AI一周热闻:寒武纪完成B轮融资;美恢复中兴制裁令;FAIR开源DensePose

AI 前线导读:
寒武纪完成数亿美元 B 轮融资,估值 25 亿美元
FAIR 开源 2D 变 3D 人体模型应用 DensePose
美参议院恢复中兴制裁,中美贸易战火重燃
沃尔沃自动驾驶投资激光雷达公司 Luminar
百度提出 NCRF,提升肿瘤图像准确率
AI 自动生成钓鱼网址
A2C + SIL 完胜所有 A3C + 测试
是的,AI 开始影响经济了
神经网络可以比你想象的更像大脑
无监督元学习:不用指导,就知道如何学习
更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
6 月 20 日,寒武纪宣布完成数亿美元 B 轮融资,投后整体估值达 25 亿美元。
本轮融资由中国国有资本风险投资基金、国新启迪、国投创业、国新资本联合领投,中金资本、中信证券投资 & 金石投资、TCL 资本、中科院科技成果转化基金跟投,原股东元禾原点、国科投资、阿里巴巴创新投、联想创投、中科图灵继续跟投支持。
今年五月,寒武纪发布了第三代机器学习终端处理器 1M,其性能比此前发布的寒武纪 1A 高 10 倍。配置方面,寒武纪 1M 使用台积电 7nm 工艺生产,其 8 位运算效能比达 5 Tops/watt(每瓦 5 万亿次运算)。寒武纪提供了 2Tops、4Tops、8Tops 三种尺寸的处理器内核,以满足不同场景下不同量级智能处理的需求。寒武纪 1M 处理器除了与上两代芯片一样支持 CNN、RNN、SOM 等多种深度学习模型,还增加了 SVM、k-NN、k-Means、决策树等经典机器学习算法的加速。

6 月 18 日,Facebook AI 研究院(FAIR)开源了 DensePose,这是一个能将人体所有像素的 2D RGB 图像实时映射到 3D 人体模型的应用。
这一模型利用 COCO 数据集中 50K 张密集型人体对应关系的标注,并在有遮挡和尺度变换等自然情况下能准确实现密集型人体姿态估计。DensePose 能够以基于表面的模型来理解图像中的人物,揭示人体自讨的更多信息。
原文连接:https://research.fb.com/facebook-open-sources-densepose/
GitHub 地址:https://github.com/facebookresearch/DensePose

当地时间 6 月 18 日,美国参议院通过国防授权法案,其中包括以 85-10 通过恢复制裁中兴通讯的两党修正案,驳回了特朗普的命令。北京时间 6 月 19 日开盘,中兴通讯下跌 10%,继续成为表现最差个股,当天沪深 300 指数盘前下跌 1.4%。中兴自 6 月 13 日复牌以来,仅仅 4 个交易日股价就下跌了 34%。
在端午节期间,中美再度燃起新一轮贸易战火。6 月 15 日,美国决定对中国价值 500 亿美元的输美产品征收 25% 的关税。同日,中国商务部回应称,美方此举是置双方已经形成的共识于不顾,双方此前磋商达成的所有经贸成果将同时失效。随后,北京时间 6 月 16 日,中国国务院关税税则委员会发布公告,决定对原产于美国的 659 项约 500 亿美元进口商品加征 25% 的关税。

