【Kaggle车辆边界识别第一名解决方案】使用预训练权重轻松改进U-Net
选自arXiv
来源:机器之心
本文作者之一 Vladimir Iglovikov 曾取得 Kaggle Carvana Image Masking Challenge 第一名,本文介绍了他使用的方法:使用预训练权重改进 U-Net,提升图像分割的效果。
代码地址(包含预训练权重):https://github.com/ternaus/TernausNet
随着处理密集计算的计算机硬件的发展和平民化,研究者能够处理拥有数百万参数的模型。卷积神经网络在图像分类、目标识别、场景理解等领域都取得了极大的成功。对几乎所有的计算机视觉问题,基于 CNN 的方法都优于其他技术,在很多情况下甚至超越了人类专家。目前,几乎所有的计算机视觉应用尝试使用深度学习技术来改进传统方法。它们影响到我们的日常生活,且这些技术的潜在应用场景似乎也很惊人。
可靠的图像分割是计算机视觉领域的重要任务之一。该问题对医疗图像领域极为重要,可以提高诊断能力,在场景理解领域中有助于创造安全的自动驾驶汽车。密集图像分割本质上是把图像分为有意义的区域,可看作是像素级别的分类任务。处理此类问题最直接(也缓慢)的方法是手动分割图像。然而,这种方法极为耗时,而且人类数据管理员不可避免地会出错、存在不一致问题。自动化该过程能提供尽可能快的、系统性的图像分割。该过程需要达到一定的准确率,以在生产环境中使用。
在过去几年中,研究者提出了不同的方法来解决该问题:创造一种 CNN,为一整张输入图像在单个前向传递中生成分割图。其中,最成功的最优方法基于全卷积网络(FCN)[2]。其核心思想是将 CNN 中的全连接层替换成卷积层,成为强大的特征提取器,直接输出空间特征图,而不是全连接层输出的分类分数。然后,上采样这些图,生成密集的逐像素输出。该方法以端到端的方式训练 CNN,分割任意大小的输入图像。此外,在 PASCAL VOC 等标准数据集上,该方法极大地改进了分割的准确率。
后来,这一方法进一步被改进为 U-Net 神经网络 [4],U-Net 架构使用跳过连接(skip connection)将低层特征图与高层特征图结合起来,带来精确的像素级定位。在上采样部分,大量的特征通道向更高的分辨率层传播上下文信息。在卫星图像分析、医疗图像分析等二值图像分割竞赛中,这种类型的网络架构已经证明了自己。
在此论文中,作者展示了如何使用预训练权重轻松改进 U-Net 的性能。作者还将它应用到航空图像标注数据集 [8] 中,该数据集包含多个城市的高清航空图像。这些图像的每个像素都被标注为「建筑」或「非建筑」类别。该架构另一个成功应用案例与初始化方案是 Kaggle Carvana 图像分割竞赛 [9],本论文作者之一使用它作为解决方案的一部分,获得了第一名。
II. 网络架构
通常,U-Net 架构包含一个收缩路径来捕捉上下文信息,以及一个对称的扩张路径以进行精准的定位(见图 1)。收缩路径遵循典型的卷积网络架构,即交替卷积和池化运算,并逐步下采样特征图,同时逐层增加特征图的数量。扩张路径的每个阶段由一个特征图上采样和紧随的卷积构成。
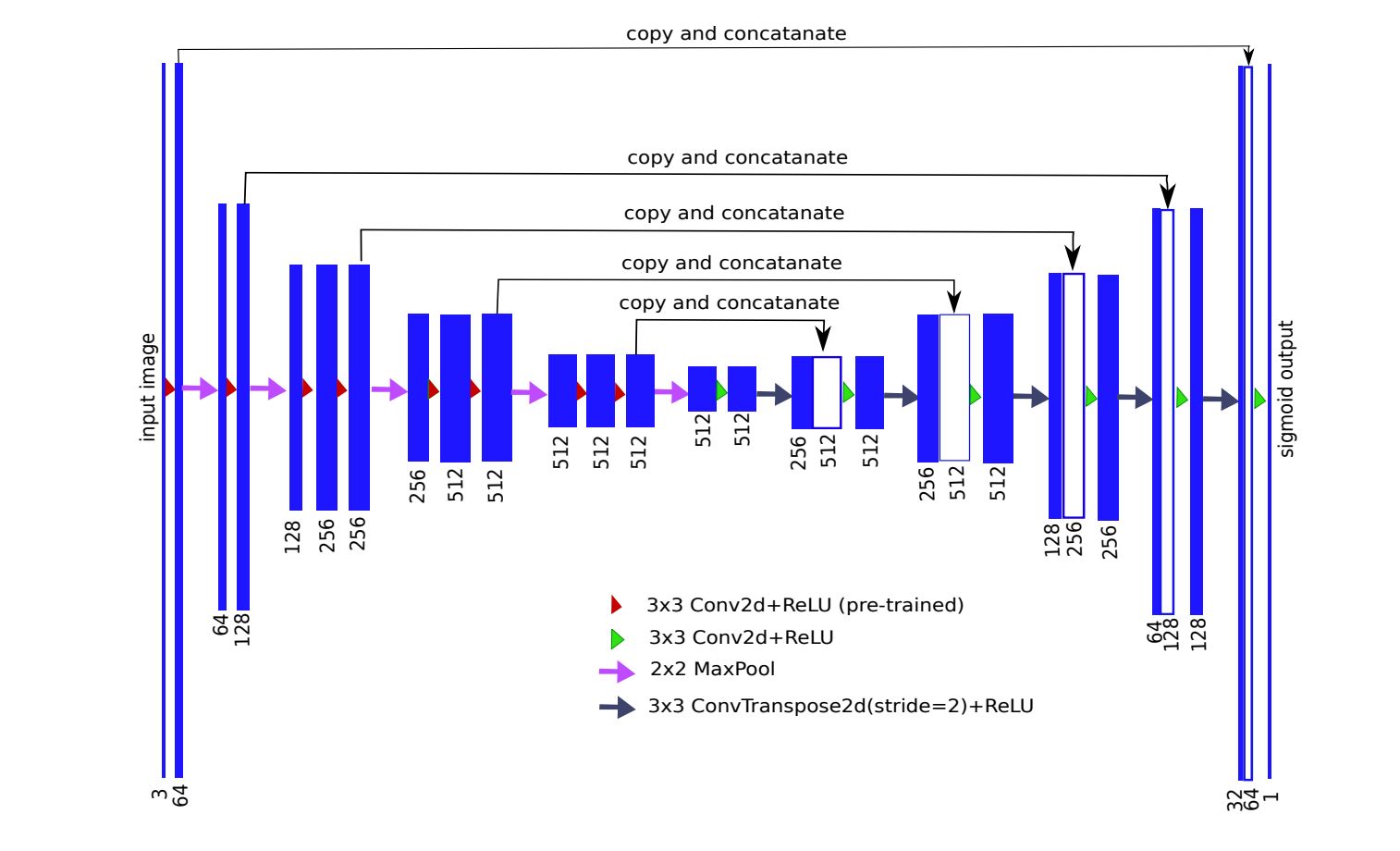
图 1:编码器-解码器神经网络架构,亦称为 U-Net,使用无全连接层的 VGG11 作为编码器。每个蓝色的矩形块代表一个经过一系列变换的多通道特征图。矩形的长度代表相对的图尺寸(像素级),其宽度和通道数量成正比。左边编码器部分的通道数逐渐增加,而右边解码器部分的通道数逐渐减少。顶部的箭头表示每个编码层的信息迁移,并传输至对应的解码层。
因此,扩张分支可以提高输出的分辨率。为了进行定位,扩张路径通过跳过连接将上采样特征和来自收缩路径的高分辨率特征结合起来 [4]。模型的输出是一个逐像素掩码,展示了每个像素的类别。该架构被证明对有限数据的分割问题很有用,示例参见 [5]。
U-Net 可以从相对较小的训练集中学习。多数情况下,图像分割的数据集由至多几千张图像构成,因为手动标记掩码是非常繁重的工作。通常 U-Net 以随机初始化权重开始训练。众所周知,要使网络训练避免过拟合,数据集应该足够大,包含数百万张图像。在 ImageNet [10] 数据集上训练的网络被广泛地用于其它任务的网络初始化。用这种方法,可以让网络非预训练的几层(有时仅仅是最后一层)利用数据集的特征进行学习。
我们使用 VGG 族 [11] 中非常简单的 CNN 作为 U-Net 网络的编码器,它由 11 个顺序层构成,称为 VGG11,参见图 2。VGG11 包含 7 个卷积层,每个紧随着一个 ReLU 激活函数和 5 个最大池化运算,每个运算之后将特征图减半。所有卷积层都有 3x3 的卷积核,通道数如图 2 所示。第一个卷积层有 64 个通道,然后网络加深,每个卷积层和最大池化运算之后通道数会加倍,直到通道数变为 512。在之后的卷积层中,通道数不变。
