深度了解自监督,就看这篇解读(六)!微软亚研院提出新的自监督学习范式:PIC

极市导读
这篇文章我们介绍一种新的自监督学习范式:Parametric instance discrimination。这种方法最大的特点就是把每个输入当做为一类,也就是说每个 instance 的 label 都是不一样的。PIC 是一种单分支结构, 每次迭代只需要每个图像一个视图,无需解决信息泄漏的问题。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
深度了解自监督学习,就看这篇解读 !SimMIM:掩码图像建模的简单框架(一)
深度了解自监督学习,就看这篇解读 !大规模预训练视觉任务的BERT模型:iBOT(二)
深度了解自监督学习,就看这篇解读 !何恺明新作MAE:通向CV大模型(三)
深度了解自监督学习,就看这篇解读 !微软首创:运用在 image 领域的BERT(四)
深度了解自监督学习,就看这篇解读 !Hinton团队力作:SimCLR系列(五)
本文目录
1 PIC 自监督学习方法
1.1 PIC 原理分析
1.2 PIC 的 Sliding Window Data Scheduler
1.3 PIC 减少 GPU Memory 的训练策略
1.4 PIC 实验结果
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
Self-Supervised Learning 不仅是在 NLP 领域,在 CV, 语音领域也有很多经典的工作。它可以分成3类:Data Centric, Prediction (也叫 Generative) 和 Constractive。
其中,Constractive learning 的范式又叫做 non-parametric instance discrimination,例如 SimCLR 和 MoCo。non-parametric instance discrimination 一般采用双分支的结构。双分支的结构存在 information leakage 的问题,因此需要一些特殊的设计来解决这种问题,如:Momentum Encoder (MoCo),特殊 BN 层 (MoCo),limited negative pairs (SimCLR)。
本文介绍的这类方法使用参数化的单分支结构:Parametric instance discrimination (又叫 Parametric instance classification)。
1 PIC 自监督学习方法
论文名称:Parametric Instance Classification for Unsupervised Visual Feature Learning (NeurIPS 2020)
论文地址:
https://arxiv.org/pdf/2006.14618.pdf
1.1 PIC 原理分析
这篇文章我们介绍一种新的自监督学习范式:Parametric instance discrimination。这种方法最大的特点就是把每个输入当做为一类,也就是说每个 instance 的 label 都是不一样的。这么做的原因也很好理解:因为 Self-supervised Learning 不是有监督学习,它是没有标签的嘛,所以我们就人为地给每个数据打一个标签,把每个输入都当做为一类。比如我的数据集有 张图片,那就认为这个数据集有 个不同的类别。以这种做法为标志的 SSL 方法就称之为:Parametric instance discrimination。PIC 是一种单分支结构, 每次迭代只需要每个图像一个视图,无需解决信息泄漏的问题。在这个工作中,作者展示了在使用适当的策略如 cosine soft-max loss, stronger data augmentation 和 2-layer projection head 之后,PIC 也能达到 SimCLR 和 MoCo 的性能。作者希望简单有效且易拓展的 PIC 能够作为一种简单的 SSL 基线模型影响未来的 SSL 研究和发展。

