I2A、MBMF、MVE、DMVE…你都掌握了吗?一文总结强化学习必备经典模型(二)
机器之心专栏
本专栏由机器之心SOTA!模型资源站出品,每周日于机器之心公众号持续更新。
本专栏将逐一盘点自然语言处理、计算机视觉等领域下的常见任务,并对在这些任务上取得过 SOTA 的经典模型逐一详解。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
本文将分 2 期进行连载,共介绍 13 个在强化学习任务上曾取得 SOTA 的经典模型。
第 1 期:DQN、DDQN、DDPG、A3C、PPO、HER、DPPO、IQN
第 2 期:I2A、MBMF、MVE、ME-TRPO、DMVE
您正在阅读的是其中的第 1 期。前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及 API 等资源。
第1期回顾:I2A、MBMF、MVE、DMVE…你都掌握了吗?一文总结强化学习必备经典模型(一)
本期收录模型速览
| 模型 | SOTA!模型资源站收录情况 | 模型来源论文 |
|---|---|---|
| I2A | https://sota.jiqizhixin.com/project/i2a 收录实现数量:2 支持框架:PyTorch、TensorFlow |
Imagination-Augmented Agents for Deep Reinforcement Learning |
| MBMF | https://sota.jiqizhixin.com/project/mbmf 收录实现数量:4 支持框架:PyTorch、TensorFlow |
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning |
| MVE | https://sota.jiqizhixin.com/project/mve | Model-based value estimation for efficient model-free reinforcement learning |
| ME-TRPO | https://sota.jiqizhixin.com/project/me-trpo 收录实现数量:2 支持框架:TensorFlow |
Model-ensemble trust-region policy optimization |
| DMVE | https://sota.jiqizhixin.com/project/dmve | Dynamic Horizon Value Estimation for Model-based Reinforcement Learning |
强化学习有四个基本组件:环境(States)、动作(Actions)、奖励(Rewards)、策略(Policy)。其中,前三项为输入,最后一项为输出。
强化学习一种普遍的分类方式是根据询问环境会否响应agent的行为进行分类,即无模型(model-free)和基于模型(model-based)两类。其中,model-free RL算法通过agent反复测试选择最佳策略,这也是研究比较多的领域,这些算法是agent直接和环境互动获得数据,不需要拟合环境模型,agent对环境的认知只能通过和环境大量的交互来实现。这样做的优点是通过无数次与环境的交互可以保证agent得到最优解。