始就要进行真正的 NER 训练了。做 NER 的模型结构是 Stage 1 中完成训练的 In-Domain BERT 接上了一个随机初始化的CRF。这个模型先用少量强标签的NER数据监督训练一下,得到 Initial BERT-CRF。接下来,我们就希望能够用大量弱标注的垃圾数据来进一步提升效果。
弱标签数据补全
弱标签的 NER 数据往往标注质量较低,存在实体标注不完全的问题。例如,本文所采用的弱标签数据是利用领域内知识将无标签数据转换而来的。为了提高这些弱标签数据的质量,会先用上面得到的 Initial BERT-CRF 做一个 Weak Label Completion 操作。实际上就是用 Initial BERT-CRF 标注出来的实体补全弱标签数据中大量未标注的部分,公式如下:
Noise-Aware 训练
接下来,就要用这些补全后的弱标签数据进一步训练了。此处存在的问题是弱标签数据存在噪声,模型很容易就过拟合到这些噪声上了。
为此,本文先对每个补全后的弱标签数据 算一个置信度估计,也就是它们的弱标签等于正确标签 的概率: 。这里的置信度生成是根据 Histogram Binning 来实现的,具体做法我们会在下一节细讲。
然后在训练时采用的损失函数,会基于这个置信度估计来计算。直观来说,当我们对一个数据的置信度较高时,我们就希望这个损失函数更“激进”一些,模型拟合得更多一些;置信度较低时,则希望模型拟合得更“保守”一些。文中称这个损失函数为 Noise-Aware Loss Function,其表达式如下:
看到这个复杂的表达式先别害怕,让我们一点一点分析,这个函数的目的是计算 Corrected Weak Labels 和 The Model Prediction Score 之间的损失,这里面的 即第 m 个 Token 的 Golden Label,而 是一个指示函数,其含义是如果后面的这个表达式为真,则值为1,否则为0。
整个公式相当于是一个求期望的过程:
-
当 和 相等时,取 negative log-likelihood 作为损失:
-
当 和 不等时,取 negative log-unlikelihood 作为损失:
Stage 3
Stage 3 阶段就比较清晰了,核心思想就是使用强标签数据在 Pre-trained BERT-CRF 上监督训练,得到最后的 BERT-CRF。
![]() 弱标签置信度估计
弱标签置信度估计![]()