如上图1所示就是 Parametric Instance Classification (PIC) 的原理框架。它由5大部分构成:
-
Data scheduler:给整个框架喂入数据。 -
Data augmentation module:为输入数据执行数据增强。 -
Backbone 网络 :特征提取骨干网络。 -
Projection head 网络 :小的投影头,把特征图映射为一个特征向量,以便后续分类。 -
Instance classification loss:SSL 的目标函数。
方法流程: 假设输入图片 送入骨干网络 和 Projection head 网络 ,得到输出的特征是 ,式中 为图片的数量。之后通过一个 FC 层 作为分类器完成分类任务,其中 为特征的维度, 为数据集的类别数,正好与图片的数量相等。最终的输出结果为 。我们把这个过程统称为 Parametric Instance Discrimination。
使用最常规的 SSL 策略会导致很差的性能,作者发现当使用了 cosine softmax loss + stronger data augmentation + 2-layer MLP projection head 这三项技术之后,SSL 的性能发生了显著的提升,如下图2所示是 ImageNet linear evaluation 实验结果。可以看出 cosine softmax 对性能的提升尤为重要。
其中,cosine softmax loss 它可以写成:
其中, 为 Batch size, 代表 cosine classifier 参数化的权值矩阵。 和 取余弦相似度 作为当前的第 个样本是第 类的概率, 是温度系数。
1.2 PIC 的 Sliding Window Data Scheduler
影响 PIC 框架性能的一个问题是:Infrequent visiting of each instance class。它指的是在一个 Epoch 里面,每个类 (因为 PIC 方法认为每个 instance 都是一个单独的类) 都只会被访问一次。不像是在有监督学习里面,比如 CIFAR-10 数据集包含10个类,则每个 Epoch 访问所有数据集下来,每个类会被访问很多次。那么 PIC 方法的特点是每个 instance 都是一个单独的类,所以每个 Epoch 里面,每个类都只会被访问一次,这种现象我们称之为 Infrequent visiting of each instance class。当我们使用大规模数据集时 (超过 1 million 张图片时),Infrequent visiting 的现象可能会影响优化,并可能导致次优的特征学习。作者提出了一个命题:
命题1: 假定每个 Epoch 访问的图片数量为 ,对于每个 Epoch 访问每张图片1次的任意 data scheduler,同一张图片的两次连续访问之间的距离的期望值为 。
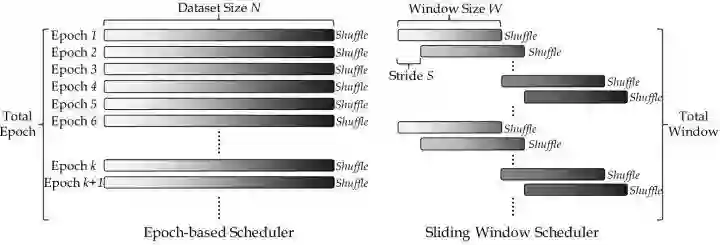
为此,作者提出了 Sliding Window Data Scheduler 的方法取代传统的 epoch-based data scheduler。新的 Data Scheduler 很好地解决了在无监督的实例分类中每个实例类被访问的频率太低的问题 (例如,每个 Epoch 只访问1次)。
Sliding Window Data Scheduler 希望 "大多数图片的两次连续访问之间的距离的期望值为 。常规 Data Scheduler 每个 Epoch 里面都遍历所有训练数据。与之相反,Sliding Window Data Scheduler 在每个 Epoch 里面只遍历一部分图片 (一个 Window size 大小 的图片),到了下一个 Epoch 时,再遍历下一个 Window size 大小 的图片。下一个 Window 从前一个 Window 偏移。连续 Window 之间有重叠,重叠的图片占大多数,因此它们在相对较短的时间内被访问了两次。