往往在游戏这样的没有采样成本的环境中都可以用model-free;model-based RL算法根据环境的学习模型来选择最佳策略,agent通过与环境进行交互获得数据,根据这些数据对环境进行建模拟合出一个模型,然后agent根据模型来生成样本并利用RL算法优化自身。一旦模型拟合出来,agent就可以根据该模型来生成样本,因此agent和环境直接的交互次数会急剧减少,缺点是拟合的模型往往存在偏差,因此model-based的算法通常不保证能收敛到最优解。但是在现实生活中是需要一定的采样成本的,采样效率至关重要,因此,向model-based方法引入model-free是一个提升采样效率的重要方式。在model-based RL中不仅仅有原来model-free中的结构,还多了一个model,原本在model-free中用来训练值函数和策略函数的经验有了第二个用处,那就是model learning,拟合出一个适当的环境模型。
一、Model-based
1.1 I2A
I2A是Deepmind提出的一种想象力增强的model-based强化学习方法,是一种结合了model-free和model-based的深度强化学习的新架构。其目的是使rollout policy来模仿最终的想象力增强的策略, 以此来进行rollout policy 的训练。也就是说,通过和环境交互采样后,让系统学习到一个可编码的环境。在决策时,先考虑通过模型“想象”后续情况,然后得到一个策略。得到策略后,再将这个策略用model-free方式进行表征。与大多数现有的model-based RL学习和计划方法相比,I2A学习解释来自学习环境模型的预测,以任意的方式构建隐性计划,将预测作为深度策略网络的额外背景。I2A显示出更好的数据效率、性能和对模型错误指定的稳健性。
I2A的结构如下:
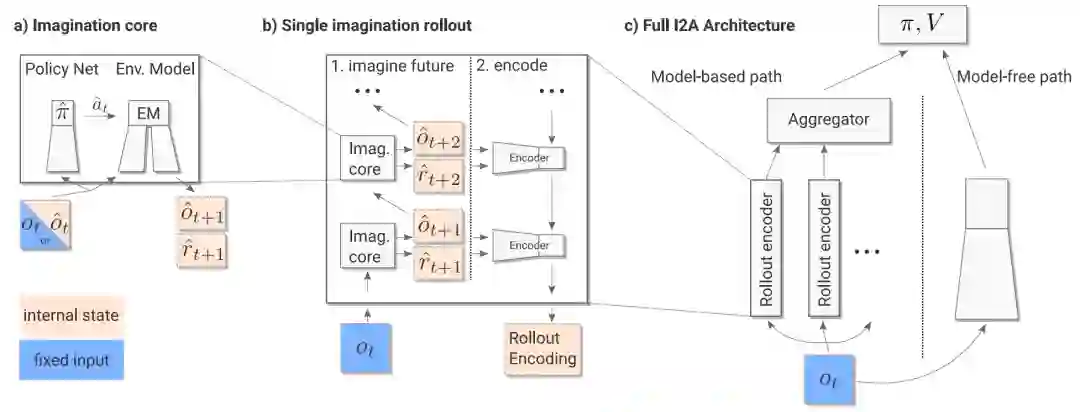
I2A利用环境模型,实现了利用想象力来增强model-free的agent。在给定当前信息的情况下,可以通过查询环境模型来对未来进行预测。使用环境模型来模拟想象的轨迹,使用神经网络解释这些轨迹,并作为额外的背景提供给策略网络。一般来说,环境模型是任何可以从agent轨迹中以无监督的方式进行训练的递归结构:给定一个过去的状态和当前的行动,环境模型预测下一个状态和来自环境的任何数量的信号。I2A特别考虑建立在最近成功的行动条件下的下一步预测器的环境模型,它接收当前的观察(或观察的历史)和当前的行动作为输入,并预测下一个观察,以及可能的下一个奖励。在未来的多个时间步长中推出环境模型,通过用现在的真实观测值初始化想象的轨迹,随后将模拟的观测值输入模型。每次rollout选择的行动都来自于rollout策略πˆ。环境模型和πˆ构成了想象力的核心模块,它预测下一个时间步长(图1a)。想象力核心IC用于生成n个轨迹Tˆ1, . . . , Tˆn。每个想象的轨迹Tˆ是一个特征序列(ˆf_t+1, . . ,ˆf_t+τ),其中,t是当前时间,τ是rollout的长度,ˆf_t+i是环境模型的输出(即预测的观察和/或奖励)。
