比OCR更强大的PPT图片一键转文档重建技术
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
目前越来越多的资源信息是以图像形式存储,然而很多用户在获取图像后需要对图片进行编辑或者电子文档形式进行存储。最主流的做法是直接进行 OCR 提取,但这种方法无法满足用户对排版的需求。当前主流办公产品比如 office,wps,腾讯文档等会采用一些技术对图片进行排版恢复还原为 doc 形式的文档,通常针对以文字偏多,格式简单的图像效果比较好,但如果内容丰富,图片并茂的 ppt 内容图像在转为 doc 文档时由于图像比例,文档排版插入限制以及文档适应背景单一而丰富背景还原度差等问题会导致很多 ppt 形式的图片无法很好还原为电子文档。
QQ 研发团队团队在前期已经推出了基于深度学习的文档重建,表格重建的技术文章。产品也已经在腾迅文档,PCQQ,手机 QQ 上线,近期我们又增加了 PPT 重建功能。小程序在搭建中,其中添加里更多子功能,比如 OCR,文档自动选框,去摩尔纹,图片扭曲恢复等。
下面主要给大家介绍 PPT 的重建技术,产品流程如图 1 所示,效果图如图 2 所示:
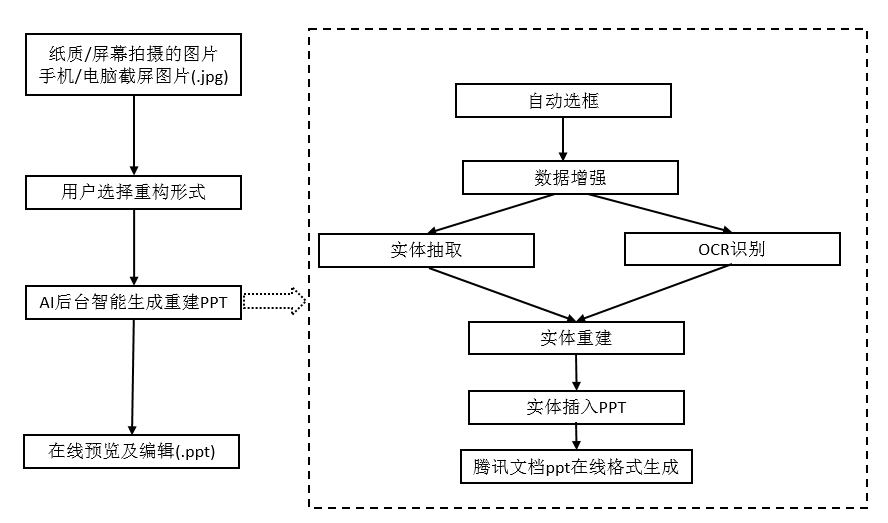

一、图片转 ppt 框架
