OCR大突破:Facebook推出大规模图像文字检测识别系统——Rosetta
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | Fedor Borisyuk,Albert Gordo,Viswanath Sivakumar
来源 | AI科技大本营(公众号ID:rgznai100)
【导读】OCR(Optical Character Recognition),也称光学字符识别,是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入的一种技术。其实大家都在应用这项技术——快递单号的扫描识别、火车票的验证等等。最近,Facebook 研究人员提出了一个大规模图像文本提取和识别系统——Rosetta。本文将为大家解读一下这个 OCR 界的最新神器。

摘要
在本文中,我们提出了一个可部署、可扩展的光学字符识别 (OCR) 系统,称之为 Rosetta,用于处理 Facebook 上每天上传的图片。对于 Facebook 这样社交网络中的互联网用户而言,通过图像内容共享实现对图像及其包含文字的理解,已经成为信息沟通的一种主要方式,这对促进搜索和推荐应用来说也是至关重要的。这里, 我们提出 Rosetta 系统结构,这是一种有效的建模技术用于检测和识别图像中的文本。通过进行大量的评估实验,我们解释了这种实用系统是如何用于构建 OCR 系统,以及如何在系统的开发期间部署特定的组分。
简介
人们在 Facebook 等社交网络中的信息共享主要是通过一些视觉媒体,如图片和视频等。在过去的几年里,每天上传到社交媒体平台上的照片数量成倍增长,这对大量视觉信息的处理技术提出了挑战。图像理解的主要挑战之一是将有关图像中的文本信息检索出来,这也称为光学字符识别 (OCR),这是一个将电子图像中的字体,绘图或场景文本转化为机器编码文本的过程。从图像中获取这样的文本信息是非常重要的,这也能促进许多不同的现实应用,如图像搜索和推荐等。
在光学字符识别任务中,给定一张图像,我们的 OCR 系统能够正确地提取所覆盖或嵌入的文本图片。这种任务所面临的挑战主要是来自一些潜在的字体、语言、词典和其他语言变体,包括特殊的符号,非字典单词或图像中的 URL,email ID 等特定信息。此外,图像的质量往往也会随着自然场景图像中文字的出现而变化不同的背景。另一方面,社交网络上每天上传的图像数量都是庞大的,对于如此大量的图片进行处理也是目前这项任务所要面临的一大挑战。我们想要在图像上传的同时,实时地进行 OCR 处理,这需要我们花费大量的时间对系统的组件进行优化。
总的说来,我们希望建立一个强大而准确的 OCR 系统,来实时处理每天上传的数亿张图像。本文,我们提出一种可扩展的 OCR 系统 Rosetta,为 Facebook 日常网络社交提供支持。我们的 OCR 系统分为文本检测和文本识别两个阶段:基于 Faster-RCNN 模型,在文本检测阶段我们的系统能够检测出图像内包含文本的区域;采用基于全卷积网络的字符识别模型,在文本识别阶段我们的系统能够处理检测到的位置并识别出文本的内容。下图1展示了 Rosetta 系统的检测识别效果。

图1 使用 Rosetta 系统进行 OCR 文本识别。首先,基于 Faster-RCNN 模型检测出单词的位置,并采用全卷积模型生成每个单词的转路信息。
方法
我们的 OCR 系统 Rosetta 主要包含两个阶段:检测和识别阶段。在检测阶段,我们的系统能够检测出图像中可能包含文字的矩形区域。在识别阶段,我们对每个检测到的区域,使用全卷积神经网络模型,识别并转录该区域的单词,实现文本识别。两阶段的处理过程有几大好处,包括解耦训练处理、部署并更新检测和识别模型的能力,并行地运行文本识别,独立地支持不同语言的文本识别等。下图2详细说明我们系统的流程。
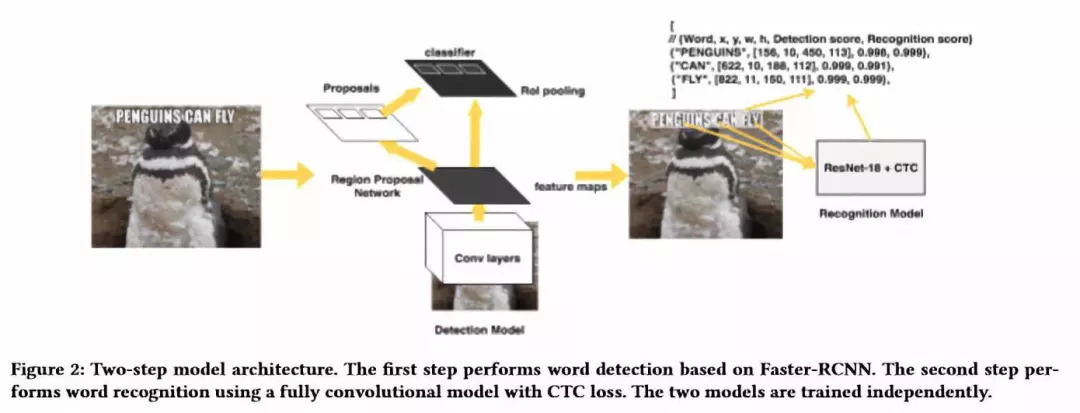
图2 两阶段模型的结构。第一阶段是基于 Faster-RCNN 模型进行单词检测。第二阶段使用具有 CTC 损失的全卷积模型进行单词识别。这两个模型是独立训练的。
▌ 文本检测模型
文本检测阶段,我们采用最先进的 Faster-RCNN 目标检测网络。简而言之,Faster-RCNN 通过一个全卷积神经网络和区域建议网络 (RPN) 同时实现目标的检测和识别:学习表征一张图像的卷积特征映射并生成 k 个高可能性的文本建议区域候选框及其置信度得分,随后按置信度分数排序这些候选框并利用非极大值抑制 (NMS) 算法得到最有希望的检测区域,再从候选框中提取相关的特征映射并学习一个分类器来识别它们。此外,边界框回归 (bounding-box regression) 通常用于提高边界框生成的准确性。
考虑到模型效率的问题,我们的文本检测模型采用基于 ShuffleNet 结构的 Faster-RCNN 模型,而 ShuffleNet 卷积结构是在 ImageNet 数据集上经过预训练得到的。整个文本检测系统是以监督式的,端到端的方式进行训练的。训练过程中,该检测系统采用内部合成的数据进行训练,并在 COCO-Text 数据集上进行微调后应用于学习真实世界数据集特征。了,
▌ 文本识别模型
文本识别阶段,我们尝试了以下两种不同的模型结构,并采用了不同的文本损失函数。
基于字符序列的编码模型 (CHAR)。该模型假设所有图像都具有相同的大小并且存在最大可识别字符数量 k。对于较长的单词,单词中只有 k 个字符能够被识别出。该 CHAR 模型的主体由一系列卷积结构组成,后接上 k 个独立的多类分类器,用于预测在每个位置上出现的字符。在训练期间,共同学习卷积体和 k 个不同的分类器。使用 k 个并行损失 (softmax + negative cross-entropy) 并提供合理的基线就能很容易地训练 CHAR 模型,但这有两个重大缺点:它无法正确识别长的单词串 (如 URL 地址),分类器中大量的参数容易导致模型出现过拟合现象。