轨迹可能包含奖励序列以外的信息(一个轨迹可能包含一个有信息的子序列,例如解决一个子问题,但不会造成更高的奖励)。使用一个rollout编码器E,它将想象中的rollout作为一个整体来处理,并学会解释它,即通过提取任何对agent的决定有用的信息,甚至在必要时忽略它(图1b)。每条轨迹都被单独编码为一个rollout嵌入e_i = E(Tˆi)。最后,利用一个聚合器A将不同的rollout嵌入转换为一个单一的想象代码c_ia = A(e1, ... , en)。I2A的最后一个组成部分是策略模块,它是一个网络,从mode-based预测中获取信息c_ia,以及model-free路径的输出c_mf(一个只将真实观察作为输入的网络,见图1c,右),并输出想象力增强的策略向量π和估计值V。因此,I2A学会了结合其model-free和想象力增强的路径的信息;如果没有model-based的路径,I2A就会简化为一个标准的model-free网络。因此,I2A可以被认为是通过提供来自model-based规划的额外信息来增强model-free agent,并且严格来说比底层的model-free agent具有更多的表达能力。
图2给出了I2A中用到的环境模型。
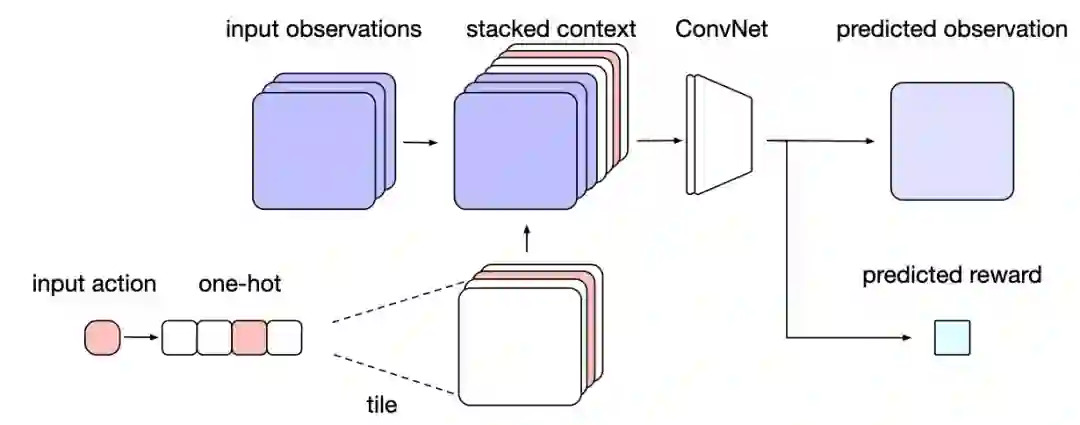
图2.环境模型。广播输入动作并将其与观察结果相连接。卷积网络将其转化为输出图像的像素级概率分布和奖励的分布
当前 SOTA!平台收录 I2A 共 2个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| I2A | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/i2a |
1.2 MBMF
Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning(MBMF)方法的核心为:首先通过agent执行随机策略获取一定数量的样本用于建立动力学模型;然后使用传统控制方法依托所学习的动力学模型进行规划,并得到专家轨迹;使用模仿学习从专家轨迹中学习出一个参数化策略;将学习得到的参数化策略作为model-free强化学习算法的起始策略。具体的,将神经网络与模型预测控制(model predictive control,MPC)相结合,提出一种高效的适用于解决高维、富接触问题的model-based 算法,其中模型使用深度神经网络搭建,此外还提出了一种使用model-based学习器初始化model-free学习器以实现高奖励并大幅降低样本复杂性的方法。
首先介绍model-based算法。使用参数化的深度神经网络作为动力学方程,θ 为网络的权重。输入当前状态s_t和动作a_t,利用下式求解下一个状态:
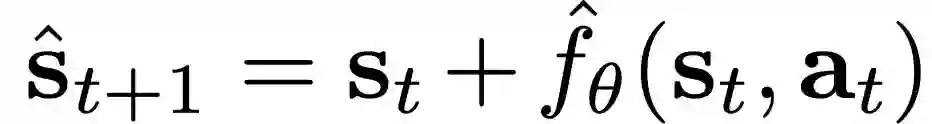
为了训练动力学方程,从满足初始分布的初始状态开始执行随机动作采样,记录长度为T的轨迹。把轨迹分片成输入( s_t, a_t ) 和对应的label s_ (t + 1) − s_ t。然后对其进行标准化处理(减平均值除以标准差),使得loss函数平等的权衡state的各个维度。同时对数据添加zero mean高斯噪声提高模型鲁棒性,将这些训练数据存储到数据集D中。
通过随机梯度下降最小化误差训练模型:
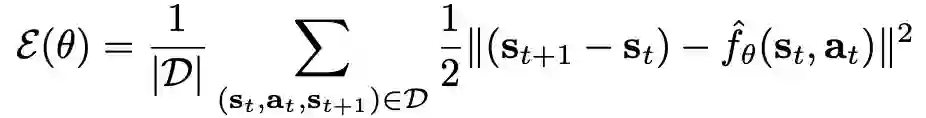
当在训练集D上训练时,同时会在验证集D_val 上计算均方误差作为方程预测能力的评估,但这个误差只是评估模型对下一个状态的预测能力。为了具备对未来的预测能力,通过前向传播H次计算H-step 验证误差。对于D_val上的每一个给定的实际动作序列,将ground-truth的对应状态序列和动力学模型的多步状态预测进行比较:
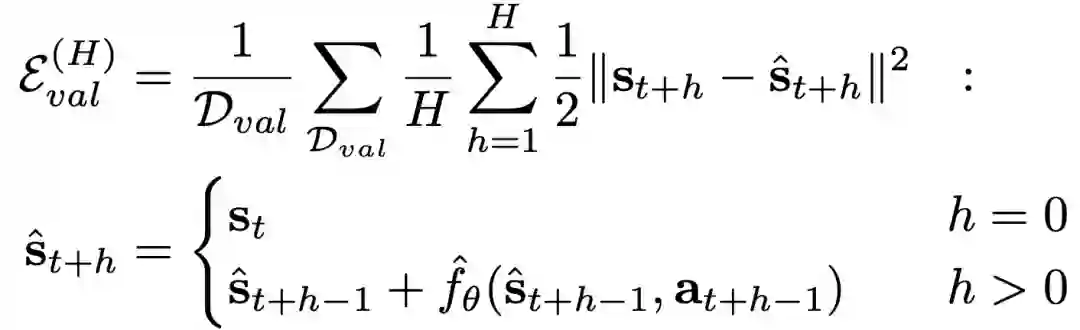
为了能够在任务中编码使用学到的模型和奖励函数,本文形式化定义了一个计算简单且误差鲁棒的model-based控制器。首先使用学到的动力学模型优化H-step视野的动作序列:
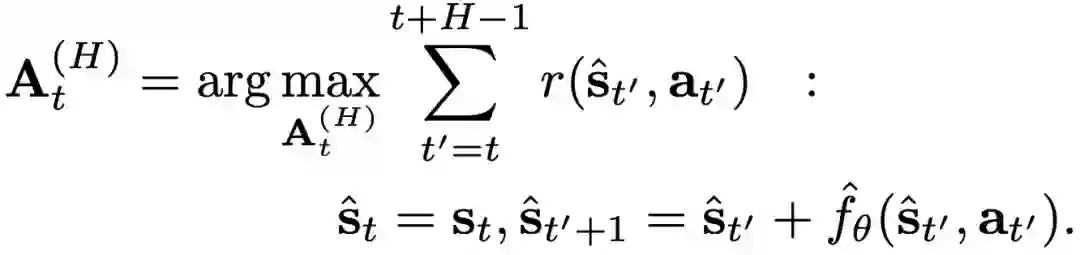
使用一种简单的random-sampling shooting方法来求近似解:随机生成K个候选动作序列,用学到的模型生成对应的状态序列,由此可以计算奖励序列,最后选取期望累计奖励最高的动作序列。同时使用model predictive control(MPC):策略只执行第一个动作,得到下一个状态,在下个时间步长重新计算最优动作序列。
本文使用交叉迭代方法收集当前模型的数据和使用当前混合数据重新训练模型的方式来增加额外的同策略数据。这种方式减轻了数据的状态-动作分布和model-based控制器的分布之间的不一致性来提高性能。

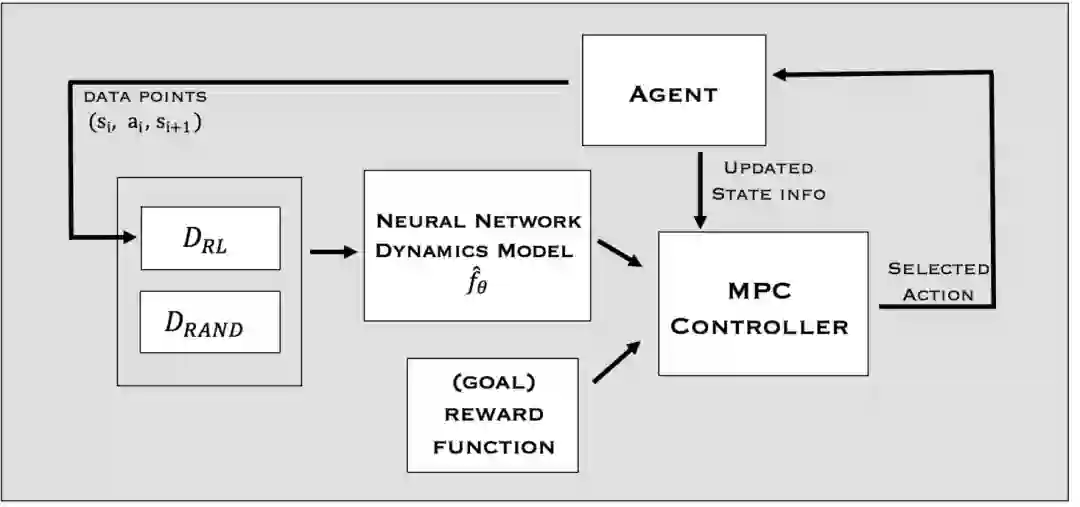
图3. 算法1的说明。在第一次迭代中,执行随机动作并将随机动作用于初始化DRAND。在接下来的所有迭代中,这个迭代程序被用来训练动力学模型,运行MPC控制器进行动作选择、汇总数据,并重新训练模型
其次,介绍MBMF方法。MBMF的主要思想是训练一个策略来模拟学到的model-based控制器,然后把这个策略作为model-free RL学习的初始策略。首先用MPC控制器收集样例轨迹,构造数据集D*,然后训练一个神经网络策略π_ϕ ( a ∣ s ) 来拟合D*中的专家轨迹。然后使用行为克隆目标函数训练参数:
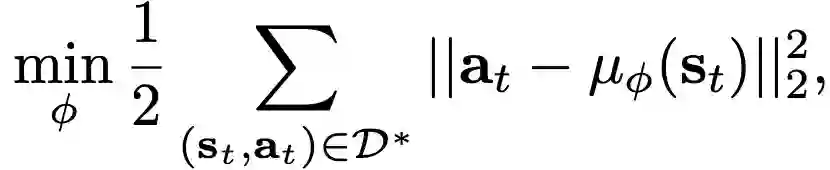
为了达到期望的性能表现,解决数据分布问题,本文使用DAGGER方法:迭代训练策略,执行同策略,查询“专家”MPC控制器访问的状态的正确动作,然后重新训练策略。初始化完成后得到策略π_ϕ 作为model-free的初始状态。这里可以选择不同的model-free方法,在作者原文中用到的是TRPO。
当前 SOTA!平台收录MBMF共 4 个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
MBMF |
前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/mbmf |
1.3 MVE
MVE将环境模型引入到model-free RL方法中,即Model-Based Value Expansion。传统方法对于Q值的预估(DDPG、DQN)是通过bootstrapped的方式来更新参数的,而MVE把环境模型先rollout一定步长次数之后再进行Q值预估。也就是说,在传统的更新方式中,target Q-value使用的是下一步Q-value的预估,而MVE中,target Q-value是先通过环境模型进行模拟一段路径之后,再进行Q-value预估。这样Q-value的预估就融合了基于环境模型的短期预估以及基于target_Q网络的长期预估。
MVE假设有一个近似的动态模型ˆf:S×A→S和奖励函数r来提高策略π的价值估计。给出H-step MVE的定义:使用从模型sˆt=ˆf^π(ˆst-1)在π下得到的想象的奖励报酬rˆt=r(ˆs_t, π(ˆs_t)),定义给定状态V^π(s_0)的价值的H-step模型价值扩展(MVE)估计:
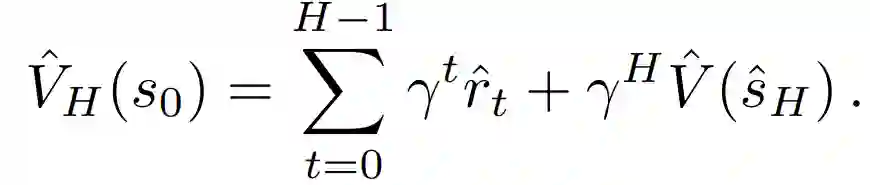