瑞典车企沃尔沃通过旗下的风投基金对激光雷达创业公司 Luminar 进行战略投资。
根据 Luminar CEO Austin Russell 的说法,其与沃尔沃的合作已经取得了实质性的进展。这位 CEO 还表示,除了沃尔沃和丰田,Luminar 还在与其他两家车企进行合作,但并未透露这两家车企名称。
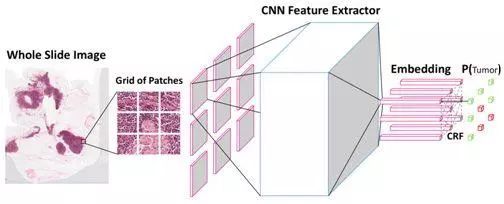
近日,百度研究人员提出了 NCRF(神经条件随机场)方法,在提升肿瘤图像准确率的同时也减少了假阳性的出现几率。
目前,人们已经提出了各种基于深度学习的算法来帮助病理学家有效审查病理学切片,并检测癌症转移。但由于现有方法有时难以在不知晓周围内容的情况下预测小图片中是否存在肿瘤,特别是在肿瘤 / 正常区域的边界上,经常会出现假阳性。
而百度研究人员近日提出的的深度学习算法不仅可以分析单个小图片,也将图片四周临近的网格一并输入进行肿瘤细胞分析,因此提高肿瘤图像准确率,减少假阳性的出现几率。
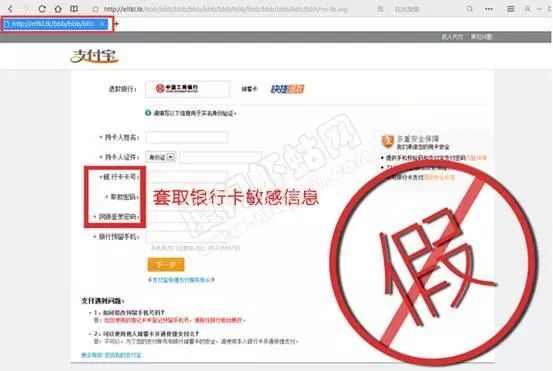
AI 是一种全方位的技术,因此用于识别钓鱼网址的技术也可用于生成钓鱼网址。Cyxtera Technologies 的网络安全分析部门研究人员通过创建自己的 DeepPhish 系统,分析了人们如何“使用 AI 算法躲避 AI 网络钓鱼检测系统”。DeepPhis 通过收集过去成功达到欺诈目的的 URL 列表,将它们编码为单一表示,然后训练模型以生成新的合成 URL,并给出种子句。他们发现 DeepPhish 可以显著提高欺诈 URL 通过自动钓鱼检测系统的几率,DeepPhish URL 的有效性从 0.69%(无 DeepPhish)提高到 20.90%(DeepPhish)。而且,DeepPhis 不是最近由研究人员开发的唯一 AI“武器”系统,还包括其他工具 Honey-Phish、SNAP_R 和 Deep DGA。
阅读更多:
DeepPhish:恶意造假 AI (https://albahnsen.com/2018/06/03/deepphish-simulating-malicious-ai/)。
自我模仿学习(SIL,Self-Imitation Learning)通过让代理重复自己先前产生了合理回报(只有当产生大量超出预期的回报时才起作用)的行为来学习。作者将 SIL 与评价器演算法(A2C,Advantage Actor-Critic )结合起来,通过各种艰巨任务进行测试,其中包括难度非常高的 Atari 探索游戏Montezuma's Revenge。结果显示:A2C + SIL 的方法完败所有 A3C + 测试。总体而言,AC2+SIL 在整个 Atari 中的得分为 138.7%,而 A2C 为 96.1%。
此外,他们还在 OpenAI Gym 内部模拟机器人任务上测试了 PPO+SIL 的组合,并显著提高了非 SIL 测试的性能。
值得注意的是,自 A2C 以来,其他许多算法和系统都在 Atari 上表现出色,所以这里所用的比较度量是否合理还存疑。
我们需要设计出可以更智能探测环境的 AI 算法。这项工作进一步证明了开发更复杂的探测技术可以进一步提高性能。然而,正如报告所指出的那样,这样的系统仍然会陷入局部最不利的状态。作者写道:“我们的研究结果表明,在一定的学习阶段,开发比探索更重要,反之亦然。”“我们认为,在收集和从经验中学习这方面寻求开发和探索之间平衡的方法,将是未来重要的研究方向。”
经济顾问委员会前任主席,哈佛肯尼迪学院现任教授 Jason Furman 和纽约大学斯特恩商学院的 Robert Seamans 发表了关于人工智能和经济的长篇报告。该报告汇集了来自各种来源的信息,因此值得全文阅读。

以下是报告中引用的一部分 AI 影响经济的事实:
26 倍:从 2015 年到 2017 年,与人工智能相关的并购增加。(来源:经济学人)。
26%:从 2010 年到 2017 年,ImageNet top-5 图像识别错误率实际下降。(来源:AI 指数。)
9X:从 1996 年到现在,专注于 AI 的学术论文数量增加,而计算机科学论文增加 6 倍。 (来源:AI 指数。)
40%:从 2013 年到 2016 年,AI 创业公司的风险投资实际增长(来源:MGI 报告)。
83%:每小时支付 20 美元左右的工作将受自动化影响的概率(来源:CEA)。
-
4%:每小时工资超过 40 美元的工作将受自动化影响的概率(来源:CEA)。
他们在报告结论中写道:“人工智能具有显著改变经济的潜力。 “早期的研究结果表明,人工智能和机器人确实能够提高生产力的增长,而对劳动力的影响则参差不齐。然而,为了证实现有的生产力效益研究结果,我们需要更多的实证研究,以更好地理解人工智能和机器人替代或补充劳动力的条件,并了解区域之间的差异。“
了解更多:AI 和经济(SSRN,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3186591)。

哈佛大学和麻省理工学院研究人员分析了 PredNet,一个被训练在视频序列中执行下一帧预测的神经网络,以了解它的行为与大脑的相似度。当它们暴露在输入中时,其某些神经元的响应模式(由两个不同的峰值组成)与短尾猴的单个神经元发放模式相似。类似地,当分析在自动驾驶 Kittie 数据集上训练的网络对空间的接受性时,他们发现人工网络显示出与真实网络类似的动态(虽然有一些差异和错误)。在序列学习任务上训练的系统中,人造神经元和真实神经元的行为之间重叠程度也相当高。而重叠较少的部分多与直观上较难的任务相关,如能够处理视错觉,或系统对不同类别对象的反应。
我们现在越来越多地用仿真系统来更好地理解其工作原理。 PredNet 证明了这一系列的实验可以发挥作用。“这一简单的客观预测就可以产生如此多种多样的可观察神经现象,这强调了预测可能是大脑中的一个中心组织原则,并为神经科学和机器学习的未来研究指明了方向。 ” 阅读更多:训练预测未来视频帧的神经网络模仿生物神经元反应和感知的关键特性(https://arxiv.org/abs/1805.10734)。
阅读更多:PredNet(CoxLab,https://coxlab.github.io/prednet/)。
加州大学伯克利分校的研究人员发现的新型“无监督元学习”(ULM)方法,使得元学习代理能够自动获取随后可以进行元学习的任务分配,减少了研究人员建立元学习系统的工作量,从而使得元学习更易于处理。这克服了元学习的一个缺点,即通常是由人类设计师来为算法提供一组任务以进行训练。他们还展示了如何将 ULM 与其他最近开发的技术,如 DIAYN 结合起来,将环境分解成不同任务 / 状态的集合以进行训练。
结果显示,在模拟的 2D 导航和运动任务中,UML 系统击败了基本的 RL 测试,且表现逼近人为设计的调优奖励函数构建的系统性能,这表明 UML 可以成功探索空间问题,并为自己设计出良好的奖励信号。
我们希望 AI 做的任务的多样性要比我们可以通过手写规则指定的任务多得多,所以开发出可以快速从新环境获取信息并使用这些信息解决新问题的方法至关重要。元学习有望解决这个问题,而 UML 有助于推动事情的进展。研究人员写道:“在未来,一个有趣的研究方向是将无监督元学习扩展到监督分类等领域,这可能有望开发出元学习为基础的新型无监督学习程序。”
阅读更多:无监督元学习强化学习(https://arxiv.org/abs/1806.04640)。
原文链接:https://jack-clark.net/
作者 Jack Clark 有话对 AI 前线读者说:我们对中国的无人机研究非常感兴趣,如果你想要在我们的周报里看到更多有趣的内容,请发送邮件至:jack@jack-clark.net。


如果你希望看到更多类似优质报道,记得点个赞再走!