所以按照这种做法,对于大多数图片来讲,"相邻两次访问的间隔就由原来的 变成了 Window size 大小 "。如果我们设置 ,就能够实现大多数图片的两次连续访问之间的距离的期望值为 。同时这种方法还有一个参数:Sliding Stride :代表 Window 每次滑动的距离。
这个式子里面 是一个超参数,代表一个 Window 里面希望有 张图片 "相邻两次访问的间隔就由原来的 变成了 Window size 大小 "。所以滑动的距离就是 。
使用了 Sliding Window Data Scheduler 之后,不论训练数据集有多大,因为 Window size 大小 和 Window 超参数 是固定的,所以 "大多数图片的两次连续访问之间的距离的期望值都是 。
比如我们设置
,代表 Window 大小是131072,每次滑动距离为16384。对于大多数图片而言,两次连续访问之间的距离的期望值都是131072。
如下图所示是 Sliding Window Data Scheduler 的 PyTorch 伪代码,可以发现主要是构造了一个新的 PyTorch Sampler 的类。所以我们在附录1中简单介绍一下 PyTorch Sampler。可以看得出 Sliding Window Data Scheduler 本质上是附录1中的 Subset Random Sampler (子集随机采样)。
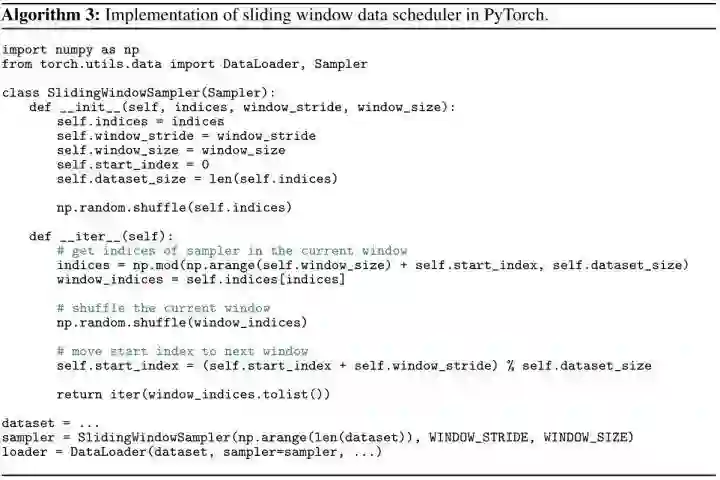
indices 是当前 GPU 的所有数据的索引。
window_indices 是当前 GPU 当前 Epoch 的真正使用的数据的索引。
1.3 PIC 减少 GPU Memory 的训练策略
影响 PIC 框架性能的另一个问题是训练时间和 GPU Memory Consumption 随数据集规模的增大而线性增加。原因有以下2方面:
-
前向/后向阶段的问题:前向传播/反向传播时,使用1式计算 softmax 时,分母中包含了所有负样本,因为数据集规模很大,造成这里计算复杂度高。 -
权重更新阶段的问题:使用的 SGD 优化器会存储当前的 momentum,导致训练时间和 GPU Memory Consumption 相对于数据大小线性增加,限制了对大规模数据的实用性。
为此,作者提出了两种方法来显著减少训练时间和 GPU Memory Consumption,使它们随着数据大小的增加而接近恒定。第一个是 Recent Negative Sampling,以解决前向/后向阶段的问题,第二个是分类权重更新校正 (Classification Weight Update Correction),以解决权重更新阶段的问题。
Recent Negative Sampling
前向传播/反向传播时,使用1式计算 softmax 时,分母中只包含了最近的 个负样本,因此,减少了损失函数1式的计算成本。作者发现 时在 ImageNet 上进行200个 Epochs 的预训练,获得了与使用所有实例 (约1280000) 相似的精度。
分类权重更新校正 (Classification Weight Update Correction)
使用带有 weight decay 的 SGD 优化器时,权值更新的方式是:
式中, 和 代表第 个 iteration 的分类器的第 个类别的权重 对应的梯度以及 momentum。 分别为 weight decay,momontum 系数和学习率。
对于那些 Recent Negative Sampling 没有采样到的 negative instance,梯度 。但是,由于存在 weight decay 和 momentum 机制, ,依然会带来训练时间和 GPU Memory Consumption 的增加。如果我们直接忽略掉没有采样到的 negative instance 的 weight decay 和 momentum,则 negative instance 和 positive instance 之间的不同优化统计量会导致精度显著下降。