项目的技术流程主要分为三大模块:预处理:包括文档检测和矫正,图片去摩尔纹,文档扭曲恢复,文档旋转,语义分割等,主要深度学习,模型部署在 GPU。排版分析:对各实体的恢复,以及排版处理,逻辑流程部署在 CPU。后处理: 生成导出 PPT 文件
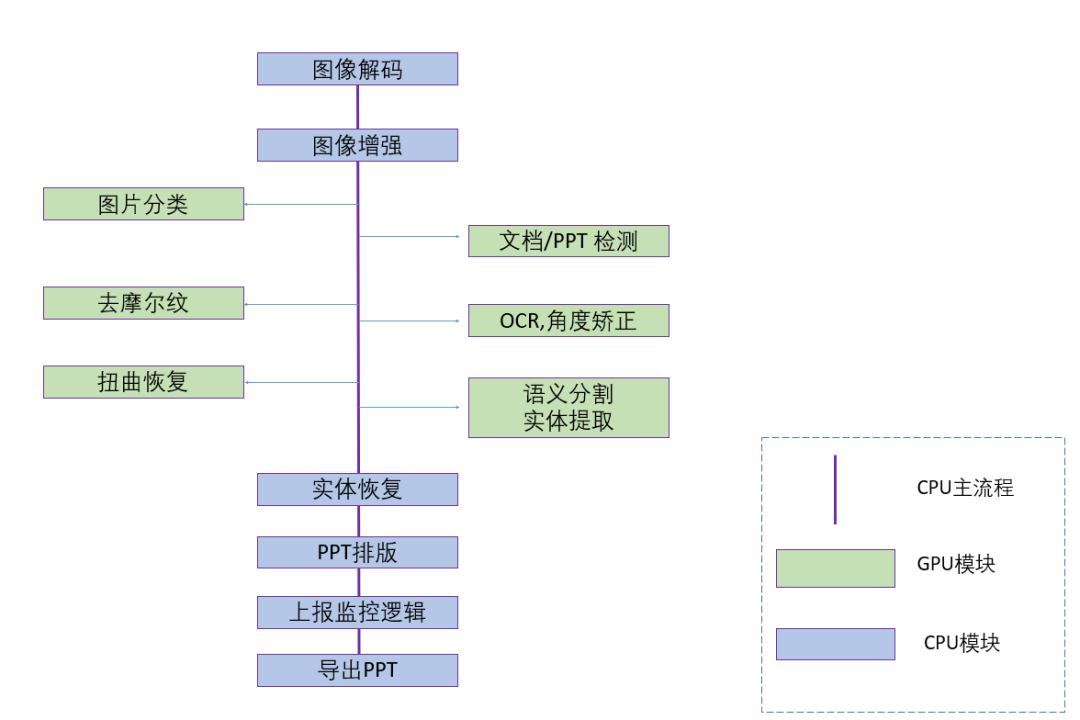
下面给大家一一介绍我们主要模块用到的技术细节。
二、AI 模块
2.1 自动框选
用户拍摄图片一般不会是工整图片,所以在进行提取前还需要做很多的预处理工作,其中最重要的一个模块就是先框选出真正我们需要转换的 PPT/文档内容。

对内容的框选现有很多技术,比如图像处理的边缘提取,但是效果不好需要特别多的后处理,随着 AI 的发展,也有一些深度学习的方法对边缘进行提取,比如 HED 网络。前期同事也基于 hed 进行了模型训练得到了不错的检测效果。使用的框架图如下图:
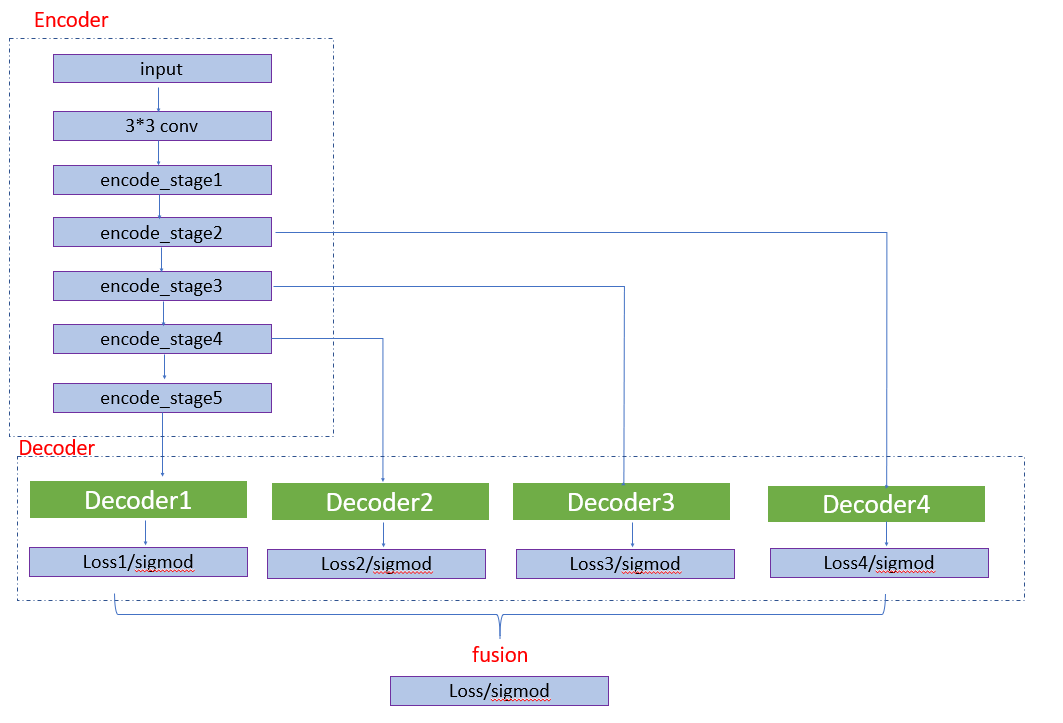
其中 Decoder1 分支的简易图如下:
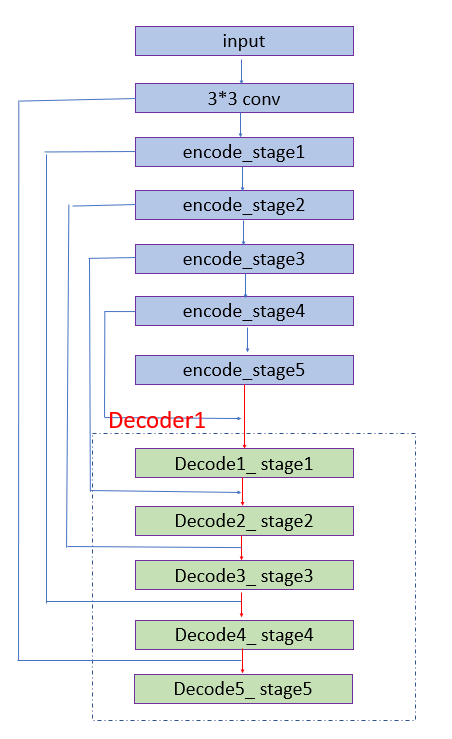
经过 HED 处理后在工程的后处理还是需要很多规则判断,特别在候选框选取时添加过多规则,如下图。所以我们需要进一步对模型进行优化减免后处理的繁杂工作以及优化框选准确性。