H-step MVE将s_0的状态值估计分解为由学习动态预测的部分和由Vˆ估计的尾部。MVE在H-step horizon不稀疏的情况下最有用,即使在稀疏的奖励环境下,预测未来状态也会提高critic的准确性。此外,MVE也可以用于state-action估计。
下面具体演示如何在一般的 actor-critic 设置中应用MVE来改进目标Q值,以实现更快的收敛。具体实现依赖于一个参数化的actor π_θ和critic Q _ϕ, 如果可以如下计算出一个单独的参数化actor,则可以将其删除:
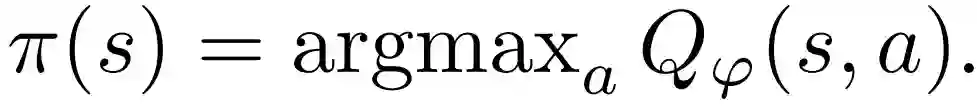
假设actor-critic 方法提供了一个可微调的actor损失和critic损失。这些损失是θ、ϕ以及transitions τ=(S、A、R、S_0)的函数,从某种分布中取样D。MVE 依赖于从过渡的经验分布 β 的近似固定点构造。它依赖于当前的策略来想象最多提前H-step。
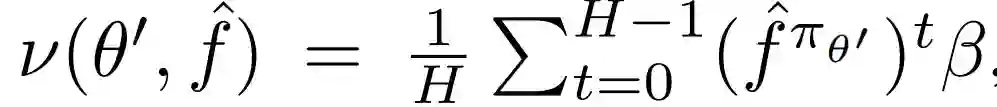
从ν中取样的transitions相当于从H想象中的未来的任何一点取样,当从β中取样的状态开始。MVE增强的方法遵循通常的actor-critic 模板,但critic训练使用MVE目标和从ν中取样的transition(如下Algorithm 1)。

假设用target actor进行rollout,其参数是以前迭代的指数加权平均数,以便与DDPG相比较,DDPG使用target actor来计算目标值估计。取H=0,ν(θ', ˆf) = β ,使用多层全连接的神经网络来表示Q函数和策略,使用DDPG描述的actor和critic的损失。
此外,不使用想象的缓冲器来保存模拟状态,而是通过从ν(θ',fˆ)中取样来即时生成模拟状态。从ν中进行分层抽样,每次有H个依赖性样本,在Algorithm 1 Line 11中,每个t∈{0,..., H - 1}都是分层抽样。首先,从β中抽出一个真实的过渡τ_0 = (s-1, a-1, r-1, s_0),这是根据探索性策略与环境互动观察到的过渡的经验分布。使用学到的动力学模型ˆf来生成sˆt和rˆt。由于π_θ'在θ, ϕ的联合优化过程中会发生变化,这些模拟状态在批处理后立即被丢弃。然后采取随机的∇_ ϕ步骤来最小化Q_ ϕ的基于ν的贝尔曼误差:
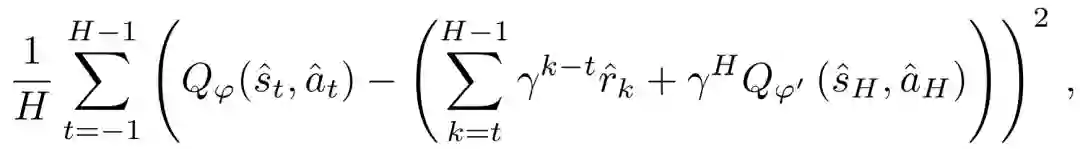
其中Q_ϕ'和和aˆt=π_θ'(ˆst)使用目标参数值(Algorithm 1的第11-13行)。因此,贝尔曼误差的每一次观察总是依赖于一些真实数据。对于动态的ˆf,使用了一个有8层128个神经元的神经网络网络,每个神经元有固定的10^-3的学习率,经过训练可以预测实向量值状态的差异。
MVE通过仅将利用 model 的 imagination 保持在fixed length来控制 model 的不确定性。使用 learned model 来估计 short-term horizon,用传统的 Q-learning 估计 long-term horizon 并将二者结合起来,实现 data-efficient。MVE的核心是使用近似的dynamic model f^:S×A→S 和真实的reward function r 来改进在策略π 下的值估计,让critic学习效果更好。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| MVE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/mve |