那么如何解决这个问题呢?作者注意到那些没有采样到的 negative instance 的对应权值更新因为不涉及梯度 ,所以梯度 。也就是说这些权重参数的更新规律是可以预测的。因此有:
之后,把中间的两个转移矩阵合并成一个矩阵,就能够得到第 个 step 的更新规律写成了以下权重更新校正方式:
式中, 代表上次更新第 类的权重 时与这次更新第 类的权重 的距离。
使用了分类权重更新校正 (Classification Weight Update Correction) 之后,这个 Epoch 没有采样到的 negative instance 我们就不用存储对应权重以及它的梯度,momentum 值了,这大大节约了训练时间和 GPU Memory Consumption。而在下次采样时,新样本的权重会执行4式完成更新。
我们来对比一下 PIC 自监督学习和有监督学习的 PyTorch 伪代码,有2点需要注意:
-
W1 是 W 的一部分,代表采样得到的 instance 对应的权重 W1,采样完紧接着执行分类权重更新校正 (Classification Weight Update Correction) 过程。 -
权重 W1 和特征 feat 不是像有监督学习一样做矩阵相乘过程,而是去计算 cosine similarity 。

1.4 PIC 实验结果
作者在大规模数据集 ImageNet 进行 PIC 的自监督预训练,Epochs 数从200到1600不等。所有实验均使用 ResNet-50 作为 Backbone 网络 ,Batch size=512。cosine soft-max loss 的超参数 。默认设置 ,代表 Window 大小是131072,每次滑动距离为16384。对于大多数图片而言,两次连续访问之间的距离的期望值都是131072。
自监督学习的评价指标有2个:
Linear Classification Protocol: 按照 PIC 的方式进行完 Pre-train 之后,Encoder 部分和 Projection head 部分的权重也就确定了。那么这个时候我们去掉 Projection head 的部分,在 Encoder 输出的 之后再添加一个线性分类器 (Linear Classifier),它其实就是一个 FC 层。那么我们使用全部的 ImageNet 去训练这个 Linear Classifier,具体方法是把预训练部分,即 之前的权重 frozen 住,只训练线性分类器的参数,那么 Test Accuracy 就作为此评价指标的最终精度。
Fine-tune Pretrained Networks: 按照上面的方式进行完 Pre-train 之后,Encoder 部分和 Projection head部分的权重也就确定了。那么这个时候我们去掉 Projection head 的部分,在 Encoder 输出的 之后再添加一个线性分类器 (Linear Classifier),它其实就是一个 FC 层。那么我们在下有任务上使用全部数据集 Fine-tune 整个网络,下游任务上的表现就作为此评价指标的最终精度。
Linear Classification Protocol:
对比实验1:验证不同 component 的作用
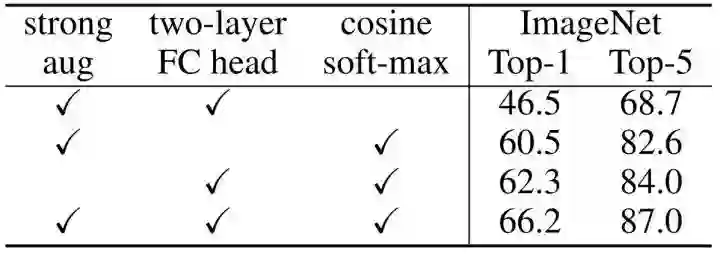
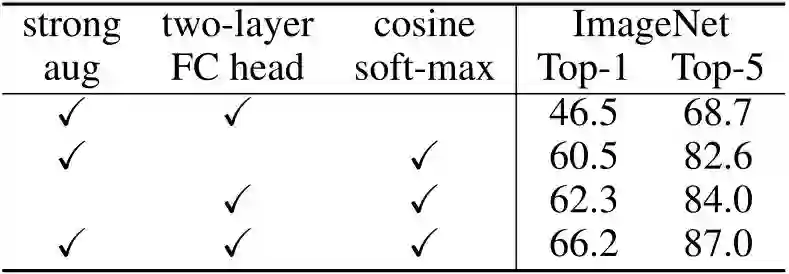
对比实验采用 Linear Classification Protocol,训练200 Epochs。如下图6所示代表不同 component 的作用对比,包括:更强的数据增强策略,2层的 Projection head 和 Cosine softmax 损失函数。这三种技术都非常有益,改进了 PIC 的性能,在 ImageNet1K Linear Classification Protocol 中实现了具有竞争力的66.2%的Top-1 精度。请注意,Cosine softmax 损失函数尤其重要,使得 Top-1 精度提高了约20%。
