吴恩达《ML Yearning》| 端到端的深度学习
简介
MachineLearning YearningSharing 是北京科技大学“机器学习研讨小组”旗下的文献翻译项目,其原文由Deep Learning.ai 公司的吴恩达博士进行撰写。本部分文献翻译工作旨在研讨小组内部交流,内容原创为吴恩达博士,学习小组成员只对文献内容进行翻译,对于翻译有误的部分,欢迎大家提出。欢迎大家一起努力学习、提高,共同进步!
致谢
Deep Learning.ai公司
吴恩达(原文撰稿人)
陆顺(1-5章)
梁爽(6-10章)
郑烨(11-15章)
吴晨瑶(16-20章)
玉岩(21-25章)
陈波昊(25-30章)
翟昊(31-35章)
高宏宇(36-40章)
丁韩旭(41-45章)
李汤睿(46-50章)
徐博文(51章及以后)
马聪 (整体汇总)
北京科技大学“机器学习研讨小组”
人工智能前沿学生论坛(FrontierForum of Artificial Intelligence)

第一部分:吴恩达《ML Yearning》| 关于开发集、测试集的搭建
第二部分:吴恩达《ML Yearning》| 基础的误差分析& 偏差、方差分析
第三部分:吴恩达《ML Yearning》| 关于学习曲线的分析&与人类级别的表现对比
第四部分:吴恩达《ML Yearning》| 在不同的数据分布上训练及测设&Debug的一些推断算法
47. 端到端学习的兴起
分享人:李汤睿
假设你现在需要建立一个系统,检测网友做出的评论,判断他说这个评论好还是烂爆了。
这种判断好坏评价的问题一般称为——情感识别,建造这个系统可以使用由两个部分的流水线结构:
一个标注文中关键词汇的系统;
一个赋予词汇情感的系统,给更重要的词更高的权重,能够减少分析不重要词的时间。
我们可以把这个流水线结构看成以下图片所示的情况:

然而最近使用一个完整的结构,而不是流水线结构的方式越来越流行。人们常说的端到端模型(end-to-end)是将解决问题需要的最原始输入直接输入进去,在之前举出的例子中就像语音信息片段一样,然后通过模型直接得到输出所给出的转化结果。
神经网络模型被广泛地应用于端到端的学习结构,端到端的意思也就是直接从输入获得输出,端到端的模型直接联系了输入端和输出端。
在数据量丰富的课题中,端到端的模型十分有效,但是并不一直都是最好的选择,接下来几章的内容会告诉你什么时候该用什么时候不该用这种模型。
48. 关于端到端模型更多的信息
分享人:李汤睿
假如你想建立一个语音内容识别系统,你可能会建立一个由三个部分组成的系统,系统的各个组成部分如下:
电脑提取特征:提取像MFCC之类的人工设计的特征,尝试更多的关注说话的内容而不是一些说话者阐述时的音高等相对无关的内容;
声素识别器:一些语言学家相信声素是组成声音的最基本单元,比如说keep中的k就和cake中的c是有同一声素的,这个系统用来判断语音片段中的声素;
总判别器:按照顺序将所有的声素排列,并且将其转换为最终的输出;
但是如果使用端到端的模型,则会输入一个语音片段,尝试直接输出转换后的结果。
至今为止,我们认为流水线结构是输入从开始一步一步转换到下一个处理器中得到输出的。流水线结构某些情况下可以变得十分复杂,比如这里就有一个自动驾驶汽车的模型:
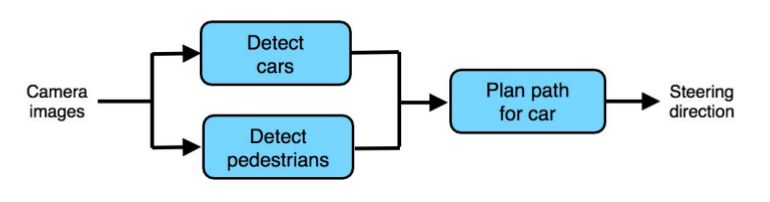
这里一共有三个部分:一个使用摄像头拍照检测其他的汽车,另一个检测行人,第三个模型检测会计算避开车辆和行人的路径。
这三个部分都没有说必须要使用机器学习,举个例子,机器人行动规划类似的课题中就有非常多不用学习的算法用来规划最后路径。
但是端的模型则需要使用输入训练得到正确的输出。
尽管端到端的模型有很多成功的先例,但是端到端的模型在某些模型下是没什么用的,尽管在说话识别上取得了不错的效果,但是端到端的模型能否在自动驾驶上取得成功非常依然有很大的疑问,接下来的几章会阐述为什么会这样。
49. 端到端模型中的好处和限制
分享人:李汤睿
考虑到之前所讲的流水线模型,很多部分都是人类的辛勤工作作为基础的,比如MFCC特征就是一组用依靠人设计的特征,尽管MFCC提供了非常合理的声音特征信息,但是也去除了一些辅助信息;声素则是语言学特有的概念,是表达说话的不好信息,因为声素只是现实情况的一种很有限的近似,如果算法仅仅关注声素则会降低整个算法的性能。
人工特征限制了识别系统的良好工作但是也并非一无是处,MFCC特征是一组十分健壮而且不会影响内容的特征,说话者的音高之类的多余特征会被直接忽略,这会在一定程度上简化信息,一般来说,人工特征能在一定程度上辅助电脑做出更好的决策。
加入人工信息允许机器系统使用更少的数据进行学习,MFCC和声素信息能够补充我们相对拮据的数据不能涵盖的东西,当我们没有足够的训练数据的时候会相当宝贵。
现在把视角转换到端到端模型,这个模型压根没有人工特征,所以数据不够的时候这个模型的效果可能不如依赖人工特征的系统。
但是当数据量足够大的时候,不使用人工特征的坏处就消失了,如果数据集的质量相当高、量相当大,而且训练方式很好,那么这个模型的表现甚至可以达到最优。
端到端模型在拥有输入与输出已经标注配对,组成了输入-输出数据组合的情况下表现良好,在刚才的例子中,我们会需要大量的已经标注的语音片段组合来训练我们的模型。
但是当你处理数据量十分有限的机器学习问题时,更多的算法知识会来自于你作为人类的智慧与直觉,经由你设计的人工特征来体现。如果你选择不使用端到端模型,那么就会面临将问题分为多少个步骤,这些步骤如何拼接的问题。在接下来的几章中,我们会为流水线结构的设计提供一些建议。
50. 选择流水线结构要根据数据是否容易得到
分享人:李汤睿
当试图搭建一个非端到端模型的流水线结构模型,到底什么才是流水线结构最重要的部分?如何搭建流水线将会最大程度地影响其表现?其中一个重要的答案就是能否找到足够的数据来训练每一个部分。
就像我们之前提到的自动驾驶汽车模型一样。
你可以使用机器学习来检测车和行人,因为获得这种数据相当容易,网络上有相当多的关于车和行人而且已经标注的数据集合,你甚至可以使用Amazon提供的特殊服务来获得更大的数据集合,所以建立起一个车判别器和行人判别器相当简单。
但是相对的,如果直接训练一个端到端的模型,我们需要大量的数据,并且保持(车-行人-路径规划)的数据组合,获取这种数据就十分困难而且昂贵了,这就是的直接的端到端模型的难以训练之处,相比之下采用流水线的结构更加容易设计。
不失一般性,如果中间环节能够拿到足够多的训练数据,那么构建流水线结构可能会成为你的第一考虑,因为你合理的利用了所有的数据并且用在了正确的地方。
相比与端到端的模型,在自动驾驶这个问题上,流水线结构表现出了更加令人信服的效果,所以我们相信自动驾驶是一个非常适合使用流水线结构的问题,因为这个问题与数据采集问题相性良好。
51. 选择流水线的组件:任务简易性(Task simplicity)
分享人:徐博文
除了数据可用性之外,在选择流水线组件时还应该考虑的第二个点是,各个组件解决任务的简便性。你应该尽量选择易于构建或学习的流水线组件。但是,组件“易于学习”,这意味着什么呢?