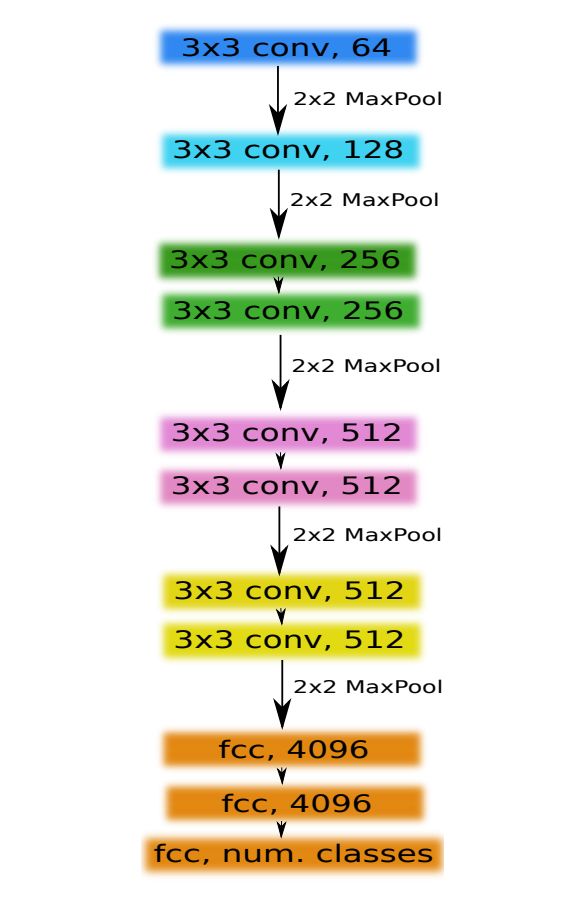
图 2:VGG11 网络架构。在这张图中,每个卷积层之后是 ReLU 激活函数。每个框中的数字表示对应特征图的通道数量。
为了构建解码器,我们移除所有的全连接层,并用包含 512 个通道的单一卷积层来替换它们,该层是网络的瓶颈中间部分,分离编码器与解码器。为了构建解码器,我们使用两倍于特征图大小的转置卷积层,同时把通道数量减少一半。转置卷积的输出接着被连接到解码器对应部分的输出。由此得到的特征图通过卷积运算来处理,以保持通道数量与对称编码器项相同。上采样步骤被重复 5 次以配对 5 个最大池化层,如图 1 所示。严格来说全连接层可以采用任何大小的输入,但是由于我们有 5 个最大池化层,每个层下采样图像两次,只有可被 32(2^5)整除的图像可以用作当前网络实现的输入。
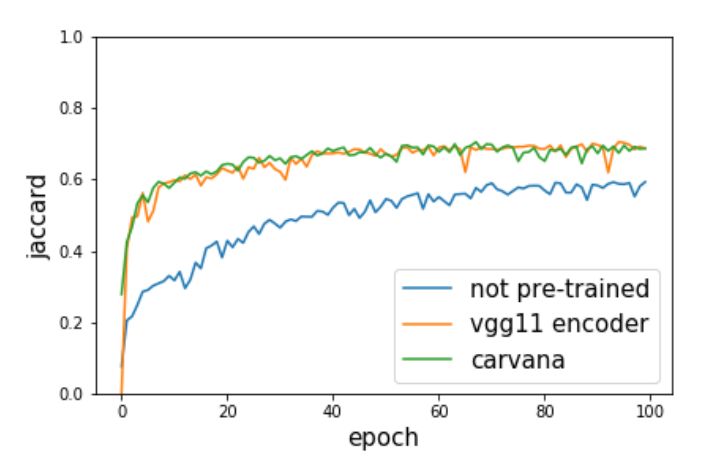
图 3:三种以不同权重初始化的 U-Net 模型的 Jaccard 指标随训练 epoch 的变化。蓝线表示随机初始化权重的模型,橙线表示编码器以在 ImageNet 上预训练的 VGG11 网络权重初始化的模型,绿线表示整个网络在 Carvana 数据集上预训练的模型。

图 4:绿色像素的二进制掩膜表示分类族群(建筑)。图 A 展示初始图像和叠加的真实掩膜。图 B 到图 D 表示使用三种权重初始化方案并训练了 100 个 epoch 后得到的预测结果。图 B 表示随机初始化权重的模型,图 C 中的模型使用随机初始化权重,编码器以在 ImageNet 上预训练的 VGG11 网络权重进行初始化,图 D 中的模型使用在 Carvana 数据集上预训练的权重。
在本论文中,通过使用微调(fine-tuning)技术初始化网络编码器的权重,我们展示了如何提升 U-Net 的性能。这种神经网络被广泛用于图像分割任务,并在许多二值图像分割、竞赛中取得了当前最优结果。微调已广泛用于图像分类任务,但是就我们所知还未用于 U-Net 类型的架构。对于图像分割问题,微调应该是更自然的选择,因为收集大量数据集(尤其是医疗图像)并进行很好地标注是很困难的。此外,预训练网络可以大幅减少训练时间,同时有助于防止过拟合。考虑到存在更多先进的预训练编码器比如 VGG16 [11] 或任何预训练的 ResNet 网络,我们的方法还可进一步提升。有了这些改进的编码器,解码器可以像我们使用的一样简单。