基于全卷积模型。我们将此模型称为 CTC,因为它使用 seq2seq 的CTC损失函数用于模型的训练,并输出一系列字符。CTC 模型的结构示意图如下图3所示,基于 ResNet-18 结构,在最后一层的卷积中预测输入字符在每个图像中最可能的位置。与其他工作不同的是,我们在此不使用显式循环神经网络结构 (如 LSTM 或 GRU) 或任何的注意力机制,而直接生成每个字符的概率。训练时,我们采用 CTC 损失函数,通过边缘化所有可能对齐的路径集合来计算给定标签的条件概率,这就能够使用动态编程进行有效地计算。 如图3所示,特征映射的每一列对应于图像每个位置所有字符的概率分布,CTC 能够找到它们之间的对齐预测,即可能包含重复的字符或空白字符 (-)和真实标签。
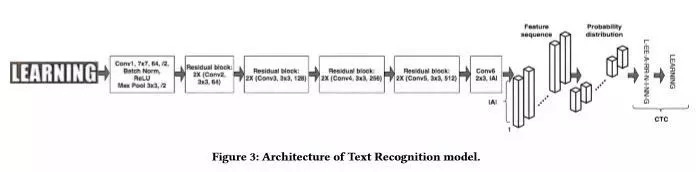
图3 文本识别模型的结构
▌ Rosetta 系统
下图4展示了 Rosetta 的系统结构,其在线图片处理的流程主要包含以下几个步骤:
Rosetta 将客户端的图片下载到本地计算机集群,并通过预处理步骤,如调整大小和规范化来进一步处理。
执行文本检测模型 (图4中的步骤4) 获取图像中所有单词的位置信息 (边界框坐标和置信度分数)。
将单词的位置信息传递给文本识别模型 (图4中的步骤5),用于提取图像给定裁剪区域的单词字符。
所提取的文本信息及图像中文本的位置信息都被存储在 TAO 中,这是 Facebook 的一个分布式图形数据库 (图4中的步骤6)。
诸如图片搜索等下游应用程序可以从 TAO 中访问所提取的图像文本信息 (图4中的步骤7)。
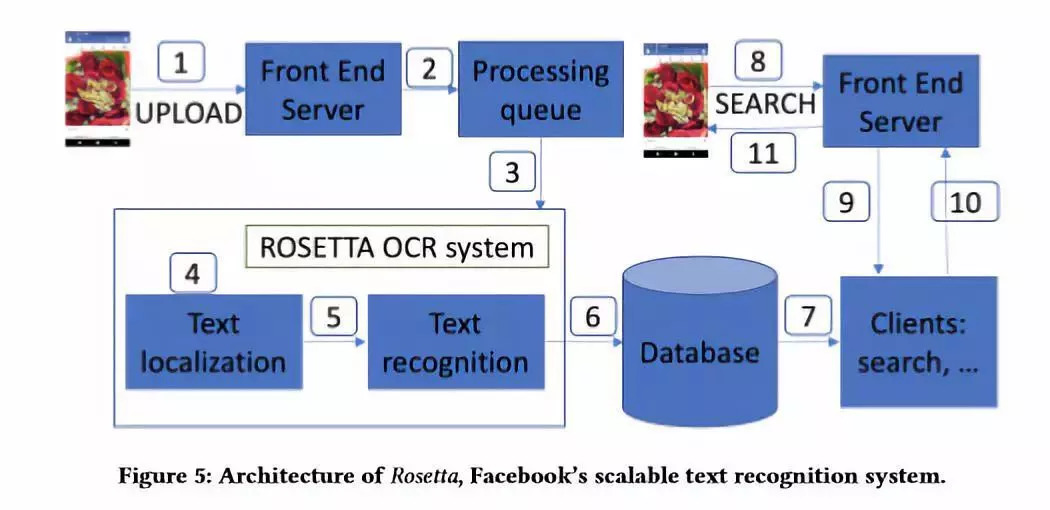
图4 Rosetta 系统结构,这是 Facebook 的可扩展的文本识别系统。
实验
我们对 Rosetta OCR 系统进行了大量的评估实验。首先,我们定义用于评估准确性和系统处理时间的度量,并描述用于训练和评估的数据集。我们在单独的数据集上进行保准的模型训练和评估过程。进一步,我们评估文本检测和文本识别模型,以及系统准确性和运行时间之间的权衡。
▌ 评估度量
对于文本检测模型,我们采用 mAP 和 IoU 作为评估度量。而对于文本识别模型,我们使用 accuracy 和 Levenshtein’s edit distance 作为我们的评估指标。
▌ 数据库
我们采用 COCO-Text 数据集对我们的模型进行训练和测试。COCO-Text 数据集包含大量自然场景下注释的文字,由超过63000张图片和145000文本实例组成。为了解决 COCO-Text 数据与 Facebook 上图片数据分布不匹配的问题,我们还通过随机重叠 Facebook 中图像的文本来生成了一个大规模的合成数据集。
▌ 模型检测性能
下表1,表2,表3分别展示了 Faster-RCNN 检测模型在不同数据测试集上的的检测性能,不同卷积主体结构的推理时间,以及 ResNet-18 和 ShuffleNet 为卷积主体的检测性能。