对比实验2:Recent Negative Sampling 和分类权重更新校正对比实验
如下图7所示代表Recent Negative Sampling 和分类权重更新校正对比实验,我们发现使用 个 Negative Instance 能够获得与不采样 (使用全部的 instance) 时相同的精度。分类权重更新校正方法也很重要,因为没有它的方法会导致显著的性能下降,尤其是在采样实例数量很小时。

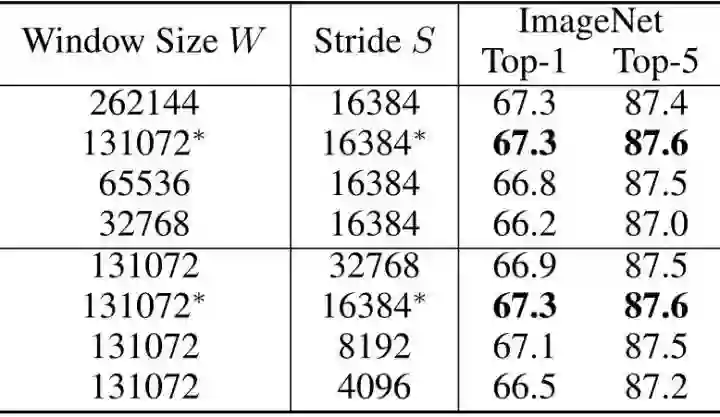
对比实验3:Sliding Window Data Scheduler 对比实验
如下图8所示代表Sliding Window Data Scheduler 对比实验,可以发现当我们使用 时性能最佳。它在 ImageNet-1K 数据集上实现了67.3%的 Top-1 准确率,比Epoch-based data scheduler 高出1.1%。
与其他方法对比
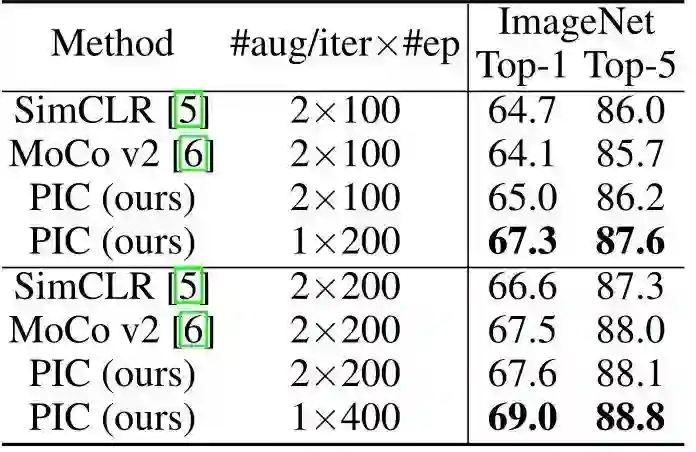
作者首先将 PIC 框架与先前的无监督预训练方法 (即 MoCo 和 SimCLR) 进行比较,在相似的训练长度下,不同的方法利用相同数量的 Augmentation view,如下图9所示。当使用200 Epochs augmentation views 时,PIC 框架在 Top-1 精度上分别优于 SimCLR 和 MoCo v2 2.6%和3.2%。使用400 Epochs augmentation views 精度增益分别为2.4%和1.5%。
然后,作者将 PIC 与以前的最先进的方法进行比较,使用了更长的训练长度,即1600个 Epochs (相当于两个分支方法的800 Epochs 的训练)。PIC 在 ImageNet-1K 数据集上实现了70.8%的 Top-1 精度,明显优于 SimCLR (+1.6%),与 MoCo v2 (0.3%) 不相上下。
Fine-tune Pretrained Networks:
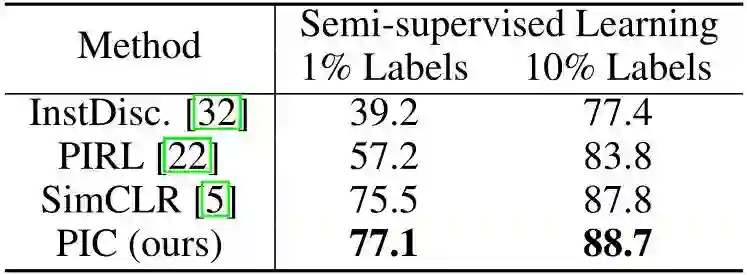
下面是 Fine-tune Pretrained Networks 的评估方式,图10是设置下游任务为 ImageNet 图像分类的实验结果。PIC 在半监督 ImageNet-1K 分类任务上以1%和10%的标签实现了最先进的准确性,分别比第二好的方法高出1.6%和0.9%。
总结
PIC 是一种新的自监督学习范式:Parametric instance discrimination。这种方法最大的特点就是把每个输入当做为一类,也就是说每个 instance 的 label 都是不一样的。这么做的原因也很、好理解:因为 Self-supervised Learning 不是有监督学习,它是没有标签的嘛,所以我们就人为地给每个数据打一个标签,把每个输入都当做为一类。比如我的数据集有 张图片,那就认为这个数据集有 个不同的类别。以这种做法为标志的 SSL 方法就称之为:Parametric instance discrimination。PIC 是一种单分支结构, 每次迭代只需要每个图像一个视图,无需解决信息泄漏的问题。在这个工作中,作者展示了在使用适当的策略如 cosine soft-max loss, stronger data augmentation 和 2-layer projection head 之后,PIC 也能达到 SimCLR 和 MoCo 的性能。作者希望简单有效且易拓展的 PIC 能够作为一种简单的 SSL 基线模型影响未来的 SSL 研究和发展。
附录1:PyTorch Sampler 简介
在训练神经网络时,如果数据量太大,无法一次性将数据放入到网络中进行训练,所以需要进行分批处理数据读取。这一个问题涉及到如何从数据集中进行读取数据的问题,PyTorch 框架提供了 Sampler 基类与多个子类实现不同方式的数据采样。子类包括:
-
Sequential Sampler (顺序采样)
-
Random Sampler (随机采样)
-
Subset Random Sampler (子集随机采样)
-
WeightedRandomSampler (加权随机采样)
-
BatchSampler (批采样)
1 基类 Sampler
class Sampler(object):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an :meth:`__iter__` method, providing a
way to iterate over indices of dataset elements, and a :meth:`__len__` method
that returns the length of the returned iterators.
.. note:: The :meth:`__len__` method isn't strictly required by
:class:`~torch.utils.data.DataLoader`, but is expected in any
calculation involving the length of a :class:`~torch.utils.data.DataLoader`.
"""
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
对于所有的采样器来讲,都需要集成 Sampler 类,必须实现的方法为 __iter__(),也就是定义迭代器行为,返回可迭代对象。除此之外,Sampler 类没有定义任何其他的方法。
2 顺序采样 Sequential Sampler
class SequentialSampler(Sampler):
r"""Samples elements sequentially, always in the same order.
Arguments:
data_source (Dataset): dataset to sample from
"""
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
顺序采样类并没有定义过多的方法,其中初始化方法仅仅需要一个 Dataset 类作为参数。
对于 __len__() 只负责返回数据源包含的数据个数, __iter__() 方法返回可迭代对象,这个可迭代对象是一个由 range 方法产生的顺序数值序列,也就是说迭代是按照顺序进行的。
每个 Epoch 包含很多 iteration,每个 Epoch 执行一次 __iter__() 函数,每个 iteration 执行一次可迭代对象的 next() 函数。
# 定义数据和对应的采样器
data = list([1, 2, 3, 4, 5])
seq_sampler = sampler.SequentialSampler(data_source=data)
# 迭代获取采样器生成的索引
for index in seq_sampler:
print("index: {}, data: {}".format(str(index), str(data[index])))
得到下面的输出,说明Sequential Sampler产生的索引是顺序索引:
index: 0, data: 1
index: 1, data: 2
index: 2, data: 3
index: 3, data: 4
index: 4, data: 5
3 随机采样 Random Sampler
class RandomSampler(Sampler):
r"""Samples elements randomly. If without replacement, then sample from a shuffled dataset.
If with replacement, then user can specify :attr:`num_samples` to draw.