这篇文章的一个亮点就是使用 置信度估计 设计一个损失函数,从而有效利用了弱标签的数据。这个“置信度”衡量了弱标签等于正确标签 的概率: 。其具体计算方式在论文的附录A中给出。
由上一节可知,补全后的弱标签 由两部分组成,分别是原始的弱标签 和 Initial BERT-CRF 补全的标签 。所以 可以拆解成这两部分的一个线性组合,也就是如下这样:
其中 是全部实体标签的数量,而 是原始弱标签数据中标注出的实体数量。
在这个式子中,前面部分的 可以直接赋值为 1。因为原始的弱标签都是通过领域规则转换而来,可信度很高。
主要难点在于后面的 如何计算。这里作者采用模型校准(Model Calibration)时一种常用的置信度估计方式,叫了 Historgram Binning [1]。这个估计的步骤如下:
Step 1:分割出一个 Validation Set,用模型给这些样本标注实体。注意到,这里模型标注结果是基于 Viterbi decoding 得到的,也就是:
根据模型给样本的这个打分 ,我们把样本分为不同的组别中,使得每个组别中的样本属于同一个得分区间。组别 的置信度计算方式如下:
其中, 是该组别中样本的个数, 是模型给出的预测概率。
下面这张直方图就展示了置信度-解码得分之间的关系:
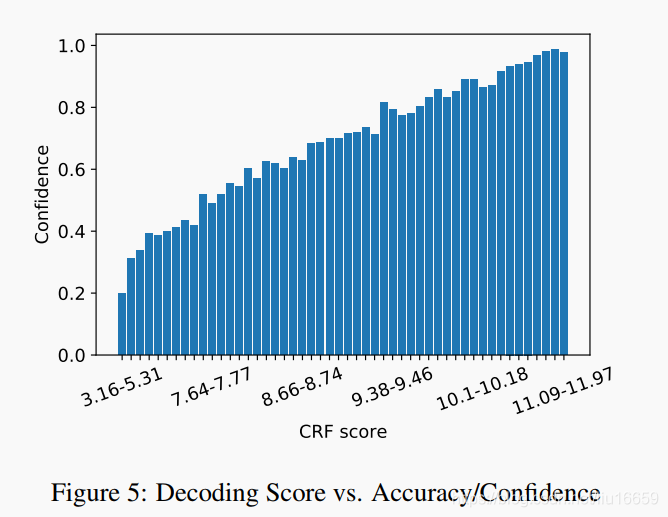
Step 2:在测试时,根据模型的解码打分找到对应的组别。该样本的 将被估计为 。这里的 0.95 是一个人为设置的平滑操作,使得对补全的弱标签置信度估计趋于保守。
![]() 实验
实验![]()
在两种不同领域内进行了模型效果的检测,分别是:E-commerce query domain 和 Biomedical domain。(这两个领域感觉就是这段时间NER模型的主战场了┭┮﹏┭┮,主要是因为这些领域的实体与其它领域的有所不同,所以就需要与之前不同的模型来解决这个问题。)由于E-commerce Multilingual Query NER 和 Biomedical NER 的实验方法大抵相同,下面我们就主要介绍模型在 E-commerce query NER 上的效果。
数据集
作者对实验中使用到的数据进行了一个统计,如下所示:
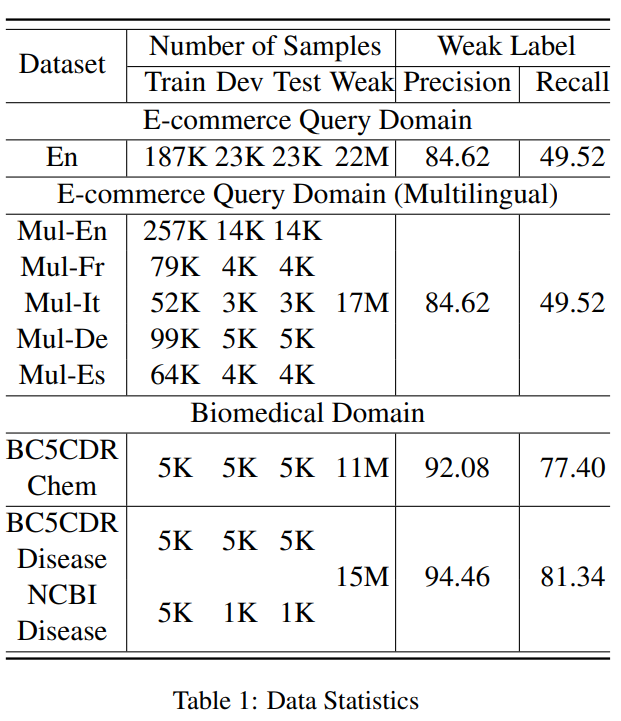
可以看到,仅仅使用weak label时,模型效果不佳,尤其是在recall上的表现,只有不到50。
基线系统与主要结果
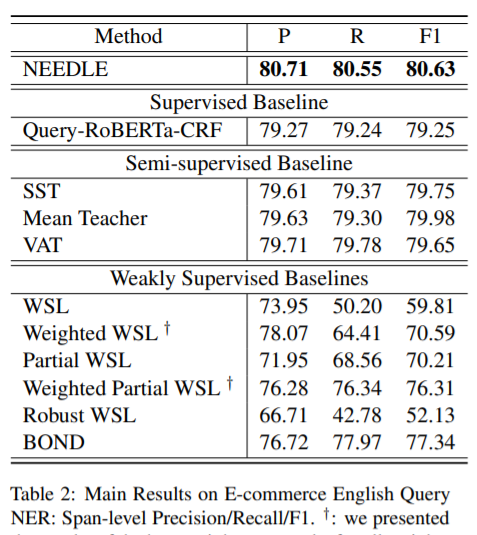