1.4 ME-TRPO
Model-free RL算法往往会有很高的sample-complexity,无法应用在真实世界的环境中,而经典的Model-based RL算法会有很高的model bias,所以ME-TRPO使用了emsemble的方式来保持模型的不确定性,通过改变初始化权重和训练输入序列来区分神经网络。
成功的model-free强化学习方法反复收集数据,估计策略梯度,改进策略,然后丢弃数据。相反,model-based的强化学习更广泛地使用数据;它使用所有收集的数据来训练环境的动态模型。经典的the vanilla model-based reinforcement learning algorithm的流程如Algorithm 1所示:

dynamic model使用神经网络进行建模。即输入一个状态和一个动作,预测状态的变化,则下一个状态可以表示为神经网络输出+输入之和。但是,vanilla算法有诸多弊端,例如梯度爆炸、梯度消失、策略在数据稀疏分布处更新等。本文提出了ME-TRPO算法,与vanilla算法的三种不同在于:拟合了一组dynamic model {f_ϕ1,…,f_ϕK} 。差异在于初始化权重不同,以及训练的mini-batch的顺序不同;使用TRPO算法代替BPTT优化策略;使用model emsemble在验证集监督策略性能,策略性能不再提升时立即停止迭代。
ME-TRPO的伪代码如下:

策略优化。为了克服BPTT的问题,考虑可以使用model-free RL文献中的似然比方法,例如Vanilla Policy Gradient (VPG)、Proximal Policy Optimization (PPO)、Trust Region Policy Optimization (TRPO)等。在作者文献中最好的结果是由TRPO实现的。为了估计梯度,使用学到的模型来模拟轨迹,具体如下:在每一步长,随机选择一个模型来预测当前状态和行动的下一个状态。这避免了策略在一个episode中对任何单一模型的过度拟合,从而保证更稳定的学习。
策略验证。使用学到的K个模型监测策略的性能。具体来说,计算策略改善的模型的比率:
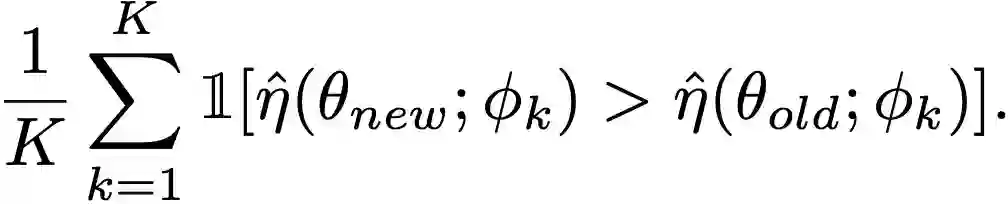
只要这个比率超过某个阈值,当前的迭代就会继续。在实践中,在每5次梯度更新后对策略进行验证,使用70%作为阈值。如果该比率低于阈值,可以容忍少量的更新,如果性能提高,则终止当前的迭代。然后,重复整个过程,用策略收集更多的真实世界数据,优化模型组合,并使用模型组合来改进策略。这个过程一直持续到达到真实环境中的理想性能。
当前 SOTA!平台收录ME-TRPO共2个模型实现资源。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| ME-TRPO | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/me-trpo |
1.5 DMVE
基于模型的动态地平线价值扩展( Dynamic-horizon Model-based Value Expansion,DMVE)在不同的 rollout horizons 下,调整world model的使用。受可用于视觉数据新颖性检测的基于重建技术的启发,引入带有重建模块的world model进行图像特征提取,以获得更精确的价值估计。原始图像和重建图像都被用来确定适应性价值扩展的适当horizon。