Arguments:
data_source (Dataset): dataset to sample from
replacement (bool): samples are drawn with replacement if ``True``, default=``False``
num_samples (int): number of samples to draw, default=`len(dataset)`. This argument
is supposed to be specified only when `replacement` is ``True``.
generator (Generator): Generator used in sampling.
"""
def __init__(self, data_source, replacement=False, num_samples=None, generator=None):
self.data_source = data_source
# 这个参数控制的应该是否重复采样
self.replacement = replacement
self._num_samples = num_samples
self.generator = generator
# 类型检查
if not isinstance(self.replacement, bool):
raise TypeError("replacement should be a boolean value, but got "
"replacement={}".format(self.replacement))
if self._num_samples is not None and not replacement:
raise ValueError("With replacement=False, num_samples should not be specified, "
"since a random permute will be performed.")
if not isinstance(self.num_samples, int) or self.num_samples <= 0:
raise ValueError("num_samples should be a positive integer "
"value, but got num_samples={}".format(self.num_samples))
@property
def num_samples(self):
# dataset size might change at runtime
# 初始化时不传入num_samples的时候使用数据源的长度
if self._num_samples is None:
return len(self.data_source)
return self._num_samples
def __iter__(self):
n = len(self.data_source)
if self.replacement:
rand_tensor = torch.randint(high=n, size=(self.num_samples,), dtype=torch.int64, generator=self.generator)
return iter(rand_tensor.tolist())
return iter(torch.randperm(n, generator=self.generator).tolist())
# 返回数据集的长度
def __len__(self):
return self.num_samples
最重要的是 __iter__() 方法,定义了核心的索引生成行为。其中 if 判断处返回了2种随机值,根据是否在初始化参数中给出 replacement 决定是否重复采样。区别核心在于 randint() 函数生成的随机数序列是包含重复数值的,而 randperm() 函数生成的随机数序列是不包含重复数值的。
下面分别测试 replacement 为 False 和 True 两种情况的示例:
ran_sampler = sampler.RandomSampler(data_source=data)
for index in ran_sampler:
print("index: {}, data: {}".format(str(index), str(data[index])))
index: 3, data: 4
index: 4, data: 5
index: 2, data: 3
index: 1, data: 2
index: 0, data: 1
ran_sampler = sampler.RandomSampler(data_source=data, replacement=True)
for index in ran_sampler:
print("index: {}, data: {}".format(str(index), str(data[index])))
index: 1, data: 2
index: 2, data: 3
index: 4, data: 5
index: 3, data: 4
index: 1, data: 2
4 子集随机采样 Subset Random Sampler
class SubsetRandomSampler(Sampler):
r"""Samples elements randomly from a given list of indices, without replacement.
Arguments:
indices (sequence): a sequence of indices
generator (Generator): Generator used in sampling.
"""
def __init__(self, indices, generator=None):
# 数据集的切片,比如训练集和测试集
self.indices = indices
self.generator = generator
def __iter__(self):
# 以元组形式返回不重复打乱后的“数据”
return (self.indices[i] for i in torch.randperm(len(self.indices), generator=self.generator))
def __len__(self):
return len(self.indices)
上述代码中 __len__() 的作用是返回随机数序列作为 indice 的索引。需要注意的是采样仍然是不重复的,也是通过 randperm 函数实现的。下面这个例子把用于训练集,验证集和测试集的划分:
print('***********')
sub_sampler_train = sampler.SubsetRandomSampler(indices=data[0:2])
for index in sub_sampler_train:
print("index: {}".format(str(index)))
print('------------')
sub_sampler_val = sampler.SubsetRandomSampler(indices=data[2:])
for index in sub_sampler_val:
print("index: {}".format(str(index)))
# train:
index: 2
index: 1
# val:
index: 3
index: 4
index: 5
5 加权随机采样 WeightedRandomSampler
class WeightedRandomSampler(Sampler):
r"""Samples elements from ``[0,..,len(weights)-1]`` with given probabilities (weights).
Args:
weights (sequence) : a sequence of weights, not necessary summing up to one
num_samples (int): number of samples to draw
replacement (bool): if ``True``, samples are drawn with replacement.