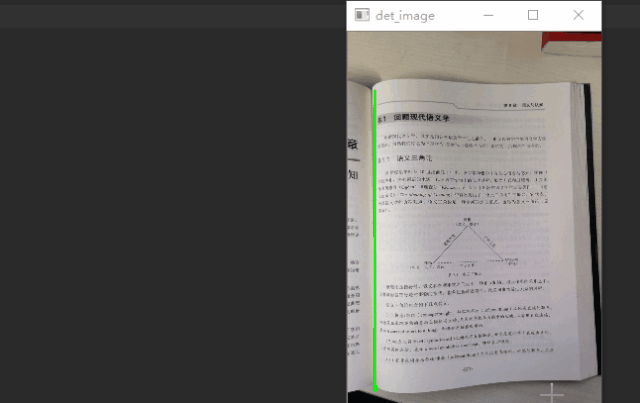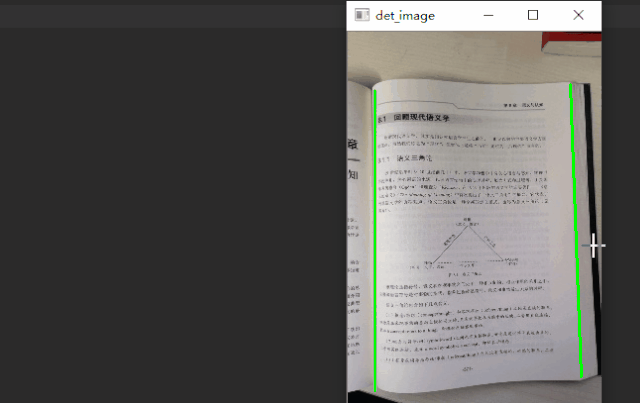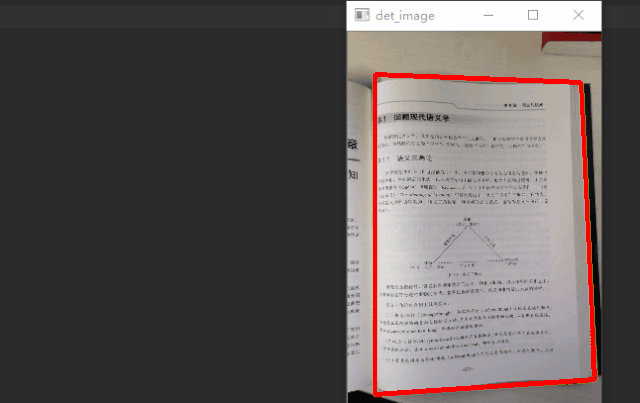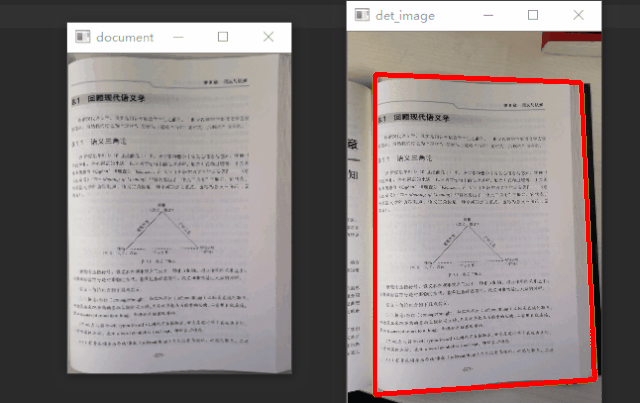
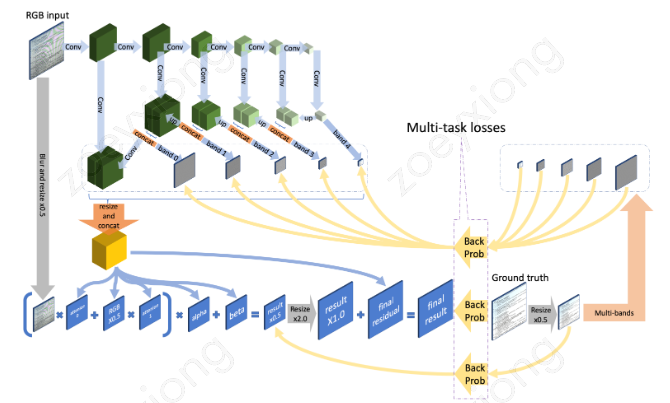
通过 case 分析,我们预测的选框通常会多出背景区域,如果通过语义分析知道大致的文档内容区域,再通过边缘线条检测准确的边框信息,融合信息是否能得到更精确的选框。所以在原有基础上增加了一个分割分支,多任务学习,在 decoder 模块分出两个分支,一个分支学习图像的边缘信息,一个分支学习图像的语义信息,如下图所示。
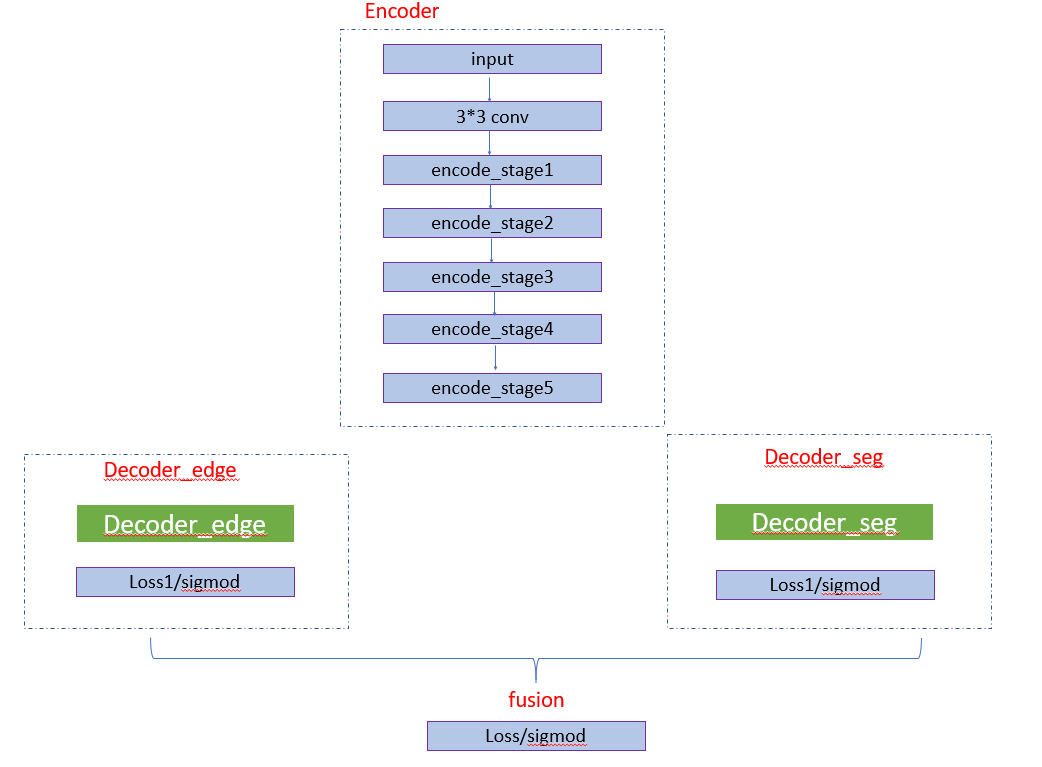
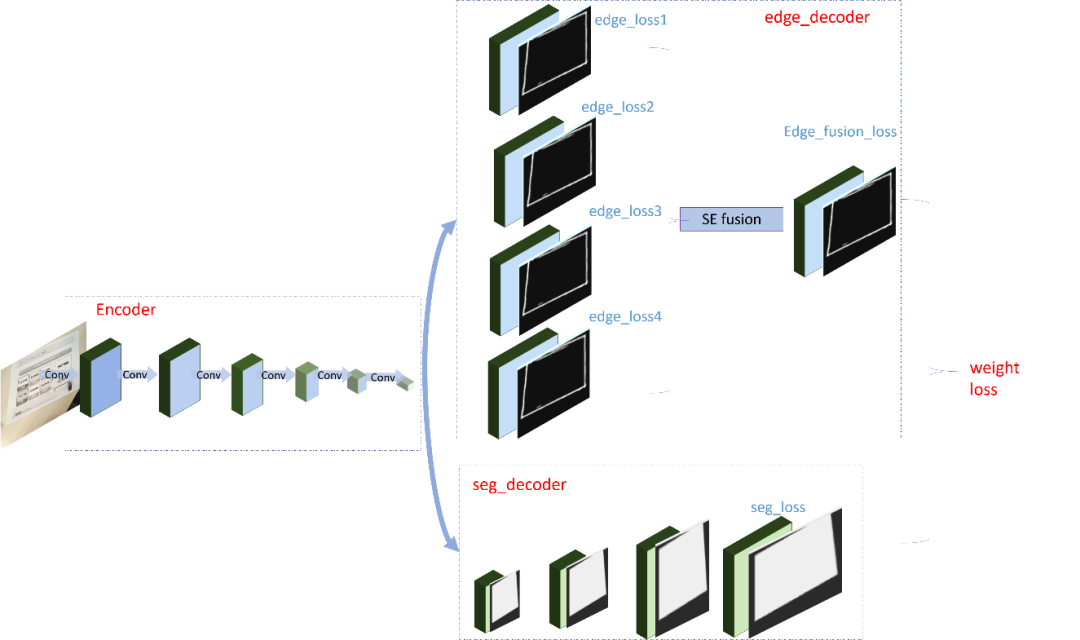
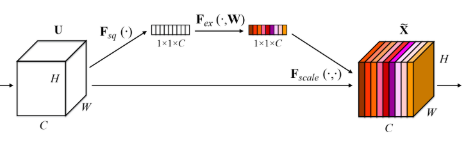
两个分支的 encoder 部分卷积层权重共享。在边缘检测分支,我们还是分为多个 block 计算 loss,并通过 se 模块融合分支。对于边缘检测,我们更多想得到全局信息,所以引入了 SEblock,如下图,在 featrueMap 上做了一次 attention。
在语义分割分支,我们采用通过的 Unet 结构。最终加权两个分支的 loss 进行训练。在训练过程中,我们的数据来源于仿真和真实数据的标注,另一部分来源于半监督方式通过检测分支的结果获取到文档内容从而得到分割 mask。在 infer 过程中,检测分支获取得到所有可能组成的四边形,和分割分支的结果计算 Miou,选择 miou 最大的检测框作为最终框选对象。
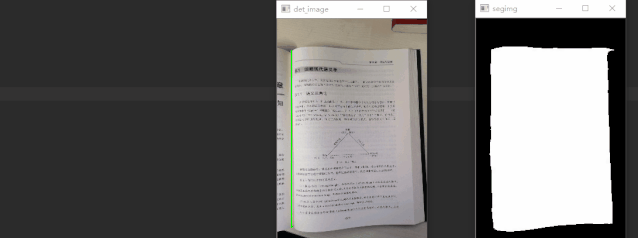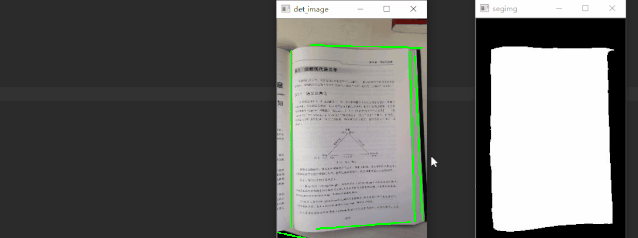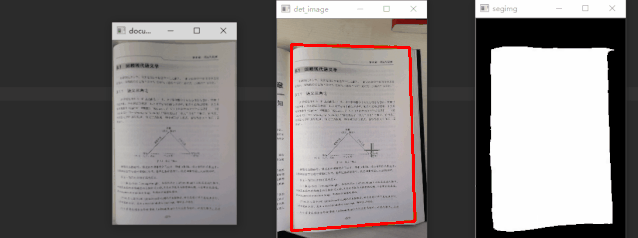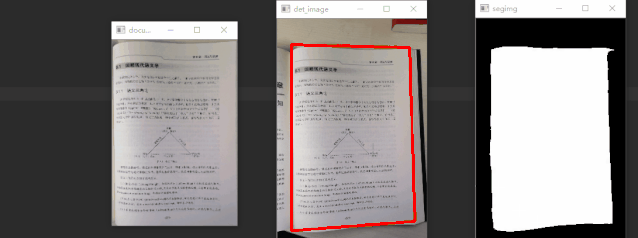
通过对比可以发现,语义分割分支可以得到更精准的检测框。


通过验证集验证,hed 验证集 miou=88.38,多任务网络 miou=90.63,多任务训练的方式 miou 可以提升 2 个点。
2.2 图像矫正
检测到 PPT 文档内容后,我们还需要对图像质量进行提升后再进行后续处理,希望转换后的文件还原度更高。针对图片矫正我们主要做了,去摩尔纹,文档旋转矫正和扭曲恢复。
2.2.1 去摩尔纹
对于屏幕拍摄图片,摩尔纹很影响我们后续处理的图像质量,所以检测到图片后我们首先通过小的分类模型判断是否需要对摩尔纹进行处理,如果属于屏幕拍摄场景会调用去摩尔纹模块。去除摩尔纹的网络框架和效果图如下:

2.2.2 扭曲恢复
检测出四边形后,通过投影变换可以对图片进行一步矫正,但是对于扭曲图像,仅仅通过图像处理是不够的,我们通过扭曲恢复模型,对图片扭曲恢复。这一步骤对于纸质的 PPT 拍摄以及文档拍摄图片比较重要。扭曲恢复的网络框架和效果图:
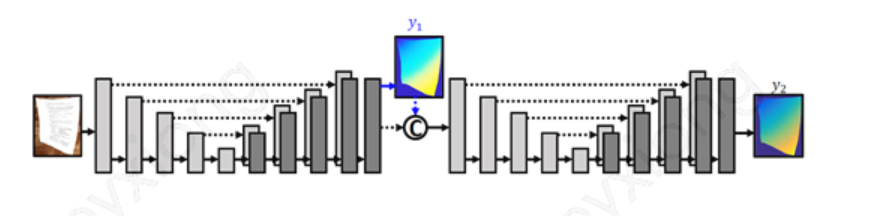

扭曲网络借鉴了 Document Image Unwarping via A Stacked U-Net 论文思路,近期也做了比较大的优化,主要通过将曲线拟合算法结合到网络结构解决了扭曲恢复后的文字在空间上存在细微抖动的问题,后续我们也会公开这块的技术细节。
2.2.3 文本旋转
OCR 也是我们重建的一个重要模块,除了能够提取图片中的文字信息,还有一个作用是可以通过文本检测框获取到图片中文本的旋转角度。但是目前 OCR 对于角度的预测在-45---45 角度之间比较准确,对于 90 度,180 度的旋转图片,预判角度不太准确。我们采用的方案是首先通过小的分类模型预测图片的象限方向,分类类别为[0,90,180,270]。先把图片旋转到-45~45 之间。再通过 OCR 预测角度讲图片旋转到 0 度。效果如下图:

左图为原图,中图为判断需要旋转 180 度,右图为通过 OCR 预测角度旋转后图片。
2.3 实体提取
通过以上步骤,我们可以获取到比较干净工整的 PPT 内容图片,这一步我们要通过语义分割,检测到图片的实体部分,方面后续生成 PPT。本模块在图片转 word 和图片转 excel 中都需要的模块。对于 PPT 图片,我们主要分割的类别为文本,图片,表格,背景。下图为标注的语义分割类别示意图。

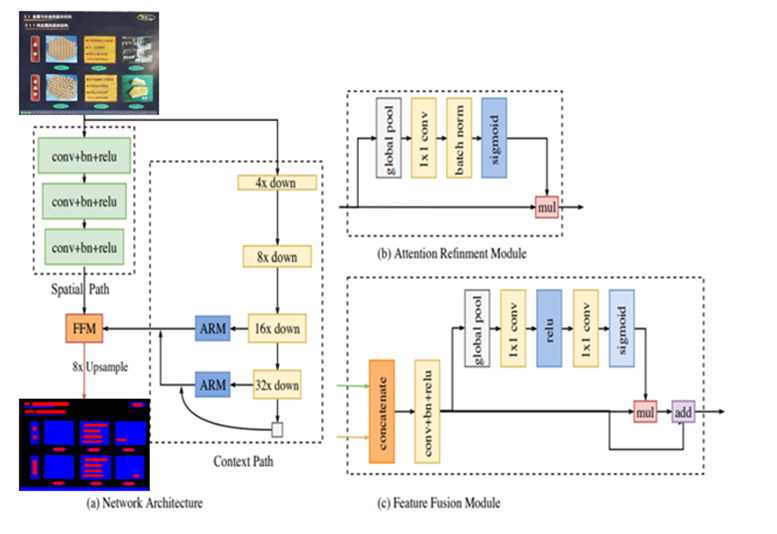
对于主流框架和基础网络,我们使用 PPT 的分割数据做了一些实验对比

从基础网络上看,shufflenet 速度更快,resnet 效果更好。网络结构上从性能上分析 bisenet 性价比更好。我们在项目中使用的是 Bisenet 框架,在学习特征时并行两条支路,一条学习空间细节信息,一条支路学习高层语义信息,然后将学到的信息融合,能够更好学习到全局信息和局部信息特征信息。
2.4 实体恢复
在上一步我们已经知道图片中哪块区域是文本,图片,表格,但是直接插入到 PPT 中会存在很多问题,比如图片中还嵌有文本的处理,文本框直接插入的背景问题等。我们重要介绍文字和背景的恢复。