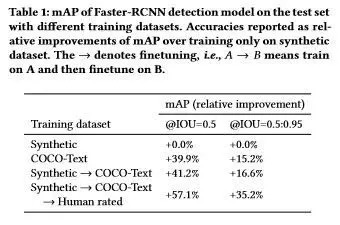
表1 在不同数据测试集上 Faster-RCNN 检测模型的mAP。准确性是 mAP 在合成训练数据集上的相对改进。→表示微调,即 A→B 表示在 A 上训练并在 B 上微调。
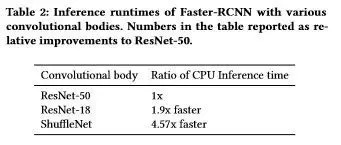
表2 以各种卷积结构为主体的 Faster-RCNN 模型的推理时间。表中的数字为相对于 ResNet-50 的改进。
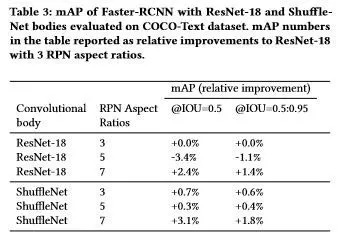
表3 使用 ResNet-18 和 Shuffle 结构的 Faster R-CNN 在 COCO-Text 数据集上评估结果。表格中的 mAP 是对 ResNet-18 的 3个RPN 宽高比的相对改进。
▌ 模型识别性能
下表4,表5分别展示了在不同数据集上模型的识别性能以及结合检测和识别系统检测到的词召回率下降的归一化幅度。
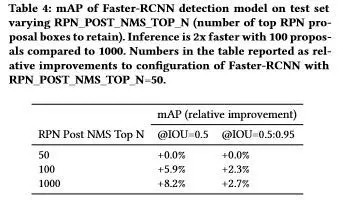
表4不同数据集上模型的识别性能。越高的 accuracy 和越低的 edit distance 代表越好的结果。表中的数字是相对于在合成数据集上训练的 CHAR 模型的改进。
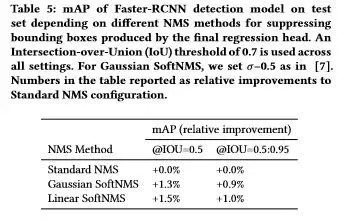
表5 检测和识别组合系统检测到词召回率下降的归一化幅度
结论
本文,我们提出了鲁棒而有效的文本检测和识别模型,并用于构建可扩展的 OCR 系统 Rosetta。我们对 Rosetta 系统进行了大量的评估,结果展示系统在权衡模型精度和处理时间方面都能实现高效率的性能。进一步地,我们的系统将部署到实际生产中并用于处理 Facebook 用户每天上传的图片。
原文链接:
http://delivery.acm.org/10.1145/3220000/3219861/p71-borisyuk.pdf?ip=211.103.135.162&id=3219861&acc=OPEN&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E6D218144511F3437&__acm__=1535625033_0d5caf858af000c0791835439d2604a5
ECCV2018收录论文已开放并支持pdf下载,感谢极市cv交流群小伙伴的整理,在“极市平台”公众号后台回复“ECCV”,即可获取全部论文pdf网盘下载链接~
*推荐文章*
ICPR 图像识别与检测挑战赛冠军方案出炉,基于偏旁部首来识别 Duang 字
华科白翔老师团队ECCV2018 OCR论文:Mask TextSpotter
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~