同NEEDLE模型比较的几个基线系统如下所示:
-
Supervised Learning Baseline:直接在强标签数据上微调预训练模型 -
Semi-supervised self-training:使用监督学习得到模型,然后根据这个模型预测得到伪标签进行半监督学习(Wangt et al., 2020; Du et al., 2021) -
Mean-Teacher and VAT:半监督模型的基线系统 -
Weakly supervised learning(WSL):简单的将强标签数据和弱标签数据结合的方法(Mannn and McCallum,2010) -
Weighted WSL:同样是WSL方法,但是在弱标签损失中添加了一个固定值作为权重,从而计算损失。
-
Robust WSL:使用均方误差作为损失的WSL方法,这样会对label noise 鲁棒(Ghosh et al.,2017)。 -
Partial WSL:在WSL的基础上,训练模型时丢弃非实体的弱标签 -
BOND:一种用于弱监督训练的自训练框架(Liang et al., 2020)。上述这些系统在这里不再详细介绍了,更加细致的信息可以参考文中的链接查看提出的论文。
本文提出的方法 NEEDLE,和上述基准模型在 E-commerce 上的实验结果如下所示。可以看到,NEEDLE 取得了SOTA的效果。
消融实验
消融实验无非就是对模型各个组件有效性的检测。使用如下缩写表示模型中的各个组件:
-
WLC: weak label completion -
NAL: noise-aware function -
FT: final Fine-Tuning 实验效果如下:
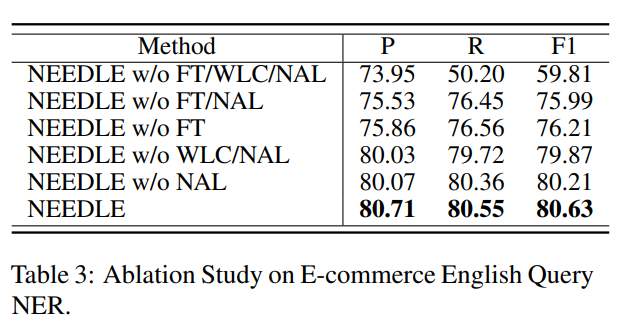
可以看出,所有的模块都是有作用的,并且有一定的互补作用。
分析
基于强弱标签数据,本文提出了一种较好的模型来有效地结合二者,但是还未对两种类型数据的“量”上进行分析,所以论文最后在“量”上分析两种数据对模型的影响,结果如下:
-
弱标签数据的大小对 NEEDLE 模型的影响?实验结果见下图:
可以很明显的观察到,与SST和BaseLine 相比,NEEDLE模型性能随着 Weakly Labled Data 的大小增而提高。
-
两轮Stage II训练 NEEDLE模型中仅包含一个Stage II,现在的假设是使用两轮的Stage II会对实验有影响吗?实验结果是上图中的最后一个小点点,其对应的横坐标是Stage II x2。实验结果表明:三个模型在应用两轮的Stage II 训练时,模型效果都有轻微的上升。