2.4.1 文本恢复
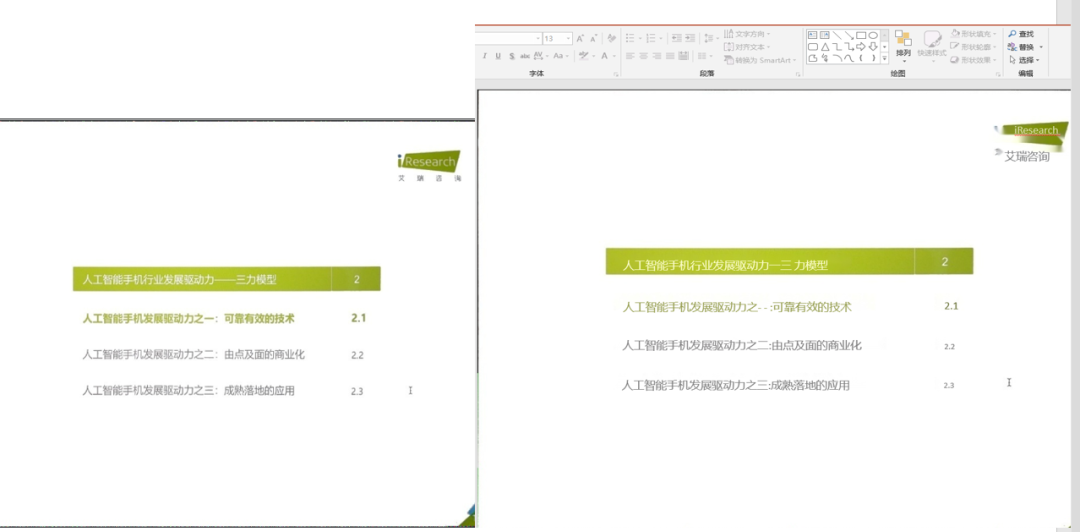
通过实体分割文本段以及 OCR 提取后,可以获取到文本框信息。如图 17,左图为原图,右图红框为我们获取到的文本区域,但是无法直接获取到字体颜色。

得到文本框后,字体颜色恢复步骤为:
-
截取文本框区域,如图 18(a) -
对文本框区域自适应二值化得到前景背景,如图 18(b) -
前景颜色区域计算均值得到前景和背景颜色值,如图 18(b)上前景像素区域对应的 a 点像素值 rgb 计算均值,设置为字体颜色。 -
图 18(a)的文本块区域,背景颜色为 RGB([73.,192.,179]);前景颜色 RGB ( [207, 255,255]) -
图 18(c)的文本块区域,背景颜色为 RGB([229,250,245]);前景颜色 RGB ( [78,156,149])

得到了字体大小和颜色恢复,结合之前的背景重建,我们可以得到最终的还原效果,字体几乎完全还原,如图 19 所示:
2.4.2 背景恢复
通过语义分割模型后,我们可以获取到前景所有实体,和剩下的背景区域。通过实体抽取直接在画布上进行插入,效果如图 20。
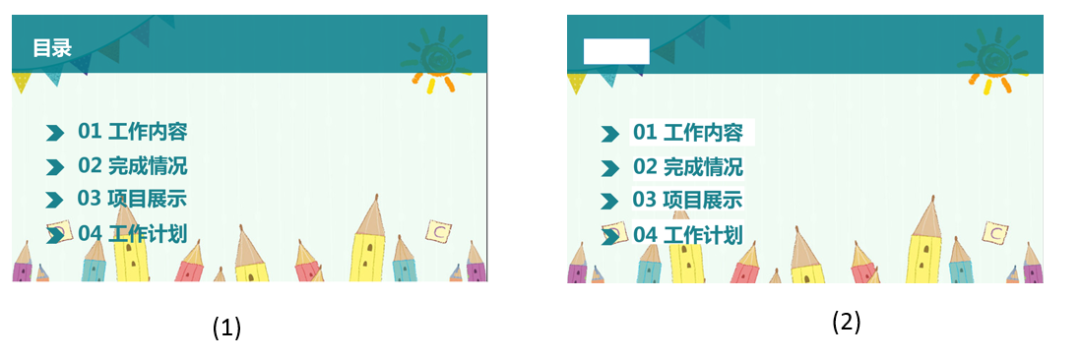
直接插入效果可以看出,在文本区域块和周围其他背景颜色差别太多,过度显得特别突兀,而且如果插入文本框颜色和文字颜色一致会导致文本看不清。所以我们需要通过 inpainting 算法,对背景进行重建。重建背景,图片,文字,表格,包括图片上的文字后就可以生成 PPT 了。
2.5 生成 PPT
通过以上步骤我们得到了各个实体模块,并且对每个模块进行了恢复重建。通过语义分割模块,可以获取到各实体(表格,图片,文本,背景)的相对坐标位置。通过重建模块,可以获取:
-
表格:表格的样式,行列数,单元格内文字内容 -
图片:图片抹除文字区域后,通过 impainting 重建图片内容 -
文本:文本区域的字体颜色,字体大小 -
背景:抹除前景区域后,通过 inpainting 重建背景内容
最后可以按照 office open xml 的格式在画布上依次插入背景,表格,图片,文字实体,得到最终的可编辑.ppt 格式。腾讯文档通过 http 请求获取到.ppt 格式文件后再转化为腾讯文档在线电子文档形式展示。
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:OCR-小极-北大-深圳),即可申请加入极市OCR技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~