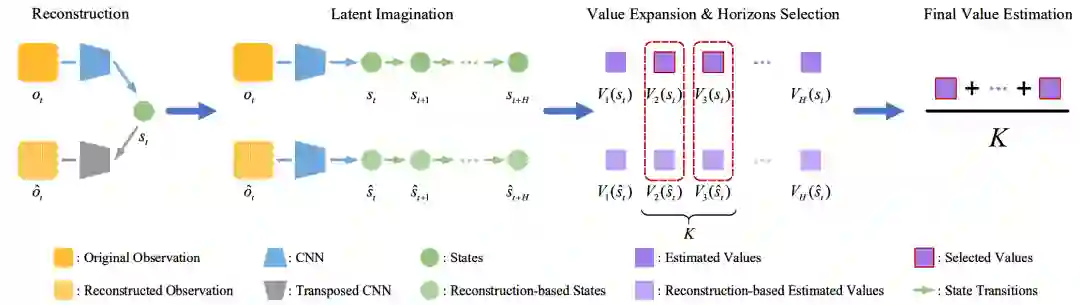
图4. DMVE概述。为了估计状态值,DMVE首先采用了一个重建网络来重建原始观测。然后,将原始图像和重建图像送入过渡模块,进行 H-step latent imagination,并以不同的 rollout horizons h=1,2,...,H 计算两者的 value expansion 。之后,选择对应于原始图像和重建图像之间前K个最小值扩展误差的horizon。最后,从与所选horizon相对应的扩展值中取平均值进行数值估计
DMVE算法伪代码如下:

DMVE框架的核心是一种类似MVE的算法,利用世界模型(world model)、行动模型(action model)和价值模型(value model)来估计状态值。
World model。许多model-based RL方法首先建立一个世界模型,并进一步用它来推导行为。在学习世界模型的基础上,模型学习和策略学习的过程可以交替并行。通常,世界模型提供了一个系统的动态,从当前的状态和行动映射到下一个状态,并对这种transition给予奖励。DMVE使用的world model通过重建原始图像来学习动态的规划。同时,这种基于重构的架构适合于动态水平线的选择。世界模型w_θ是由以下部分组成的:

视觉控制的任务被表述为部分可观察的马尔可夫决策过程( Partially Observable Markov Decision Process, POMDP),因为agent不能直接观察这种任务的基本状态。它可以被描述为一个7元组(S, A, O, T, R, P, γ),其中S表示状态集合,A表示行动集合,O表示观察集合。agent在一连串的离散时间步长中的每一步与环境互动。T(s_t+1 | s_t, a_t)是状态s_t∈S中行动a_t∈A导致状态s_t+1的条件转换概率。R(s_t, a_t)是在状态s_t下执行行动a_t的实值奖励,P表示观察概率P(o_t|s_t+1, a_t),其中,o_t代表agent的观察,执行行动a_t,世界移动到状态s_t+1。γ∈(0,1)是一个折扣系数。策略π(s)从环境状态映射到行动。在每个时间步长t,环境处于某个状态s_t∈S,agent在一个状态下选择一个可行的行动a_t∈A,表征环境以概率T(s_t+1 | s_t, a_t)过渡到状态s_t+1∈S。在环境中进行的行动之后,agent收到一个概率为P(o_t | s_t+1, a_t)的观察o_t∈O,以及一个数字奖励R(s_t, a_t)。然后,上述互动过程重复进行。RL的目标是通过使累积奖励最大化来学习一个最佳策略:
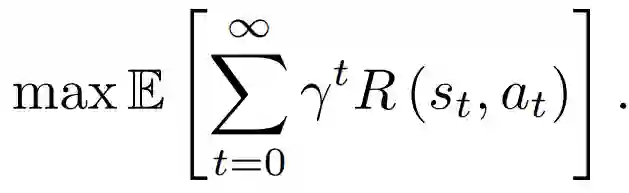
在POMDP设置中,状态不能直接获得,因此应用表征模块(representation model)将观察到的行动映射到低维连续向量,这些向量被视为马尔科夫转换( Markovian transitions)状态。重建模块从状态中估计原始观测值,并通过最小化重建误差确保状态能够代表原始输入数据中的有效信息。奖励模块根据环境反馈的实值奖励,预测想象轨迹中的奖励。过渡模块(transition module)根据当前的状态和行动来预测下一个状态,而没有看到原始的观察结果。过渡模块被实现为一个循环的状态空间模型( Recurrent State Space Model,RSSM)。表征模块是RSSM和卷积神经网络的结合。重建模块是一个转置的CNN,而奖励模块是一个密集网络。所有四个模型组件都通过随机反向传播进行联合优化。