If not, they are drawn without replacement, which means that when a
sample index is drawn for a row, it cannot be drawn again for that row.
generator (Generator): Generator used in sampling.
Example:
>>> list(WeightedRandomSampler([0.1, 0.9, 0.4, 0.7, 3.0, 0.6], 5, replacement=True))
[4, 4, 1, 4, 5]
>>> list(WeightedRandomSampler([0.9, 0.4, 0.05, 0.2, 0.3, 0.1], 5, replacement=False))
[0, 1, 4, 3, 2]
"""
def __init__(self, weights, num_samples, replacement=True, generator=None):
# 类型检查
if not isinstance(num_samples, _int_classes) or isinstance(num_samples, bool) or \
num_samples <= 0:
raise ValueError("num_samples should be a positive integer "
"value, but got num_samples={}".format(num_samples))
if not isinstance(replacement, bool):
raise ValueError("replacement should be a boolean value, but got "
"replacement={}".format(replacement))
# weights用于确定生成索引的权重
self.weights = torch.as_tensor(weights, dtype=torch.double)
self.num_samples = num_samples
# 用于控制是否对数据进行有放回采样
self.replacement = replacement
self.generator = generator
def __iter__(self):
# 按照加权返回随机索引值
rand_tensor = torch.multinomial(self.weights, self.num_samples, self.replacement, generator=self.generator)
return iter(rand_tensor.tolist())
def __len__(self):
return self.num_samples
replacement 参数依旧是控制采样有没有放回的。num_samples 用于控制生成的个数,weights 参数对应的是样本的权重而不是类别的权重。最重要的是 __iter__() 方法,返回随机数序列,只是这个随机数序列是按照 weights 指定的权重确定的。
# 加权随机采样
data=[1,2,5,78,6,56]
# 位置为[0]圈中为0.1,位置为[1] 权重为0.2
weights=[0.1,0.2,0.3,0.4,0.8,0.3,5]
rsampler=sampler.WeightedRandomSampler(weights=weights,num_samples=10,replacement=True)
for index in rsampler:
print("index: {}".format(str(index)))
index: 5
index: 4
index: 6
index: 6
index: 6
从输出可以看出,位置[6]由于权重较大,被采样的次数较多,位置[0]由于权重为0.1所以没有被采样到,其余位置权重低所以都仅仅被采样一次。
6 批采样 BatchSampler
class BatchSampler(Sampler):
r"""Wraps another sampler to yield a mini-batch of indices.
Args:
sampler (Sampler or Iterable): Base sampler. Can be any iterable object
with ``__len__`` implemented.
batch_size (int): Size of mini-batch.
drop_last (bool): If ``True``, the sampler will drop the last batch if
its size would be less than ``batch_size``
Example:
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
"""
def __init__(self, sampler, batch_size, drop_last):
# Since collections.abc.Iterable does not check for `__getitem__`, which
# is one way for an object to be an iterable, we don't do an `isinstance`
# check here.
# 类型检查
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \
batch_size <= 0:
raise ValueError("batch_size should be a positive integer value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
# 定义采用何种采样器sampler
self.sampler = sampler
self.batch_size = batch_size
# 是否在采样个数小于batch_size时剔除本次采样
self.drop_last = drop_last
def __iter__(self):
batch = []
for idx in self.sampler:
batch.append(idx)
# 如果采样个数和batch_size相等则本次采样完成
if len(batch) == self.batch_size:
yield batch
batch = []
# for结束后在不需要剔除不足batch_size的采样个数时返回当前batch
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
# 在不进行剔除时,数据的长度就是采样器索引的长度
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
在定义好各种采样器以后,需要进行批采样。当 drop_last 为 True 时,如果采样的到的数据小于 batch size,则抛弃这个 batch 的数据。下面的例子中 BatchSampler 使用的采样器为顺序采样器。
seq_sampler = sampler.SequentialSampler(data_source=data)
batch_sampler = sampler.BatchSampler(seq_sampler, 4, False)
print(list(batch_sampler))
[[0, 1, 2, 3], [4, 5]]
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选