论文:TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation

论文链接:https://arxiv.org/abs/1801.05746
摘要:像素级的图像分割是计算机视觉中的艰巨任务。由编码器和解码器构成的经典 U-Net 架构经常用于分割医学影像、卫星影像等。通常,神经网络使用在大型数据集(例如 ImageNet)上预训练的网络权重进行初始化,相比用小型数据集从零开始训练的网络能获得更好的性能。在某些特定的应用中,特别是医学和交通安全,模型的准确率至关重要。在本文中,我们展示了 U-Net 类型的架构如何利用预训练的编码器提升性能。我们的代码和相关的预训练权重已开源。我们比较了三种权重初始化方案:LeCun uniform、取自 VGG11 权重的编码器和在 Carvana 数据集上训练的完整网络。该网络架构是 Kaggle 竞赛(Carvana Image Masking Challenge)中获胜解决方案(在 735 名参赛者中排名第一)的一部分。

☞ 【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞ 【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞ 【CFP】Virtual Images for Visual Artificial Intelligence
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【观点】「我是可微分编程的粉丝」,Gary Marcus再回应深度学习批判言论
☞ 【学界】谷歌大脑提出Adversarial Spheres:从简单流形探讨对抗性样本的来源
☞ 【解析】当这位70岁的Hinton老人还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力(附Capsule)