考虑以下机器学习任务,它们的难度按递增的顺序列出: 1.分类图像是否过度曝光(如上面的例子) 2.分类图像是在室内拍摄还是在室外拍摄 3.分类图像是否包含猫 4.分类图像中是否有一只黑白毛色猫 5.分类图像是否包含暹罗猫(一种特殊品种的猫)
每一个任务都是一个图像的二分类任务:输入一幅图像,输出0或1。但是以上列表中越靠前的任务对于神经网络来说似乎更容易学习。也就是说,对于更简单的任务来说,训练需要的样本也更少。 在机器学习中,任务的“简单”和“困难”还没有一个很好的正式的定义。随着深度学习和多层神经网络的兴起,我们有时会说,如果一个任务可以用更少的计算步骤(对应于浅神经网络)来完成,那么它是“容易的”;如果它需要更多的计算步骤(需要更深的神经网络),那么它是“困难的”。但这些都是非正式的定义。
1. 信息论中的一个概念是“Kolmogor复杂度”,它说的是一个学习函数的复杂度是能产生这个函数的最短计算机程序的长度。然而,这一理论概念在人工智能领域的实际应用却很少。参见:https://en.wikipedia.org/wiki/Kolmogorov_complexity
如果你能够完成一项复杂的任务,并将其分解成更简单的子任务,然后通过明确地写出子任务的各个步骤,你就能给算法提供先验知识,帮助它更有效地学习。

假设你正在构建一个暹罗猫检测器。这是一个端到端的架构:

相比之下,你可以选择使用一个有两个步骤的流水线:

第一步(猫检测器)检测图像中的所有猫。

第二步将每个检测到的猫的图像裁剪出来,依次传递给一个猫品种分类器。若检测到的猫是暹罗猫则最后输出1。
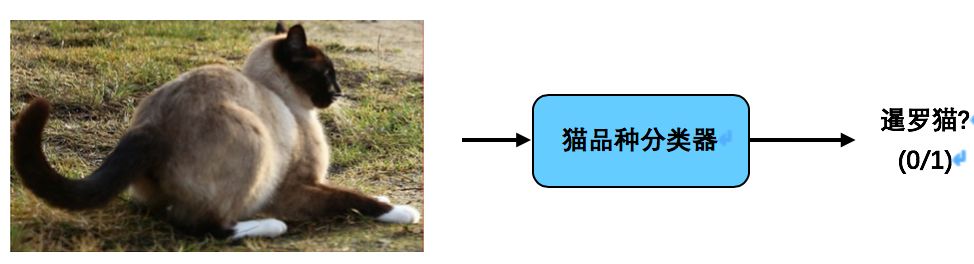
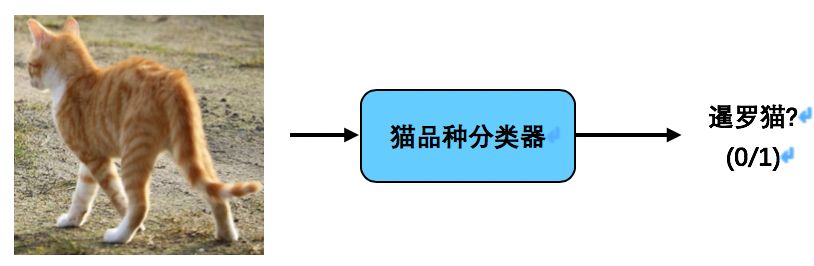
与只使用标签0/1训练的端到端分类器相比,流水线中的两个组件——猫检测器和猫品种分类器——似乎更容易学习,而且所需的数据也少得多。
2. 如果您熟悉实用的对象检测算法,那么你会明白,它们不仅仅是通过0/1图像标签学习,而是通过作为训练数据一部分提供的边界框进行训练。对它们的讨论超出了本章的范围。如果你想了解更多关于这类算法的信息,请参阅 Coursera ( http://deeplearning.ai 上的“深度学习专项课程”。 最后,举一个例子,回顾一下自动驾驶的流水线。
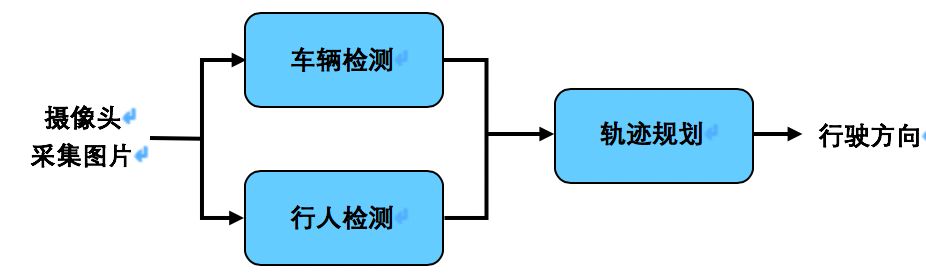
上面这样的流水线中,所使用的算法有三个关键的驾驶步骤:(1)检测其他车辆,(2)检测行人,(3)为你的汽车规划路径。此外,与端到端方法相比,其中的每一步都是一个相对简单的函数,因此可以用更少的数据来学习。
总之,在决定流水线的组件应该是什么时,我们可用尝试构建一个流水线,其中每个组件都是一个相对“简单”的函数,由此可从少量数据中学习。
52. 直接学习丰富的输出(rich outputs)
分享人:徐博文
图像分类算法中,输入是图像x,输出是表征对象类别的整数。算法能输出描述图像的完整句子吗? 例如:
传统的监督学习学到了函数h: X→Y,Y的输出通常是整数或实数。例如:

| 问题 | X | Y |
|---|---|---|
| 垃圾邮件分类 | 垃圾邮件/非垃圾邮件(0/1) | |
| 图像识别 | 图片 | 标签 |
| 房价预测 | 房子的特点 | 价格 |
| 产品推送 | 产品&用户的特点 | 购买的可能性 |
在端到端深度学习中最令人兴奋的进展之一是,它让我们能够直接学习比数字复杂得多的输出y。在上面的图像标题示例中,您可以让神经网络输入图像(x)并直接输出图像描述(y)。
再举一些例子:
| 问题 | X | Y | 引用自 |
|---|---|---|---|
| 图像描述 | 图片 | 文字 | Mao et al., 2014 |
| 机器翻译 | 英语 | 法语 | Suskever et at., 2014 |
| 问答系统 | (文本,问题) | 回答文本 | Bordes et al., 2015 |
| 语音识别 | 语音 | 转换结果 | Hannun et al., 2015 |
| 文字转语音(TTS) | 文本特征 | 音频 | Van der Oord et al., 2016 |
这是深度学习的一个趋势:若有正确的(输入,输出)标签对,你有时可以端到端学习,即使输出是一个句子,一个图像,一个音频,或其他输出,而不是简单的一个数字。
更多翻译内容,请关注后续文章
全文发出后将提供完整版下载链接
志愿者持续招募中,有意者联系微信号“AIDL小助手(ID:must-tech)”

历史文章推荐:




