![]()
作者|魔王、张倩
来源|机器之心
上海交大研究人员创建新型开放医疗图像数据集 MedMNIST,并设计「MedMNIST 分类十项全能」,旨在促进 AutoML 算法在医疗图像分析领域的研究。
在 AI 技术的发展中,数据集发挥了重要的作用。然而,医疗数据集的创建面临着很多难题,如数据获取、数据标注等。
近期,上海交通大学的研究人员创建了医疗图像数据集 MedMNIST,共包含 10 个预处理开放医疗图像数据集(其数据来自多个不同的数据源,并经过预处理)。
https://medmnist.github.io/
https://arxiv.org/pdf/2010.14925v1.pdf
https://github.com/MedMNIST/MedMNIST
https://www.dropbox.com/sh/upxrsyb5v8jxbso/AADOV0_6pC9Tb3cIACro1uUPa?dl=0
和 MNIST 数据集一样,MedMNIST 数据集在轻量级 28 × 28 图像上执行分类任务,所含任务覆盖主要的医疗图像模态和多样化的数据规模。根据研究人员的设计,MedMNIST 数据集具备以下特性:
教育性:该数据集中的多模态数据来自多个具备知识共享许可证的开放医疗图像数据集,可以用作教育目的。
标准化:研究人员对数据进行预处理,将其转化为相同的格式,因此用户无需具备背景知识即可使用。
多样性:多模态数据集涵盖多种数据规模(从 100 到 100,000)和任务(二分类 / 多分类、有序回归和多标签)。
轻量级:图像大小为 28 × 28,便于快速设计原型和试验多模态机器学习与 AutoML 算法。
受 Medical Segmentation Decathlon(医学分割十项全能)的启发,该研究也设计了 MedMNIST Classification Decathlon(MedMNIST 分类十项全能),作为 AutoML 在医疗图像分类领域的基准。
它在全部 10 个数据集上评估 AutoML 算法的性能,且不对算法进行手动微调。研究人员对比了多个基线方法的性能,包括早停 ResNet [6]、开源 AutoML 工具(auto-sklearn [7] 和 AutoKeras [8]),以及商业化 AutoML 工具(Google AutoML Vision)。研究人员希望 MedMNIST Classification Decathlon 可以促进 AutoML 在医疗图像分析领域的研究。
![]()
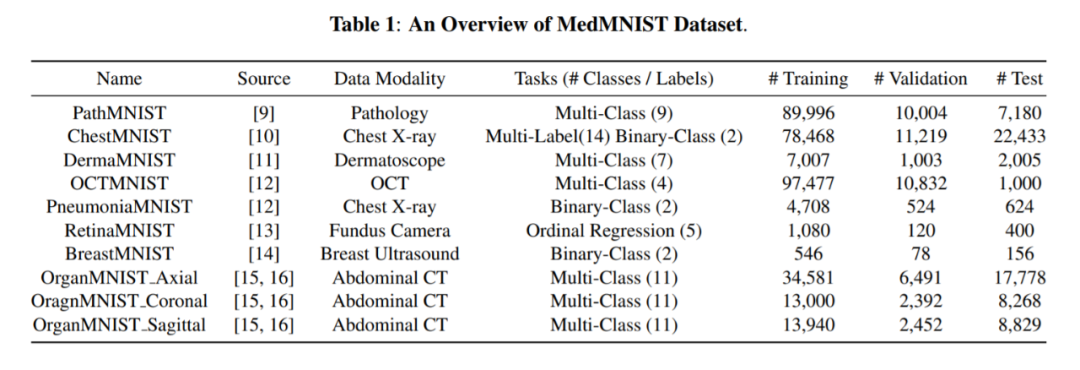
MedMNIST 数据集包含 10 个预处理数据集,覆盖主要的数据模态(如 X 光片、OCT、超声、CT)、多样化的分类任务(二分类 / 多分类、有序回归和多标签)和数据规模。如表 1 所示,数据集设计的多样性导致了任务难度的多样化,而这正是 AutoML 基准所需要的。研究人员对每个数据集进行预处理,将其分割为训练 - 验证 - 测试子集。
![]()
表 1:MedMNIST 数据集概览,涵盖数据集的名称、来源、数据模态、任务和数据集分割情况。
这些数据集的数据模态涵盖 X 光片、OCT、超声、CT、病理切片、皮肤镜检查等形式,涉及结直肠癌、视网膜疾病、乳腺疾病、肝肿瘤等多个医学领域。
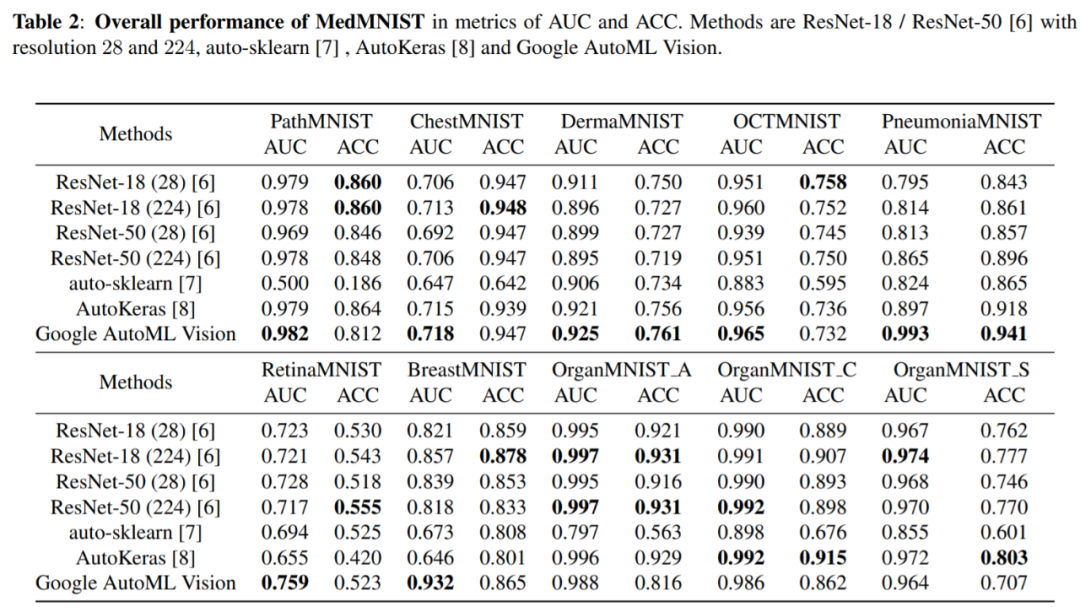
如前所述,研究人员受医学分割十项全能的启发,设计了「MedMNIST 分类十项全能」,旨在为医疗图像分析创建轻量级的 AutoML 基准。它在全部 10 个数据集上评估 AutoML 算法的性能,且不对算法进行手动微调。研究人员对比了多个基线方法的性能,参见下表 2:
![]()
从表 2 中可以看出,Google AutoML Vision 整体性能较好,但并不总是最优,有时甚至输给 ResNet-18 和 ResNet-50。auto-sklearn 在大部分数据集上表现不好,这表明典型的统计机器学习算法在该医疗图像数据集上性能较差。AutoKeras 在大规模数据集上性能较好,在小规模数据集上表现相对较差。没有哪种算法可以在这十个数据集上取得很好的泛化性能,这有助于探索 AutoML 算法在不同数据模态、任务和规模的数据集上的泛化效果。
接下来,我们来看不同方法在训练集、验证集和测试集上的性能情况。如下图 2 所示,算法在规模较小的数据集上容易过拟合。
![]()
Google AutoML Vision 能够较好地控制过拟合问题,而 auto-sklearn 出现了严重的过拟合。据此可以推断,对于学习算法而言,合适的 reductive bias 非常重要。我们还可以在 MedMNIST 数据集上探索不同的正则化技术,如数据增强、模型集成、优化算法等。
除了医疗领域之外,其他领域的数据集有时也很难获取,这就需要我们掌握一些常见的数据集搜集方法和常用资源。最近,Medium 上的一位博主介绍了多个常用的数据集获取来源:
这是一个 GitHub 存储库,包含多个不同类别的数据集。
https://github.com/awesomedata/awesome-public-datasets
这是一个以电子表格形式展示的数据集资源,从 2015 年开始定期更新,最新一期是 2020 年 10 月 28 日的资源,因此有些资源非常新。
链接:https://docs.google.com/spreadsheets/d/1wZhPLMCHKJvwOkP4juclhjFgqIY8fQFMemwKL2c64vk/edit#gid=0
Kaggle Datasets 提供了关于很多数据集的预览和总结性信息,非常适合用来检索特定主题的数据集。
https://www.kaggle.com/datasets
和 Kaggle 一样,Data.world 提供了一系列用户贡献的数据集,还为公司存储和组织自己的数据提供了平台。
数据集搜索
是谷歌 2018 年推出的一个新搜索功能。如果你正在寻找特定主题或特定来源的数据,这个工具值得一试。
https://datasetsearch.research.google.com/
OpenDal 也是一个数据集搜索工具,你可以利用多种方式进行搜索,如根据创建时间或框定地图上的某一区域。
https://opendatalibrary.com/
Pandas Data Reader 可以帮助你拉取在线资源中的数据,然后将其用到 Python pandas DataFrame 中。这里大部分是金融数据。
https://pandas-datareader.readthedocs.io/en/latest/remote_data.html
利用 Python 从 API 获取数据也是数据科学家常用的一种方法,具体操作步骤可以参见以下教程。
https://towardsdatascience.com/how-to-get-data-from-apis-with-python-dfb83fdc5b5b
参考链接:https://towardsdatascience.com/the-top-10-best-places-to-find-datasets-8d3b4e31c442
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()