Policy Learning。采用actor-critic方法进行策略学习。除了估计的值函数之外,actor-critic法还有一个独立的结构来表示策略。策略结构即actor,因为是用来推导行为的。同时,值函数为critic,因为它批评由actor决定的行为。对于状态s_t,actor和critic模型被定义为:
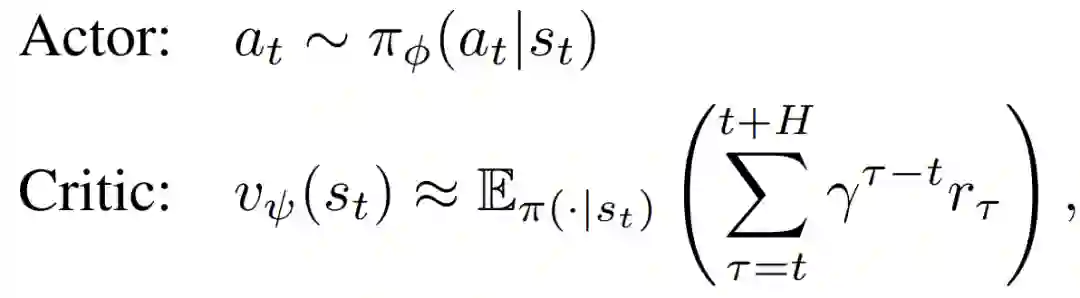
actor和critic模型均为密集网络(dense network)。状态值需要为actor和critic模型优化进行估计。MVE可以通过假设一个近似的动力学模型和一个奖励函数来改进值的估计。由于上述世界模型包含价值扩展所需的元素,可以用它来估计状态值。选择一个h∈{1,2,...,H},可以用想象的轨迹计算s_t的价值估计:
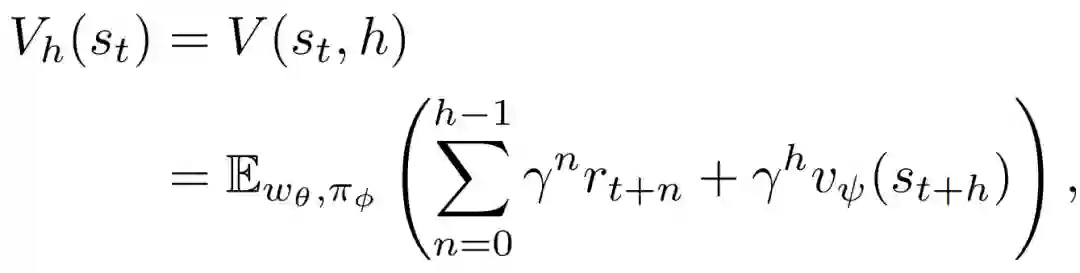
本文使用的是 MVE-LI (MVE的变体),状态s_t的估计值可以表示为V_h(s_t),在估计了状态值之后,可以优化actor和critic神经网络,而世界模型是固定的。MVE-LI中actor和critic模型的学习目标被设定为:
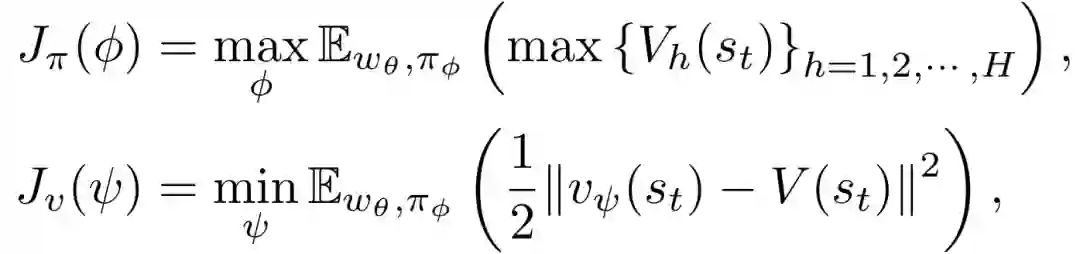
MVE-LI以一个固定的最大rollout horizon H想象潜在空间中的未来状态。然而,对于不同的imagination horizons h∈{1,2,...,H},可以为状态s_t估计不同的值:
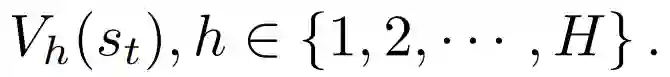
给定最大rollout horizon H,可以用世界模型得到不同h∈{1,2,...,H}的数据序列的价值估计V_h,其中,L表示序列长度。首先,时间步长t的状态可以通过st∼w_θ(s_t | s_t-1, a_t-1, o_t)得出。随后,状态s_t的值可以通过以下方式估计出来:
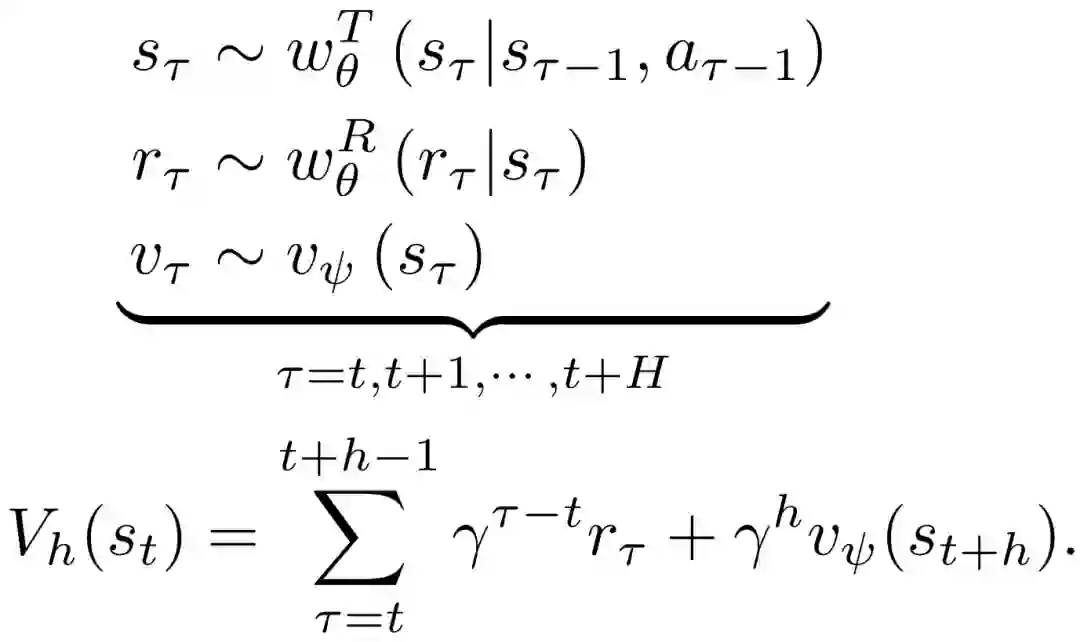
同样,对于重建的图像oˆt∼wOθ(ˆo_t|s_t),基于重建的状态可以通过sˆt∼wSθ(ˆs_t|s_t-1, a_t-1, oˆt)得出,相应的值可以通过如上相同的过程来估计。给定所选 horizons 的数量K,rollout horizons 的集合H可以通过以下方式确定:
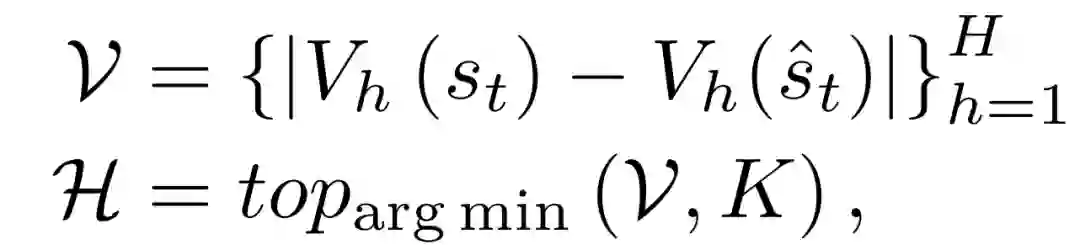
DMVE的最终价值估计为:
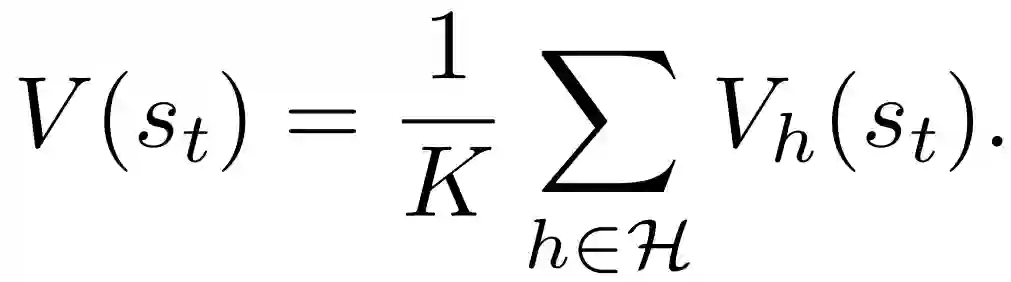
在上述自适应horizon的选择过程中,原始图像和重建图像被送入不同的世界模型组件,以预测未来的序列并进行价值估计。根据我们的假设,这些图像之间的世界模型的输出误差反映了它对不同输入的概括能力。因此,基于两者的估计状态值之间的误差被用来确定最终值估计的horizon。
| 项目 | SOTA!平台项目详情页 |
|---|---|
| DMVE | 前往SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/dmve |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。