-
分析强标签数据的大小对模型效果的影响?实验结果如下:
这个很明显的两个特征就是:(1)在强标签数据比较少时NEEDLE模型效果比BaseLine 要好2+个点;(2)但是在达到相同的效果的时候,NEEDLE需要的强标签数据大概只是BaseLine系统的1/3。
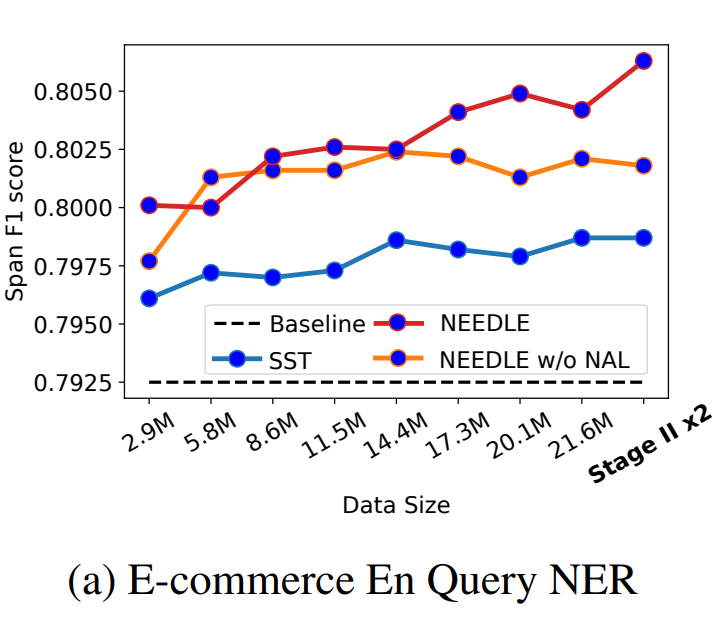 可以很明显的观察到,与SST和BaseLine 相比,NEEDLE模型性能随着 Weakly Labled Data 的大小增而提高。
可以很明显的观察到,与SST和BaseLine 相比,NEEDLE模型性能随着 Weakly Labled Data 的大小增而提高。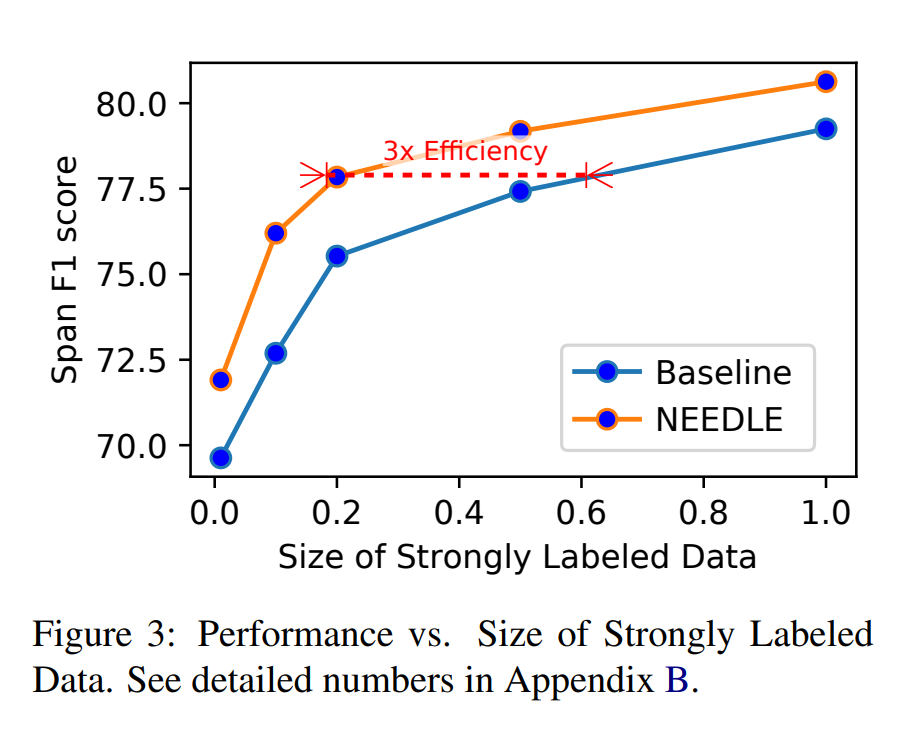 这个很明显的两个特征就是:(1)在强标签数据比较少时NEEDLE模型效果比BaseLine 要好2+个点;(2)但是在达到相同的效果的时候,NEEDLE需要的强标签数据大概只是BaseLine系统的1/3。
这个很明显的两个特征就是:(1)在强标签数据比较少时NEEDLE模型效果比BaseLine 要好2+个点;(2)但是在达到相同的效果的时候,NEEDLE需要的强标签数据大概只是BaseLine系统的1/3。![]() 个人感受
个人感受![]()
基于强弱标签数据结合的方式,利用多阶段训练出一个更优的模型。每个不同的阶段利用不同类型的标签数据(斗胆猜测一下:这个模型可能是作者实习时做的一个工程项目,然后抽象化之后投出来的一篇文章,因为怎么看都觉得这篇文章的工程属性更强)
最后再总结一下本文值得借鉴的几个地方:
-
学习利用 Historgram Binning 进行置信度评测的方法。这种方法在模型校正上很有用处。 -
立足实际问题,提出一个工程上有效的模型,再把该模型抽象化,就是一篇完美的 Paper 啦,这样还怕中不了 ACL 吗?
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Zadrozny В., Elkan C. Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers. In ICML, pp. 609–616, 2001.
 后台回复关键词【
后台回复关键词【




